Servicenivåindikatorer (SLI:er) och servicenivåmål (SLO:er)
I den här modulen hittills har vi lärt oss att öka vår driftsmedvetenhet, utöka vår förståelse och utformning av tillförlitlighet och har sett de Azure Monitor-verktyg som vi behöver för vårt arbete. Nu är det dags att utforska en av de viktigaste idéerna i den här modulen och processerna för att implementera den.
Nu ska vi svara på frågan ”hur kan jag använda allt det här för att förbättra tillförlitligheten i min organisation?”
Ange feedbackloopen
Här är den stora idén som kan hjälpa oss att lösa problemet:
Rätt feedbackloopar förbättrar tillförlitligheten i din organisation.
Att förbättra tillförlitligheten i din organisation är en iterativ process. I den här lektionen ska vi titta på en mycket effektiv metod från platsens tillförlitlighetsteknikvärld för att skapa och vårda den typ av feedbackslinga i en organisation som hjälper den att förbättra tillförlitligheten. Det ger åtminstone upphov till konkreta konversationer i din organisation om tillförlitlighet baserat på objektiva data.
Tidigare i den här modulen nämnde vi detta som en definition för SRE:
Site Reliability Engineering är ett teknikområde som ägnar sig åt att hjälpa organisationer att uppnå lämplig tillförlitlighetsnivå i sina system, tjänster och produkter.
Det är här konceptet lämplig nivå av tillförlitlighet spelar in.
Servicenivåindikatorer (SLI:er)
Servicenivåindikatorer (SLO) är kopplade till vår tidigare diskussion om den omfattande förståelsen för tillförlitlighet. Kommer du ihåg det här diagrammet?
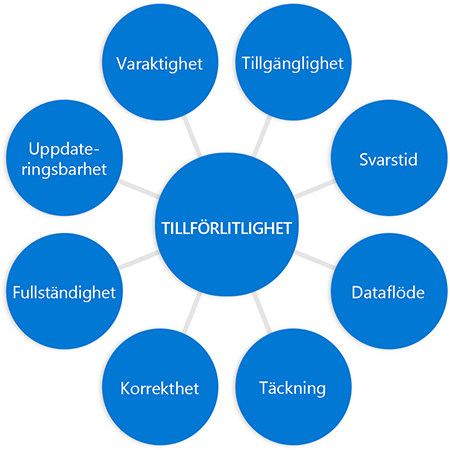
SLA:er är vårt försök att ange hur vi ska mäta systemets tillförlitlighet. Vad är indikatorn på att vår tjänst beter sig tillförlitligt (gör det vi förväntar oss)? Vad kan vi mäta för att besvara detta?
Exempel: tillgänglighet och svarstid för en webbserver
Anta att vi arbetar med en webbserver och dess tillgänglighet. Vi kanske är intresserade av antalet HTTP-begäranden som har mottagits och antalet HTTP-begäranden som den har besvarat. Mer exakt vill vi förstå hur framgångsrikt det har varit att vara en webbserver genom att förstå förhållandet mellan lyckade begäranden och totala begäranden.
Om vi delar antalet totala förfrågningar med antalet lyckade förfrågningar får vi ett förhållande. Vi kan multiplicera det här förhållandet med 100 för att få en procentandel. Vi tar ett exempel med avrundade siffror. Om vår webbserver har fått 100 begäranden och besvarat 80 av dem har vi ett förhållande på 0,8. Om vi multiplicerar det med 100 kan vi ange att det har varit 80 % tillgängligt.
Vi tar ett till exempel. Den här gången ska vi ange ett mått som är associerat med webbtjänstens svarstid. Vi är intresserade av att veta förhållandet mellan antalet åtgärder som har slutförts på mindre än 10 millisekunder jämfört med antalet totala åtgärder. Om vi gör samma matematik – 100 totala begäranden dividerade med 80 begäranden som returnerades snabbare än vårt tröskelvärde – beräknar vi återigen ett förhållande på 0,8. Multiplicera med 100, och även här kan vi säga att vi har lyckats 80 % med våra svarstidskrav med den här mätningen.
