Testningsautomatisering och leveranspipeline
Du har lärt dig om kontinuerlig distribution och leverans av programvara och tjänster, men de två ingår i en triad. DevOps-metoder syftar till att uppnå kontinuerlig integrering, distribution och leverans.
Nu är det dags att säkerhetskopiera och diskutera det första av följande: integrering. Detta är en del av den utvecklingsprocess som kommer före distributionen. DevOps rekommenderar en utvecklingsmetod där teammedlemmar ofta integrerar kod på en delad lagringsplats som innehåller en enskild ”huvud-” eller ”stamkodbas”. Målet är att alla ska bidra till den kod som kommer att lanseras i stället för att de arbetar med egna kopior och sedan sammanför allt i sista minuten.
Automatiserad testning kan sedan verifiera varje teammedlems integrering. Den här testningen hjälper till att fastställa att koden är ”felfri” efter varje ändring och tillägg som görs. Testningen är en del av vad vi skulle kalla en pipeline. Vi kommer att prata om pipelines på bara ett ögonblick, eftersom den här enheten fokuserar på integrerade test- och leveranspipelines.
Pipelinen för kontinuerlig leverans
För att förstå den automatiserade testningens roll i distributionsmodellen för kontinuerlig leverans måste du titta på var den passar in i leveranspipelinen. En pipeline för kontinuerlig leverans är implementeringen av de steg som koden genomgår när ändringar görs under utvecklingsprocessen innan den distribueras till produktion. Här är en grafisk representation av exempelsteg i en förenklad leveranspipeline:
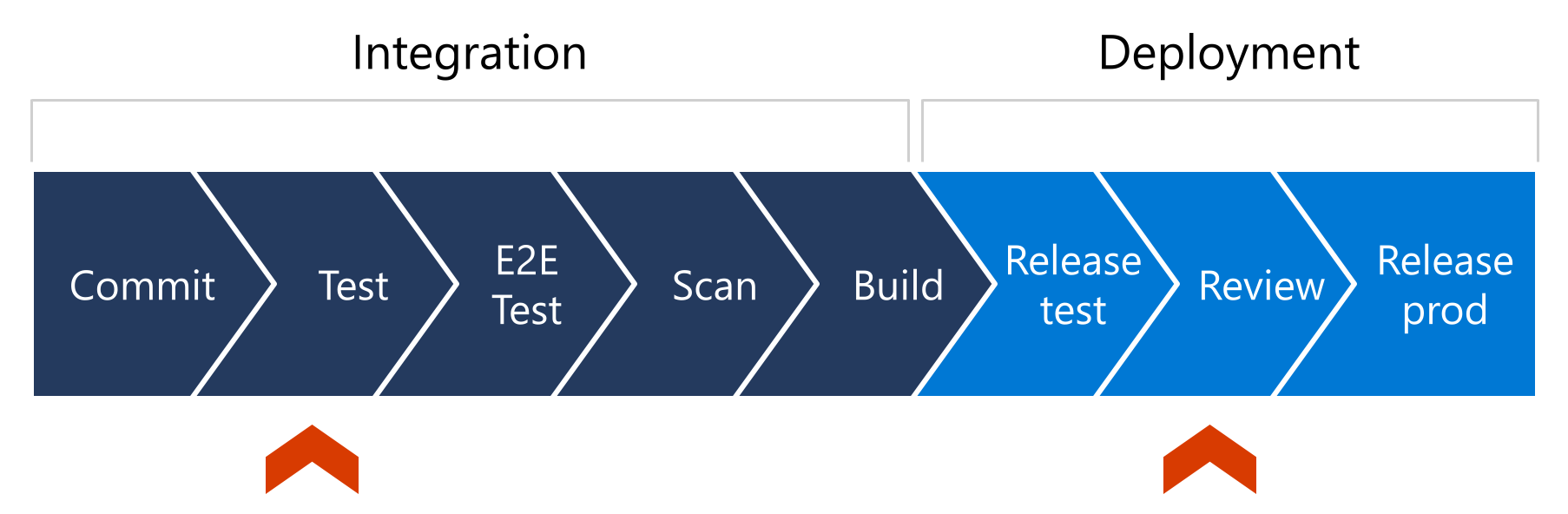
Vi går igenom denna pipeline steg för steg.
En instans av pipelinen börjar när kod- eller infrastrukturändringar checkas in till en kodlagringsplats, kanske med hjälp av en pull-begäran.
Därefter körs enhetstester – kanske integrerings- eller slutpunkt-till-slutpunkt-tester – och helst förmedlas dessa testresultat tillbaka till den begärande parten.
