Så här fungerar Azure Data Factory
Här lär du dig mer om komponenter och sammankopplade system i Azure Data Factory och hur de fungerar. Den här kunskapen bör hjälpa dig att avgöra hur du bäst kan använda Azure Data Factory för att uppfylla organisationens krav.
Azure Data Factory är en samling sammankopplade system som kombineras för att tillhandahålla en plattform för dataanalys från slutpunkt till slutpunkt. I den här lektionen får du lära dig mer om följande Azure Data Factory-funktioner:
- Ansluta och samla in
- Omvandla och berika
- Kontinuerlig integrering och leverans (CI/CD) och publicering
- Övervakning
Du får också lära dig mer om de här viktiga komponenterna i Azure Data Factory:
- Pipelines
- Aktiviteter
- Datauppsättningar
- Länkade tjänster
- Dataflöden
- Integreringskörningar
Azure Data Factory-funktioner
Azure Data Factory består av flera funktioner som kombineras för att ge dina datatekniker en komplett plattform för dataanalys.
Ansluta och samla in
Den första delen av processen är att samla in nödvändiga data från lämpliga datakällor. Dessa källor kan finnas på olika platser, inklusive lokala källor och i molnet. Data kan vara:
- Strukturerade
- Ostrukturerat
- Halvstrukturerade
Dessutom kan dessa olika data komma fram med olika hastigheter och intervall. Med Azure Data Factory kan du använda kopieringsaktiviteten för att flytta data från olika källor till ett enda centraliserat datalager i molnet. När du har kopierat data använder du andra system för att transformera och analysera dem.
Kopieringsaktiviteten utför följande steg på hög nivå:
Läsa data från källdatalagret.
Utför följande uppgifter på data:
- Serialisering/deserialisering
- Komprimering/dekomprimering
- Kolumnmappning
Kommentar
Det kan finnas ytterligare uppgifter.
Skriv data till måldatalagret (kallas för mottagare).
Den här processen sammanfattas i följande bild:

Omvandla och berika
När du har kopierat data till en central molnbaserad plats kan du bearbeta och transformera data efter behov med hjälp av Azure Data Factory-mappningsdataflöden. Med dataflöden kan du skapa datatransformeringsdiagram som körs på Spark. Du behöver dock inte förstå Spark-kluster eller Spark-programmering.
Dricks
Även om det inte är nödvändigt kanske du föredrar att koda dina transformeringar manuellt. I så fall har Azure Data Factory stöd för externa aktiviteter för att köra dina transformeringar.
CI/CD och publicera
Med stöd för CI/CD kan du utveckla och leverera dina ETL-processer (extract, transform, load) stegvis innan du publicerar. Azure Data Factory tillhandahåller CI/CD för dina datapipelines med hjälp av:
- Azure DevOps
- GitHub
Kommentar
Kontinuerlig integrering innebär att automatiskt testa varje ändring som görs i din kodbas så snart som möjligt. Kontinuerlig leverans följer den här testningen och skickar ändringar till ett mellanlagrings- eller produktionssystem.