Bara för att vara tydlig: detta är inte bara en webbplats sak. Om vi hade en pipelinetjänst som bearbetade data kan vi säga att vi måste mäta täckningen (till exempel hur mycket av de data vi bearbetade). Mycket annorlunda system, men samma grundläggande matematik.
SLI: måttplats
För att SLI:er ska vara användbara i konkreta diskussioner med hjälp av objektiva data finns det en annan del som vi måste ange utöver vad vi mäter. När vi skapar en SLI måste vi notera inte bara vad vi mätte, utan även var mätningen gjordes.
När vi angav vad vi mätte för webbserverns tillgänglighet tidigare sade vi till exempel inte varifrån vi hämtade antalet lyckade och totala HTTP-begäranden. Om du försöker ha en konversation om tillförlitligheten för den här webbservern med några kollegor, och du tittar på begärandestatistiken som samlats in i en lastbalanserare framför servern, men de tittar på statistiken från själva servern, kanske den här konversationen inte går så bra. Siffrorna kan vara radikalt olika eftersom lastbalanseraren kan se alla begäranden som kommer in i nätverket, men om det är problem med nätverket eller själva lastbalanseraren kan inte alla begäranden nå servern. Vi skulle dra slutsatser baserat på två olika datauppsättningar.
Det enkla sättet att åtgärda detta är att vara specifik om datakällan i SLI. För webbservern kunde vi säga att ”förhållandet mellan lyckade och totala begäranden enligt mätning vid lastbalanseraren” för tillgänglighet. För svarstiden skulle vi säga något i stil med "förhållandet mellan antalet åtgärder som har slutförts på mindre än 10 millisekunder och totalt antal åtgärder mätt på klienten".
Detta leder till den logiska frågan: var är det bästa stället att mäta SLI:er? Tyvärr finns det inte ett universellt "korrekt" svar. Det är ett beslut som du måste fatta med vetskapen att det innebär kompromisser hur du än gör. En vägledning som vi kan erbjuda harkens tillbaka till vår tidigare diskussion om tillförlitlighet: försök att mäta saker på en plats som bäst återspeglar kundens upplevelse.
Servicenivåmål (SLO:er)
Det är en bra början att avgöra vad som ska mätas (och var), men det tar oss bara halvvägs till vårt mål. Anta att vi hämtar de mått vi behöver för vår webbservers tillgänglighets-SLI, och vi upptäcker att det verkligen är 80 % tillgängligt.
Är det bra eller dåligt? Är det en ”lämplig nivå av tillförlitlighet”?
För att besvara dessa frågor måste vi ange ett mål för den SLI:en: ett servicenivåmål (SLO). Det här målet ska tydligt och klart ange vårt mål för tjänsten.
Det grundläggande receptet för att skapa ett servicenivåmål består av följande komponenter:
Den "sak" som du ska mäta: Antal begäranden, lagringskontroller, åtgärder; det du mäter.
Önskad andel: Till exempel "lyckades 50 % av tiden", "kan läsa 99,9 % av tiden", "returnera på 10 ms 90 % av tiden".
Tidshorisonten Vilken tidsperiod ska vi överväga för målet: de senaste 10 minuterna, under det senaste kvartalet, under ett rullande 30-dagarsfönster? Serviceavtal anges oftare än inte med ett rullande fönster jämfört med en kalenderenhet som "en månad" så att vi kan jämföra data från olika perioder.
Genom att sätta ihop dessa komponenter och inkludera viktig information kan ett exempel-SLO se ut så här:
90 % av HTTP-begäranden som rapporterats av lastbalanseraren lyckades under det senaste 30-dagarsfönstret.
På samma sätt kan en grundläggande SLO som mäter svarstid se ut så här:
90 % av HTTP-begäranden som rapporterats av klienten som returnerades på <20 ms i det senaste 30-dagarsfönstret.
Börja med enkla, grundläggande SLO:er som de här när du introducerar metoden i din organisation. Du kan skapa mer komplexa SLO:er senare om det behövs.
SLI:er och SLO:er i Azure Monitor
I den sista delen av den här enheten ska vi se hur vi kan representera ett enkelt SLI/SLO i Azure Monitor med hjälp av Log Analytics. För att hålla det konsekvent återgår vi till webbserverexemplet.
