Gör program skalbara
Nu när du förstår grunderna i att förbereda dig för tillväxt och är medveten om faktorer att tänka på i kapacitetsplaneringen kan du anta utmaningen att göra dina program så skalbara som möjligt.
Arkitekturgranskningar
En viktig punkt att komma ihåg är att du bör utföra regelbundna arkitekturgranskningar av dina system.
Du vet att du kan använda metoder som infrastruktur som kod för att förbättra hur du distribuerar dina molnresurser. Du uppdaterar och förbättrar programkoden regelbundet, och du bör göra samma sak med dina underliggande plattformsresurser.
Genom att utföra en arkitekturgranskning kan du identifiera de områden som behöver förbättras.
Azure Architecture Center har en mängd resurser som hjälper dig att skapa dina program i molnet, och det finns många skalbarhetsrekommendationer som du hittar i guiden för programarkitektur på följande länk:
Scenario: Tailwind Traders-arkitektur
Ett första steg är att göra en utvärdering av arkitekturen och programmet – inte bara för att avgöra var dess svagheter ligger, utan också för att känna igen dess styrkor. Vad är bra med det?
Ta en titt på scenariot som du såg i föregående lektion. Här är ett diagram över organisationens arkitektur igen.
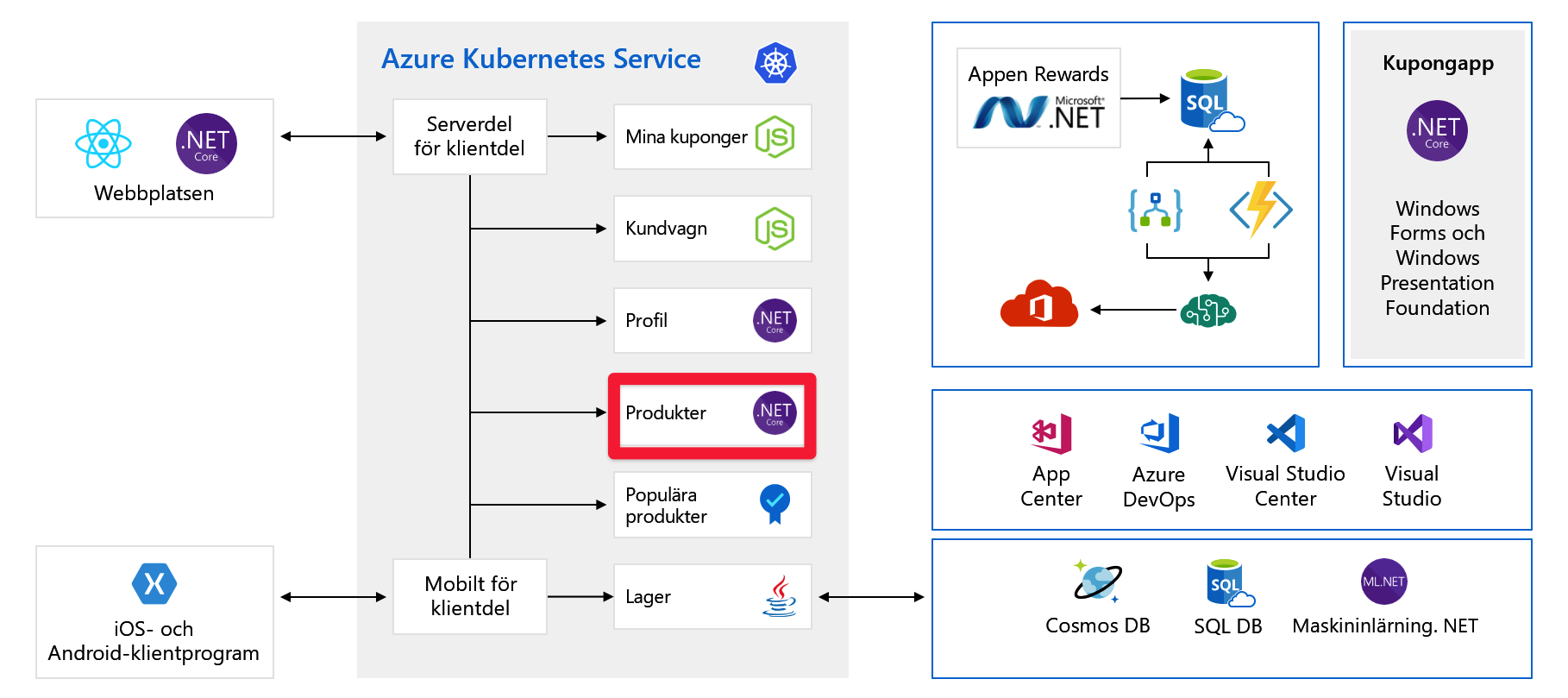
De har dela upp programmet i mindre mikrotjänster och vissa av dessa tjänster finns som containrar i Azure Kubernetes Service eller så kan de köras på virtuella datorer eller App Service. Du använder vissa skalbara tjänster som Functions och Logic Apps.