När Azure Data Factory har förfinat rådata kan du läsa in data till den analysmotor som dina företagsanvändare kan komma åt från sina business intelligence-verktyg, inklusive:
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Monitor
När du har skapat och distribuerat din dataintegreringspipeline är det viktigt att du kan övervaka dina schemalagda aktiviteter och pipelines. Med övervakning kan du spåra framgångs- och felfrekvenser. Azure Data Factory har stöd för pipelineövervakning med någon av följande metoder:
- Azure Monitor
- API
- PowerShell
- Azure Monitor-loggar
- Hälsopaneler i Azure Portal
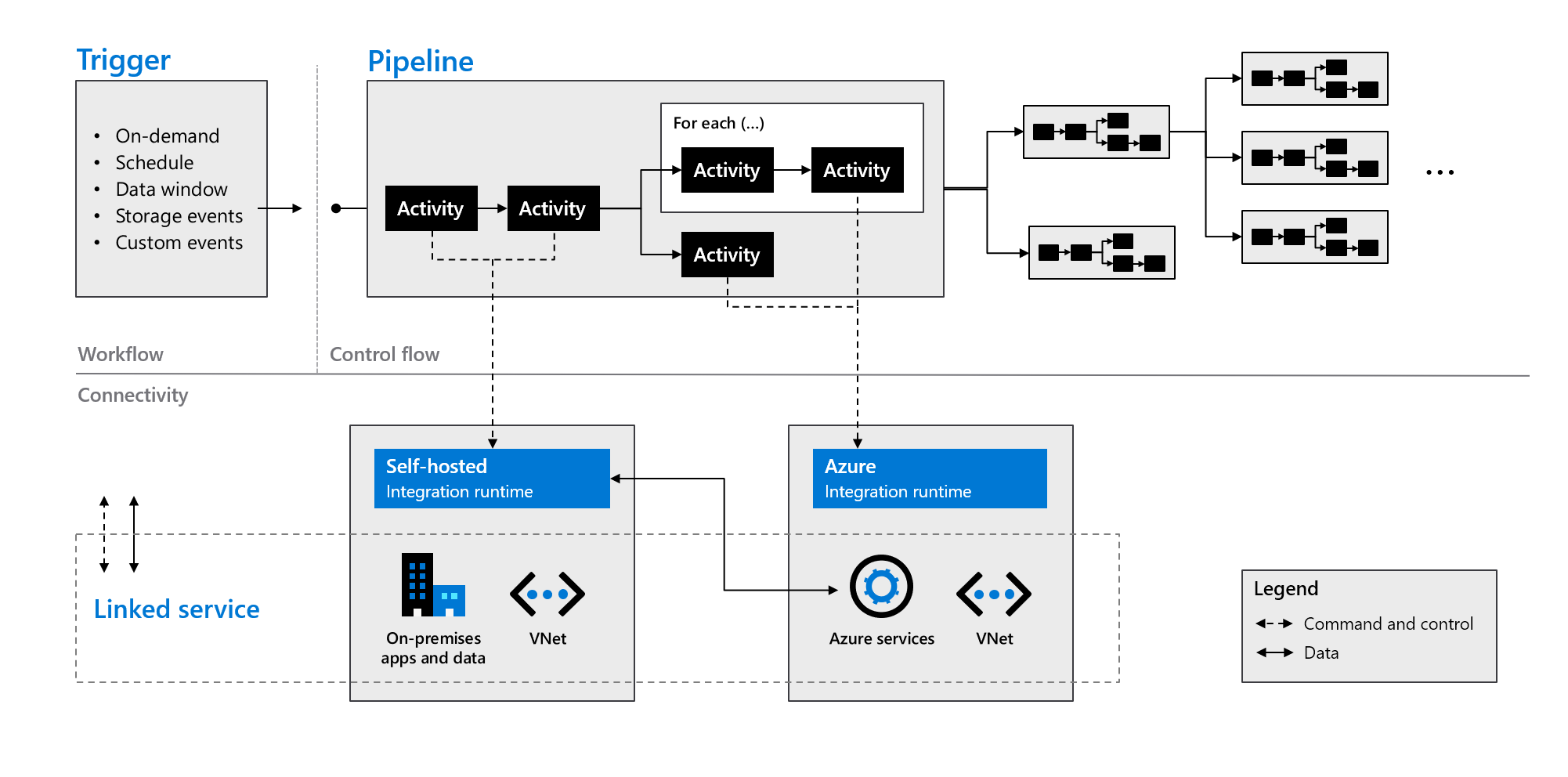
Azure Data Factory-komponenter
Azure Data Factory består av de komponenter som beskrivs i följande tabell:
| Komponent | beskrivning |
|---|---|
| Pipelines | En logisk gruppering av aktiviteter som utför en specifik arbetsenhet. De här aktiviteterna utför tillsammans en uppgift. Fördelen med att använda en pipeline är att du enklare kan hantera aktiviteterna som en uppsättning i stället för som enskilda objekt. |
| Aktiviteter | Ett enda bearbetningssteg i en pipeline. Azure Data Factory stöder tre typer av aktiviteter: dataförflyttning, datatransformering och kontrollaktiviteter. |
| Datauppsättningar | Representera datastrukturer i dina datalager. Datauppsättningar pekar på (eller refererar till) de data som du vill använda i dina aktiviteter som antingen indata eller utdata. |
| Länkade tjänster | Definiera den anslutningsinformation som krävs för att Azure Data Factory ska kunna ansluta till externa resurser, till exempel en datakälla. Azure Data Factory använder länkade tjänster i två syften: för att representera ett datalager eller en beräkningsresurs. |
| Dataflöden | Gör det möjligt för dina datatekniker att utveckla datatransformeringslogik utan att behöva skriva kod. Dataflöden körs som aktiviteter i Azure Data Factory-pipelines som använder utskalade Apache Spark-kluster. |
| Integreringskörningar | Azure Data Factory använder beräkningsinfrastrukturen för att tillhandahålla följande dataintegreringsfunktioner i olika nätverksmiljöer: dataflöde, dataflytt, aktivitetssändning och SQL Server Integration Services-paketkörning (SSIS). I Azure Data Factory tillhandahåller en integreringskörning bryggan mellan aktiviteten och länkade tjänster. |
Som du ser i följande bild arbetar dessa komponenter tillsammans för att tillhandahålla en komplett plattform från slutpunkt till slutpunkt för datatekniker. Genom att använda Data Factory kan du:
- Ange utlösare på begäran och schemalägg databearbetning baserat på dina behov.
- Associera en pipeline med en utlösare eller starta den manuellt när det behövs.
- Anslut till länkade tjänster (till exempel lokala appar och data) eller Azure-tjänster via integrationskörningar.
- Övervaka alla pipelinekörningar internt i Azure Data Factory-användarupplevelsen eller med hjälp av Azure Monitor.