I det här läget kanske koden på lagringsplatsen genomsöks efter hemligheter, sårbarheter och aspekter av konfigurationen.
När allt stämmer kompileras koden och förbereds för distribution.
Sedan distribueras koden till en testmiljö. En människa får kanske en avisering om den nya distributionen och kan då kontrollera lösningen före produktion. Denna person kan sedan godkänna eller neka distributionen för produktion, vilket inleder den sista delen av distributionsprocessen som lanserar koden till produktion.
I den här pipelinen kan du notera avgränsningen mellan integrering och distribution. De röda markeringarna pekar ut några logiska platser där du kan stoppa pipelinen med hjälp av inkluderad logik och automatisering, eller potentiellt till och med mänsklig inblandning.
Verktyg för kontinuerlig integrering och leverans: Azure Pipelines
För att använda kontinuerlig integrering och kontinuerlig leverans behöver du rätt verktyg. Azure Pipelines ingår i de Azure DevOps-tjänster som du kan använda för att automatisera kompilering och konsekvent testning av kod. Du kan även använda Azure Pipelines för att distribuera koden till Azure-tjänster, virtuella datorer och andra mål både i molnet och lokalt.
Indata till en pipeline (vår kod eller våra konfigurationer) finns i ett versionskontrollsystem som GitHub eller någon annan Git-provider.
Azure Pipelines körs på en beräkningsdel, till exempel en virtuell dator eller en container, och erbjuder kompileringsagenter som kör Windows, Linux och macOS. Det erbjuder också integrering med plugin-program för testning, säkerhet och kodkvalitet. Slutligen är det enkelt att utökningsbara, så du kan ta med din egen automatisering till Azure Pipelines.
Pipelines definieras med hjälp av YAML-syntax eller via det klassiska användargränssnittet i Azure-portalen. När du använder en YAML-fil kan du lagra filen tillsammans med din kod. Pipelines tillhandahåller också mallar som du kan använda för att enkelt skapa pipelines. till exempel en pipeline som skapar en Docker-avbildning eller ett Node.js projekt. Du kan dessutom återanvända en befintlig YAML-fil.
Här är de grundläggande stegen oavsett om du använder en YAML-fil eller det klassiska gränssnittet:
- Konfigurera Azure Pipelines till att använda din Git-lagringsplats.
- Definiera din version, antingen genom att redigera azure-pipelines.yml-filen eller med hjälp av den klassiska redigeraren.
- Skicka koden till lagringsplatsen för versionskontroll. Den här åtgärden utlöser pipelinen för att kompilera och testa koden.
När koden har uppdaterats, kompilerats och testats kan du distribuera den till valfritt mål.
Det finns vissa funktioner (till exempel att köra containerjobb) som endast är tillgängliga när du använder YAML och andra (till exempel aktivitetsgrupper) som endast är tillgängliga med det klassiska gränssnittet.
Azure-pipelinekonstruktion
Pipelines är strukturerade som:
Jobb: Ett jobb är en gruppering av uppgifter eller steg som körs på en enda byggagent. Ett jobb är den minsta arbetskomponent som du kan schemalägga för körning. Alla steg i ett jobb körs sekventiellt. Dessa steg kan vara vilken typ av åtgärd du vill, inklusive att skapa/kompilera programvara, förbereda exempeldata för testning, köra specifika tester och så vidare.
Steg: En fas är en logisk gruppering av relaterade jobb.
Varje pipeline har minst en fas. Använd flera faser för att organisera pipelinen i större avsnitt och markera punkter i pipelinen där du kan pausa och utföra kontroller.
Pipelines kan vara så enkla eller komplexa som du vill. Det finns utmärkta självstudier om pipelinekonstruktion och användning i utbildningsvägen Skapa program med Azure DevOps .
Miljöspårbarhet
Det finns en annan aspekt av pipelines som är relaterade till tillförlitlighet som är värda att nämna. Du kan konstruera dina pipelines på ett sådant sätt att det är möjligt att korrelera det som körs i produktion med en specifik bygginstans. Helst bör vi kunna spåra en version tillbaka till en specifik PR- eller kodändring. Detta kan vara mycket användbart, antingen under en incident eller efteråt under granskningen efter incidenten när du försöker identifiera vilken ändring som bidrog till ett problem. Vissa CI/CD-system (till exempel Azure Pipelines) gör det enkelt att göra detta, medan andra kräver att du manuellt skapar en pipeline som sprider någon form av "bygg-ID" genom alla faser.