Den här ändringen är bra, men det finns vissa förbättringar som skulle göra programmet mer skalbart. Till exempel fokuserar du nu på produkttjänsten. I diagrammet körs produkttjänsten i Kubernetes, men vi antar för den här förklaringen att den körs på en virtuell dator i Azure. Skalningsbegreppen, eventuellt med en något annorlunda implementering, kan tillämpas på program oavsett om de körs på servrar, App Service eller i containrar.
Produkten körs för närvarande på en enda virtuell dator som är ansluten till en enda Azure SQL-databas. Du måste aktivera den här virtuella datorn för att skala ut. Du kan göra detta med hjälp av skalningsuppsättningar för virtuella Azure-datorer, vilket gör att du kan skapa och hantera en grupp med identiska, belastningsutjämningade virtuella datorer. Eftersom du nu har fler än en virtuell dator måste du introducera en lastbalanserare för att distribuera trafik mellan de virtuella datorerna.
Virtuella maskin skaleringsuppsättningar
Genom att använda vm-skalningsuppsättningar på enskilda virtuella datorer får du några fördelar:
- Du kan automatiskt skalera baserat på värdmått, gästmått, applikationsinsikter eller enligt ett schema.
- Du kan använda tillgänglighetszoner (AZ), som är oberoende fristående datacenter i en Azure-region. Med AZ-stöd kan du sprida dina virtuella datorer över flera virtuella datorer, vilket gör ditt program mer tillförlitligt och skyddar det mot datacenterfel. Nya instanser i en skalningsuppsättning fördelas automatiskt jämnt över AZs.
- Det blir enklare att lägga till en lastbalanserare. VM-skalningsuppsättningar stöder användning av Azure Load Balancer för grundläggande Layer 4-trafikdistribution. De stöder också Azure Application Gateway för mer avancerad L7-trafikdistribution och SSL-avslutning.
Det finns några viktiga faktorer som du måste tänka på innan du implementerar skalningsuppsättningar. Specifikt:
- Undvik instansen , så att ingen klient fastnar till en specifik serverdel.
- Ta bort beständiga data från den virtuella datorn och lagra dem någon annanstans, till exempel i Azure Storage eller i en databas.
- Design för skalning inåt. Det är också viktigt att programmet enkelt kan skalas ned igen. Den måste hantera att inte bara fler instanser läggs till i poolen med servrar som hanterar trafiken, utan även den plötsliga avslutningen av instanser när belastningen sjunker. Aspekten av nedskalning förbises ofta.
Frikoppling
Du har lagt till fler virtuella datorer med skalningsuppsättningar. Utskalning är det typiska svaret på "vi måste skala". Men du kan bara skala på ett enda mått, och det här svaret kanske inte är relevant för alla uppgifter som utförs av produkttjänsten.
I vårt scenario har produkttjänsten ett jobb. Den tar en produktbild och efter att den bilden har laddats upp. Den kodar om bilden och lagrar den i flera olika storlekar för miniatyrbilder, bilder i katalogen och så vidare. Avbildningsbearbetningen är processorintensiv, men den allmänna användningen är minnesintensiv.
Bildbearbetning är en asynkron uppgift som kan delas upp i ett bakgrundsjobb. Du kan göra det genom att frikoppla bildbehandlingstjänsten med hjälp av en kö. Med avkoppling kan du skala båda tjänsterna oberoende av varandra – en på minnet (produkttjänsten) och den andra (bildbearbetningstjänsten) på CPU eller till och med kölängd, och låta en annan skalningsuppsättning använda dessa meddelanden och bearbeta bilderna.
