Åtkomstkrav för hybridfiler
De tidigare enheterna fokuserade till stor del på vad din lagringslösning gör. Den här lektionen fokuserar på var dina data finns. Mer specifikt överväganden för åtkomst till hybridfiler och hur du närmar dig dem.
Översikt över hybridfilåtkomst
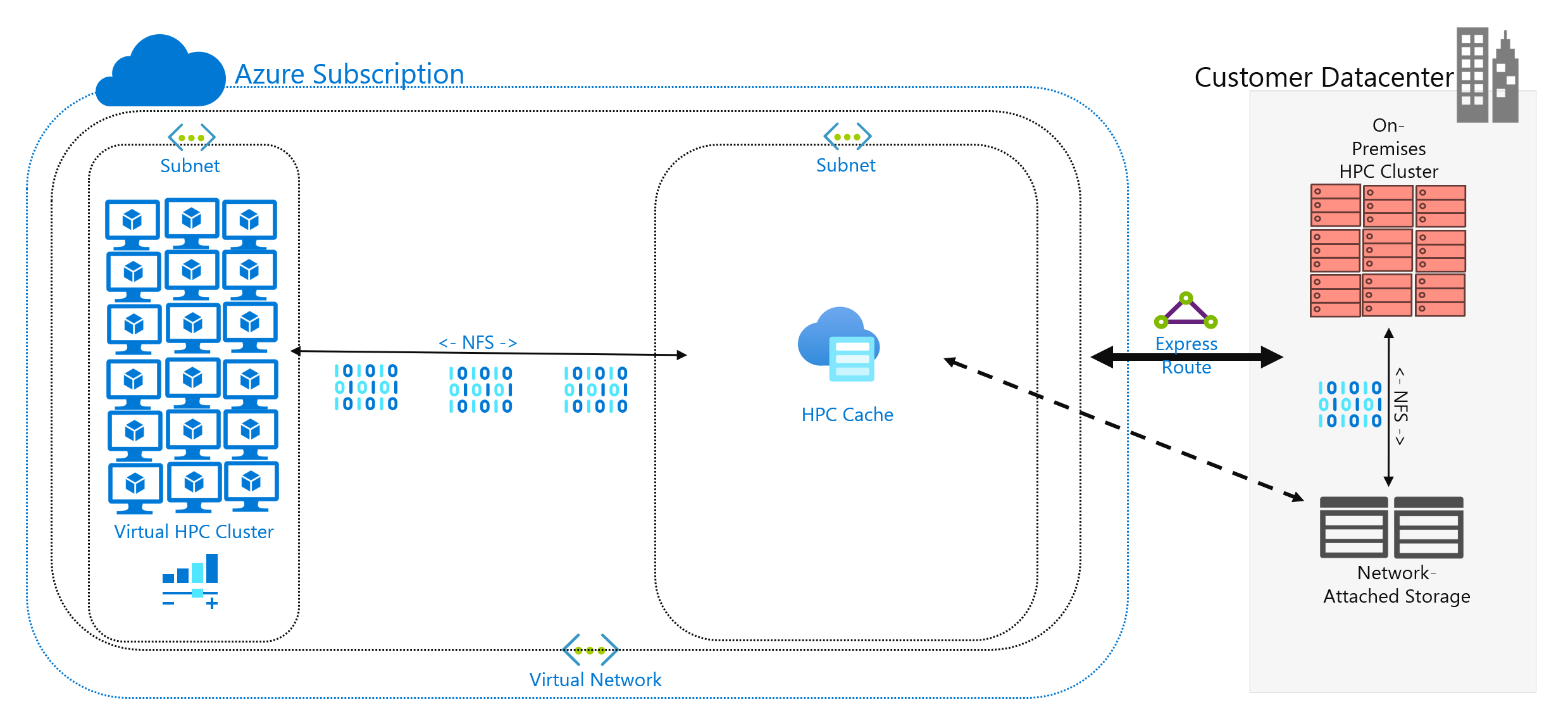
Du har bestämt dig för att köra en HPC-arbetsbelastning i Azure som för närvarande körs i ditt datacenter. Din beräkningsmiljö kommer åt data på din NAS, som hanterar NFSv3-åtgärder till din arbetsbelastning. Den har körts där i flera år, men din NAS-miljö kanske når slutet av sin cykel. I stället för att ersätta den överväger du en långsiktig migrering till molnet.
