Introduktion
Azure Cosmos DB är Microsofts fullständigt hanterade NoSQL-databas i Azure. Som NoSQL-databas är Azure Cosmos DB både icke-relationellt och vågrätt skalbart eller skalas ut. Den här möjligheten att skala ut uppnås genom att lägga till fler noder eller partitioner i en container.
Den här möjligheten att skala ut gör att containrar kan växa till en teoretiskt oändlig storlek. Så när en container växer i storlek kan containern också hantera allt fler begäranden, vilket ger samma prestanda oavsett hur stor containern blir.
För att uppnå den här skalbarhetsnivån måste användarna dock förstå de begrepp och tekniker som är unika för Azure Cosmos DB för modellering och partitionering av data. Användarna måste också förstå begreppen för NoSQL-databaser i allmänhet.
Scenario
Anta att du arbetar för en nystartad återförsäljare som utformar en databas för att hantera onlinebeställningar. Du arbetar med ett förslag på en effektiv databasdesign med hjälp av Azure Cosmos DB for NoSQL. Du får en entitetsrelationsmodell att börja från. Du vill tillhandahålla maximal skalbarhet, prestanda och effektivitet och för att uppnå den här uppgiften så att data måste modelleras korrekt.
Följande entitetsrelationsdiagram (ER-modell) innehåller information om de nio entiteter som du förväntar dig att arbeta med. Relationsmodellen har nio entiteter i sina egna tabeller.
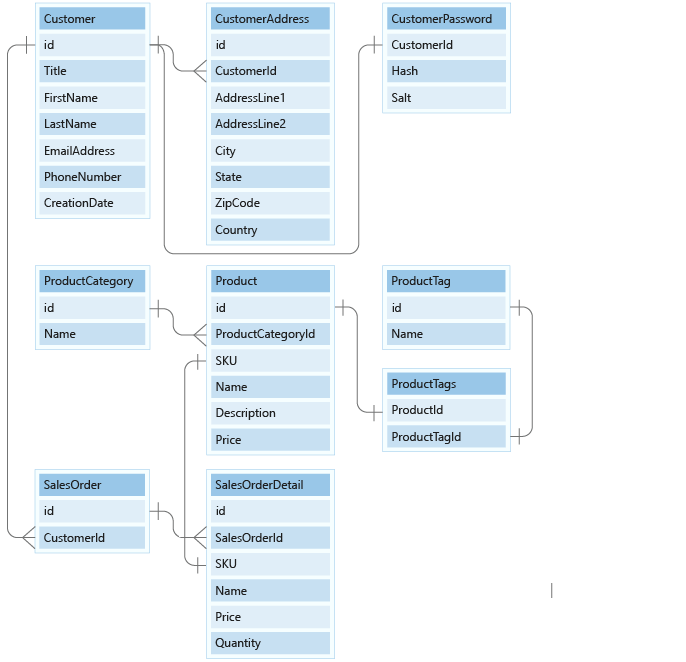
Hur gör vi detta?
I den här modulen tar vi vår befintliga relationsdatamodell och designar om den som en NoSQL-databas för vårt e-handelsprogram. Under den här processen får du lära dig följande begrepp:
- Skillnader mellan relationsdatabaser och NoSQL-databaser: Du utforskar några av skillnaderna mellan NoSQL-databaser och relationsdatabaser och varför de är så.
- Använda åtkomstmönster för programdata för att modellera data: Du lär dig hur förståelse för hur ett program läser och skriver data påverkar hur det modelleras för en NoSQL-databas.
- Inbäddning jämfört med referens: Du lär dig när du ska bädda in data i samma dokument jämfört med när du ska lagra data som ett separat dokument.
- Välja en partitionsnyckel: Du lär dig viktiga begrepp som behövs för att välja den bästa partitionsnyckeln för att uppnå möjligheten att skala ut och optimera arbetsbelastningar som antingen är läs- eller skrivintensiva eller båda.
- Uppslags- eller referensdata för modellering: Slutligen får du lära dig hur du modellerar data som används som uppslag eller referens för andra data.
Vad är huvudmålet?
När du är klar med den här modulen (och tilläggsmodulen Optimera din databas med hjälp av avancerade modelleringsmönster för Azure Cosmos DB) har du kunskaper och färdigheter för att korrekt modellera och partitionera data för en NoSQL-databas som distribuerats i Azure Cosmos DB.
I den här modulen kommer du att:
- Fastställa åtkomstmönster för data.
- Använd strategier för datamodeller och partitionering för att stödja en effektiv och skalbar NoSQL-databas.