Skalera med köer
Azure har två typer av köerbjudanden:
- Azure Service Bus-köer Ett mer avancerat köerbjudande, som är en del av den bredare Azure Service Bus-produkten, som erbjuder pub/sub och mer avancerade integrationsmönster.
- Azure Storage Queues Ett enkelt REST-baserat kögränssnitt som bygger på Azure Storage. Den erbjuder tillförlitliga, beständiga meddelanden.
Dina krav i det här scenariot är enkla, så du kan använda Azure Storage-köer. Produktnivån behöver inte skalas alls eftersom du har frikopplat bakgrundsaktiviteten.
Cachelagring i minnet
Ett annat sätt att förbättra programmets prestanda är att implementera ett minnesinternt cacheminne.
Nu vet du att prestanda inte är exakt lika med skalbarhet, men genom att förbättra programmets prestanda kan du minska belastningen på andra resurser. Den här förbättringen innebär att du kanske inte behöver skala så snart.
Azure Cache for Redis är ett hanterat Redis-erbjudande. Redis kan användas för många mönster och användningsfall. För din produkttjänst i det här scenariot skulle du förmodligen implementera cache-aside-mönstret. I det här mönstret läser du in objekt från databasen i cacheminnet efter behov, vilket gör programmet mer högpresterande och minskar belastningen på databasen.
Redis kan också användas som en meddelandekö för cachelagring av webbinnehåll eller för cachelagring av användarsessioner. Den här typen av cachelagring kan vara mer lämplig för andra tjänster i systemet, till exempel kundvagnstjänsten, där du kan lagra kundvagnsdata per session i Redis i stället för att använda en cookie.
Skala databasen
Nu när du har gjort beräkningsresurserna mer skalbara kan du ta en titt på databasen. I det här scenariot använder du Azure SQL Database, som är ett hanterat SQL Server-erbjudande från Azure.
Relationsdatabaser är svårare att skala ut än icke-relationella databaser. Det första du kan göra för att skala databasen är att skala upp databasens storlek. Den här storleksändringen kan enkelt göras med en genomsnittlig stilleståndstid på under fyra sekunder. Antingen genom att använda ett enkelt API-anrop i Azure SQL eller genom att använda ett skjutreglage i portalen.
Om storleksändringen inte uppfyller dina krav, beroende på trafikegenskaper, kan det vara lämpligt att skala ut läsningarna till databasen. Ger dig möjlighet att dirigera lästrafik till din läsreplik.
Anteckning
För Azure SQL, om du använder premium- eller affärskritiska nivåer, är lässkalning ut aktiverat som standard. Den kan inte aktiveras på grundläggande nivåer eller standardnivåer.
Den här ändringen måste implementeras i kod. Så här gör du det.
#Azure SQL Connection String
#Master Connection String
ApplicationIntent=ReadWrite
#Read Replica Connection String
ApplicationIntent=ReadOnly
#Full Example
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Uppdatera attributet ApplicationIntent i databasanslutningssträngen för att ange till vilken server du vill ansluta. Använd ReadOnly om du vill ansluta till repliken eller ReadWrite om du vill ansluta till huvudservern.
Eftersom det här kommandot måste implementeras i kod kanske det inte är en lämplig lösning för din situation. Vad händer om varje enskild produkttjänst behöver kunna läsa och skriva?
I så fall kan du titta på hur du skalar ut SQL DB med hjälp av horisontell partitionering.
Databasuppdelning
Om databasresurserna efter att ha skalat upp eller implementerat läsrepliker fortfarande inte uppfyller systemets behov är nästa alternativ horisontell partitionering.
Horisontell partitionering är en teknik för att distribuera stora mängder identiskt strukturerade data över många oberoende databaser. Horisontell partitionering kan krävas av många orsaker. Till exempel:
- Den totala mängden data är för stor för att passa in i begränsningarna för en enskild databas.
- Transaktionsdataflödet för den totala arbetsbelastningen överskrider funktionerna i en enskild databas.
- Separata klienter måste finnas i olika fysiska databaser av efterlevnadsskäl (det här kravet handlar mindre om skalning, men är en annan situation där horisontell partitionering används).
Ditt program lägger till relevanta data till relevant shard och gör därför systemet skalbart utöver begränsningarna för den enskilda databasen.
Azure SQL erbjuder Azure Elastic Database-verktygen. De här verktygen hjälper dig att skapa, underhålla och fråga fragmenterade SQL-databaser i Azure från din programlogik.