När du har fattat det här beslutet, men innan du distribuerar din HPC-arbetsbelastning i molnet, fastställer du din Azure-strategi och upprättar ditt baslinjekonto/din prenumeration/säkerhetskonfiguration. Nu är det svåra: att flytta dina HPC-arbetsbelastningar!
Versionen av ditt HPC-kluster och dess hanteringsplan ligger utanför omfånget för den här modulen. Vi antar att du har fastställt vilka typer av virtuella datorer och kvantiteter som du vill köra i klustret.
För tillfället förutsätter vi också att målet är att köra arbetsbelastningen som den är. Du vill alltså inte ändra logiken eller åtkomstmetoderna som för närvarande distribueras lokalt. Konsekvensen är att koden förväntar sig att data ska finnas på katalogsökvägar i klustermedlemmarnas lokala filsystem.
Det första målet är att förstå vilka data som krävs och var de kommer från. Dina data kan finnas i en enda katalog i en enda NAS-miljö, eller så kan de vara utspridda i olika miljöer.
Nästa mål är att fastställa hur mycket data som krävs för att köra arbetsbelastningen. Är källdata ett par gigabyte, eller är det hundratals terabyte?
Slutligen måste du avgöra hur data presenteras i Azure-beräkning. Hanteras den lokalt till varje HPC-klusterdator eller delas den av en molnbaserad NAS-lösning?
Överväganden för fjärrdataåtkomst
Du har en genomikarbetsbelastning som du vill köra i Azure. Dina data genereras lokalt av gensekvenserare och skickas till en lokal NAS-miljö. Lokala forskare använder data för olika användningsområden. Forskarna kanske också vill använda resultatet av den HPC-arbetsbelastning som du tänker köra i Azure. Men vissa av dem använder lokala arbetsstationer för att göra det. Vi antar också att nya genomiska data genereras regelbundet. Därför har du ett begränsat intervall för att köra den aktuella arbetsbelastningen innan data måste ersättas/uppdateras.
Utmaningen är att presentera data för Azure-beräkning på ett kostnadseffektivt sätt i rätt tid, men ändå bevara lokal åtkomst till den.
Här är några av de viktigaste frågorna att ställa när du försöker köra HPC-arbetsbelastningar i Azure:
- Kan vi flytta källdata till Azure utan att behålla en kopia lokalt?
- Kan vi spara resultatdata i Azure Storage utan att spara en kopia lokalt?
- Behöver lokala användare samtidig åtkomst till käll- eller resultatdata?
- Om de gör det kan de arbeta med data i Azure, eller behöver de data som ska lagras lokalt?
Hur mycket data måste kopieras till Azure för arbetsbelastningen om data behöver sparas lokalt? Hur lång tid har du på dig när data har bearbetats innan du behöver bearbeta en ny uppsättning data? Kommer din arbetsbelastning att köras inom den tidsramen?
Du måste också överväga nätverksanslutning till Azure. Har du bara internetåtkomst till Azure? Den begränsningen kan vara OK, beroende på storleken på de data som ska kopieras/överföras och hur lång tid mellan uppdateringarna. Du kanske har en stor mängd data att kopiera varje gång. Du kan behöva en WAN-anslutning (Wide Area Network) till Azure som använder Azure ExpressRoute, vilket skulle ge mer bandbredd för att kopiera/överföra data.
Om du redan har en ExpressRoute-anslutning till Azure bör du tänka på följande: hur mycket av anslutningen är tillgänglig för din datakopieringsåtgärd? Om länken är kraftigt mättad kan du behöva tänka på vilken tid på dagen du överför data. Eller så kanske du vill konfigurera en större ExpressRoute-anslutning för stora dataöverföringar.