Vi lärde oss i den senaste lektionen att vi kan skapa frågor i Log Analytics med hjälp av Kusto-frågespråk (KQL). Här är en KQL-fråga som visar en tillgänglighets-SLI för en webbtjänst:
requests
| where timestamp > ago(30d)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| project SLI, timestamp
| render timechart
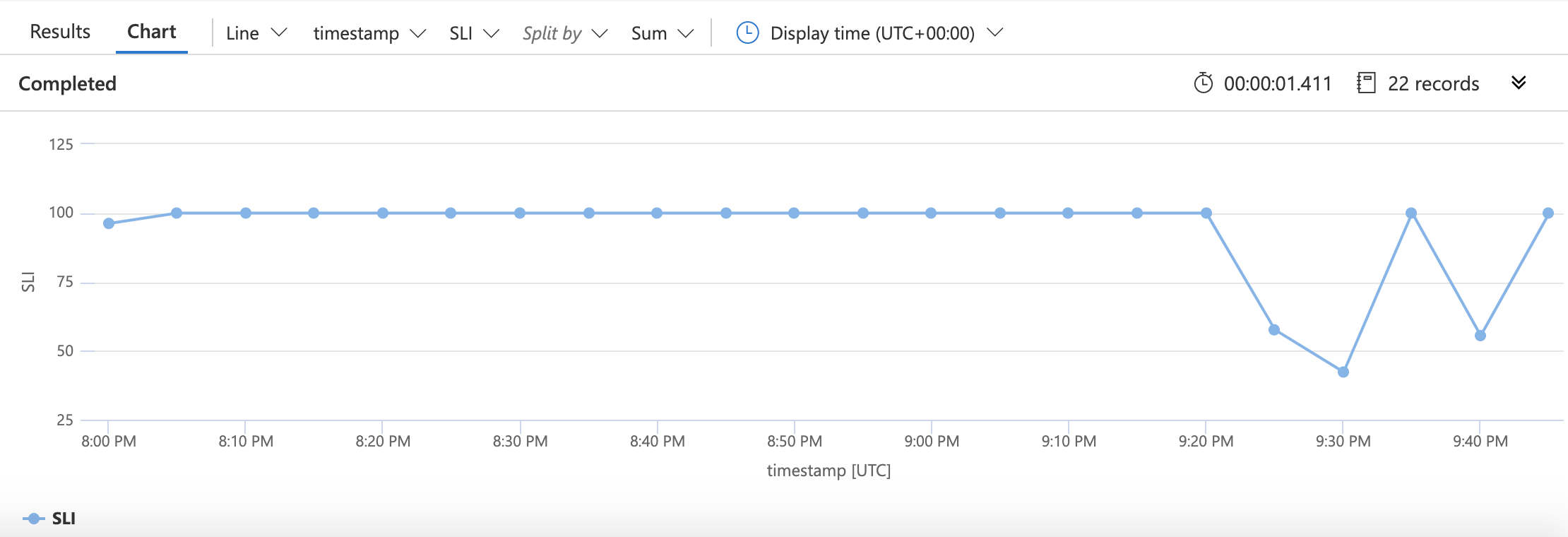
Precis som tidigare börjar vi med att ange datakällan: tabellen requests . Sedan begränsar vi de data som vi kommer att arbeta med för bara de senaste 30 dagarnas information. Sedan samlar vi in (i femminuters bucketar) antalet lyckade begäranden, antalet misslyckade begäranden och det totala antalet begäranden. SLI skapas med hjälp av den enkla aritmetik som vi såg tidigare. Vi säger till KQL att vi vill rita den SLI:n tillsammans med tidsstämplar och sedan skapa ett diagram som ser ut ungefär så här:
Nu lägger vi på en enkel representation av ett SLO:
requests
| where timestamp > ago(5h)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| extend SLO = 80.0
| project SLI, timestamp, SLO
| render timechart
Två rader har ändrats i det här exemplet från det föregående. Den första definierar det tal som vi ska använda för SLO. den andra talar om för KQL att SLO ska ingå i diagrammet. Resultatet ser ut så här:
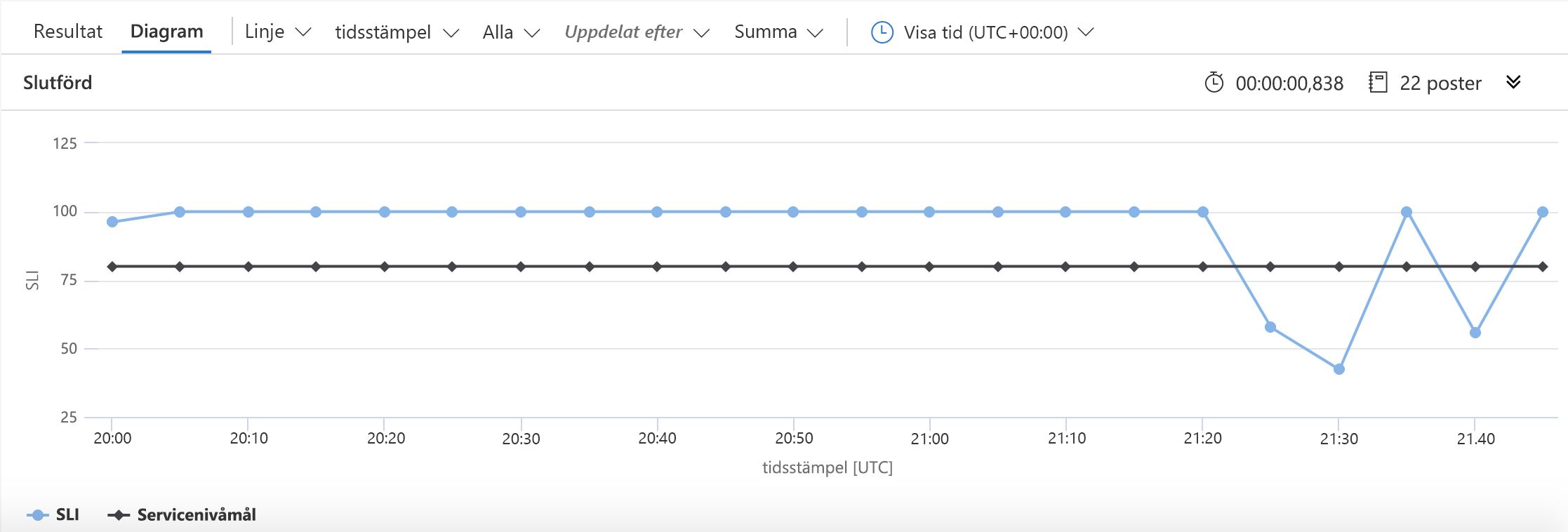
