Modellera små uppslagsentiteter
Vår datamodell innehåller två små referensdataentiteter ProductCategory och ProductTag. Dessa entiteter används för referensvärden och är relaterade till andra entiteter genom en 1:Many relationship.
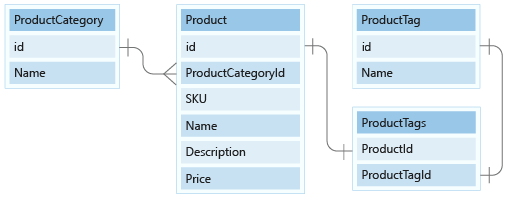
I den här lektionen ska vi modellera entiteterna ProductCategory och ProductTag i vår dokumentmodell.
Modellproduktkategorier
För det första för kategorier ska vi modellera data med dess ID - och namnkolumner som de enda egenskaperna och placera dem i en ny container med namnet ProductCategory.
Därefter måste vi välja en partitionsnyckel. Nu ska vi utforska de åtgärder som vi behöver utföra på dessa data.
Vi skapar en ny produktkategori, redigerar en produktkategori och listar sedan alla produktkategorier. Det är inte vanligt att skapa och redigera produktkategorier. Vårt e-handelsprogram visar ofta alla produktkategorier när kunder besöker webbplatsen. Så den sista åtgärden är den som vi ska köra mest.
Frågan för den senaste åtgärden ser ut så här: SELECT * FROM c.
Med ID som den valda partitionsnyckeln kommer den här frågan nu att vara korspartitionerad, även om vi vill försöka optimera dessa läsintensiva åtgärder använder endast en enda partition om möjligt. Vi vet också att data för produktkategorin aldrig kommer att växa nära 20 GB i storlek, så hur skulle den här informationen hjälpa oss att modellera data på ett sätt som resulterar i en enskild partitionsfråga när vi listar alla produktkategorier.
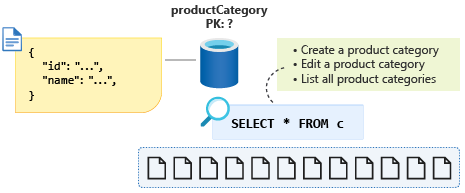
För att tvinga tillbaka den här lilla mängden data till en enda partition kan vi lägga till en entitetsdiskriminerande egenskap i vårt schema och använda den som partitionsnyckel för den här containern. Genom att tilldela den här egenskapen ett konstant värde för alla dokument av den här typen i containern ser vi till att vi nu har en enda partitionsfråga. I det här fallet anropar vi egenskapen type och ger ett konstant värde på category. Vår fråga skulle nu se ut så här: SELECT * FROM c WHERE c.type = ”category”.

Modellprodukttaggar
Nästa steg är entiteten ProductTag . Den här entiteten är nästan identisk i funktion med ProductCategory entiteten som vi diskuterade i föregående avsnitt. Låt oss använda samma metod här och modellera dokumentet så att det innehåller ID- och namnegenskaper och skapa en entitetsdiskriminerande egenskap med namnet type, i det här fallet med ett konstant värde på tag. Nu ska vi skapa en ny container med namnet ProductTag och skapa type den nya partitionsnyckeln.
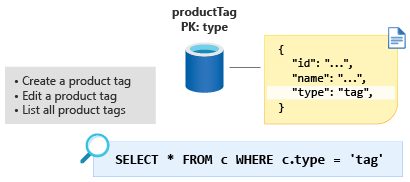
Vissa tycker att den här tekniken för att modellera små uppslagstabeller är konstig. Men att modellera våra data på det här sättet ger oss möjlighet att göra en ytterligare optimering i nästa modul.