Om du flyttar data till Azure kan du behöva överväga hur du skyddar dem. Du kan till exempel ha en lokal NFS-miljö som använder en katalogtjänst som hjälper till att utöka behörigheter till dina användare. Om du planerar att kopiera den här säkerheten till Azure måste du bestämma om du behöver en katalogtjänst som en del av Azure-versionen. Men om din arbetsbelastning är begränsad till HPC-klustret och resultatet skulle överföras tillbaka till din lokala miljö kanske du kan utelämna dessa krav.
Därefter överväger vi metoderna för att komma åt data: cachelagring, kopiering och synkronisering.
Cachelagring jämfört med kopiering jämfört med synkronisering
Nu ska vi gå igenom de allmänna metoder som du kan använda för att lägga till data i Azure. Fokus för den här dataöverföringsdiskussionen är aktiva data, inte dataarkiv och säkerhetskopiering.
Anta att de data som överförs i vår diskussion är arbetsuppsättningen för en HPC-arbetsbelastning. I en HPC-miljö för biovetenskap kan data innehålla källdata som rådata, binärfiler som används för att bearbeta dessa data eller kompletterande data som referensgenom. Den måste bearbetas omedelbart vid ankomsten eller inte långt efter. Data måste också lagras på media som har rätt prestandaprofil för IOPS, svarstid, dataflöde och kostnad. Däremot överförs arkiv-/säkerhetskopieringsdata oftast till den billigaste möjliga lagringslösningen, som inte är avsedd för högpresterande åtkomst.
De viktigaste metoderna för att överföra aktiva data är cachelagring, kopiering och synkronisering. Låt oss diskutera för- och nackdelarna med varje metod, som börjar med kopiering.
Att kopiera data är den vanligaste metoden för att flytta data. Data kopieras på olika sätt, beroende på vilket verktyg du använder.
Tänk på följande faktorer:
- Storleken på filerna.
- Antalet filer.
- Mängden tillgängligt dataflöde för överföring av data.
- Hur lång tid du måste göra överföringen.
Ett grundläggande kopieringsverktyg som cp är allt du behöver om du överför en handfull filer i rimlig storlek till ett fjärrmål. Du vill förmodligen använda scp i stället för cp om du överför data över nätverk som inte är säkra: scp tillhandahåller kryptering via en SSH-anslutning (Secure Shell).
Det finns många metoder för att optimera kopieringsåtgärder, beroende på var du tänker kopiera data. Om du kopierar filer direkt till varje HPC-dator kan du till exempel schemalägga enskilda kopieringsåtgärder på varje nod.
Ett övervägande när du kopierar data mellan WAN-länkar är mängden filer och mappar som kopieras. Om du kopierar många små filer vill du kombinera användningen av kopiering med ett arkiv som tar att ta bort metadatakostnaderna från WAN-länken. Kopiera .tar-filen till Azure och kopiera sedan data till datorerna.
Ett annat problem med kopiering innebär risken för avbrott. Om du till exempel försöker kopiera en stor fil och det finns överföringsfel fungerar inte användningen cp eftersom den inte kan starta om kopian där den slutade.
Ett sista problem med att kopiera data är att din kopia kan bli inaktuell. Du kan till exempel kopiera en datauppsättning till Azure. Under tiden kan en lokal användare ha uppdaterat en eller flera av källfilerna. Du måste fastställa en process för att säkerställa att du använder rätt data.