I det här diagrammet är det enkelt att se den tid då vi sjönk under vårt tillgänglighetsmål.
Använda SLI/SLO
Det finns alltid en viss justering som måste ske med dina SLO:er och serviceavtal (det här är trots allt en iterativ process). Men när det är klart, vad gör du med informationen?
Varunyheterna är att du förmodligen kommer att märka att bara konstruktion av SLO:er och SLO:er kommer att ha positiva effekter på organisationen. Det kräver diskussioner med intressenter och annan kommunikation som skapar bra förutsättningar. Nästa steg med diskussioner om vad du kan göra med dem kan vara användbart på samma sätt.
I slutändan är SLO:er och SLO:er arbetsplaneringsverktyg. De kan hjälpa dig att fatta tekniska beslut som "ska vi arbeta med nya funktioner för tjänsten eller ska vi fokusera på tillförlitlighetsarbete i stället?" De kan hjälpa till med den typ av feedbackslingor som vi diskuterade tidigare.
En sekundär men ganska vanlig användning för SLO:er och SLO:er är en del av ett mer omedelbart övervaknings-/svarssystem. Förutom arbetsplaneringsaspekten (som du bör fokusera på först) använder många människor dem som en driftsignal. De kan till exempel välja att varna sin personal om tjänsten sjunker under sitt servicenivåmål under en längre tid. Den här typen av avisering leder oss till den nästa enheten i den här modulen.