Att synkronisera data är en form av kopiering, men det är mer avancerat. Verktyg som rsync att lägga till möjligheten att synkronisera data mellan källan och målet utöver att kopiera dem från källan.
rsync ser till att filerna är uppdaterade baserat på filstorleken och ändringsdatumen. Med synkronisering kan du minimera möjligheten att använda inaktuella filer.
rsync har återställningskapacitet. Om du till exempel kopierar en stor fil och har överföringsproblem rsync kan du återuppta från där den slutade.
rsync är kostnadsfri och lätt att implementera. Den har funktioner utöver de som vi beskriver här. Det gör att du kan upprätta ett synkroniserat filsystem i Azure baserat på dina lokala data.
rsync har också begränsningar som vi bör nämna. Först är verktyget entrådat. Den kan bara köra en åtgärd i taget och kan inte parallellisera dataåtkomst. Kopieringsverktyget cp är också entrådat. De här verktygen är därför inte optimerade för storskaliga kopierings-/synkroniseringsåtgärder som omfattar stora mängder data och en kort tidsperiod. Du måste också köra verktyget för att synkronisera data. Att köra verktyget ökar komplexiteten i din miljö eftersom du måste se till att det körs enligt dina tidsramskrav. Du kanske vill schemalägga ett skript som innehåller rsync, till exempel. Den här metoden kräver att du lägger till loggning av skriptet om det skulle uppstå problem. Det innebär också att du måste hålla utkik efter problemen. Komplexitetsnivån kan växa snabbt.
Om du kör en kommersiell NAS-lösning finns det synkroniseringsverktyg på servernivå som du kan köpa som är mer avancerade och ger flertrådade prestanda. När de har aktiverats och konfigurerats fungerar dessa verktyg alltid och synkroniserar data mellan en eller flera källor och mål.
Kopiering och synkronisering överför fullständiga kopior av källdata. Fullständig filöverföring kan vara bra för mindre datamängder eller filstorlekar. Det kan medföra betydande fördröjningar om källdata består av många stora filer. Ju mer data du överför, desto längre tid tar överföringen. Synkronisering säkerställer att du bara lägger till nya filer i molnet. Men filerna måste fortfarande överföras i sin helhet. I vissa fall kanske inte HPC-arbetsbelastningen kräver hela en viss uppsättning filer. Det kan kräva åtkomst till endast specifika områden av filer.
Cachelagring av data är en tredje metod för att lägga till data i Azure. Cachelagring avser hämtning och presentation av fildata via en cache. Cacheminnet kan finnas på enskilda lokala klienter, eller så kan det vara en distribuerad cache som hanterar alla HPC-datorer. Cacheminnen används normalt för att minimera svarstiden, så att placera en cache vid en svarstidsgräns är en optimal metod för att hantera data. Du kan till exempel cachelagrar databegäranden över en WAN-anslutning genom att placera en distribuerad cache i Azure-beräkning som är ansluten till lokal lagring via WAN-länken.
I den här modulen refererar vi specifikt till filcachelagring, där själva cachen anger begäranden från datorer. Den hämtar data från en serverdelslagringsmiljö (till exempel en NFS NAS-miljö) och presenterar dessa data för klienterna.
Cachelagringskraften är dubbel. För det första hämtar cacheminnen inte hela filer. En cache hämtar en begärd delmängd, eller byteintervall, av filer i stället för hela filer. Hämtningen baseras på klientbegäranden för dessa byteintervall. Den här metoden för att hämta minimerar prestandastraff för att hämta hela en stor fil när endast en liten del av filen behövs.
För det andra optimerar cacheminnen upprepad åtkomst för data som efterfrågas ofta. När ett byteintervall finns i cacheminnet går det snabbt att begära dessa data senare. Den enda långsamma hämtningen är den första hämtningen. Du kan få betydande fördelar när du kör ett stort antal HPC-klienter/trådar som har åtkomst till en gemensam uppsättning filer.
Cachelagring ger en annan fördel för hybridscenarier. Data lagras endast tillfälligt i Azure (i cacheminnet). Och den lagras bara under driften av HPC-arbetsbelastningen. Så att du kan minska de logistiska kostnaderna för mer konkret dataflytt till Azure. Du kan isolera problem med datasekretess och säkerhet till cachen och själva HPC-datorerna.
Slutligen erbjuder vissa cachelagringslösningar vad som kallas en attributkontroll. Precis som synkronisering kontrollerar cachen regelbundet attributen för filen vid källan och hämtar byteintervall när filändringen är större vid källan. Den här arkitekturen säkerställer att din HPC-miljö alltid fungerar med de senaste data.