Parallella filsystem
NFS utvecklades från företaget. Den är utformad för att hantera samtidig filåtkomst i växande skala. Men det finns en övre gräns för prestanda och skalning som du kan få med NFS-lösningar. Det finns också klasser av arbetsbelastningar som kräver mycket större parallell åtkomst till filer, inklusive möjligheten för flera samtidiga processer att skriva till någon del av en fil.
Behovet av att läsa och skriva i stor skala har ökat avsevärt under de senaste två decennierna. Parallella filsystemlösningar är det främsta valet för att påskynda de största arbetsbelastningarna med höga prestanda. Parallella filsystem har sitt ursprung i superdatorer. De distribueras nu i stor utsträckning för olika scenarier. Till exempel seismiska bearbetnings- och tolkningslösningar som används av stora olje- och gasföretag och sekundär/tertiär analys av genomiska data.
I den här lektionen presenteras en lätt behandling av parallella filsystem. Om du har kört sådana arbetsbelastningar är du förmodligen väl bekant med de här lösningarnas drivrutiner, behov och arkitektur. Det finns ett grått område mellan distribuerade NAS-lösningar som hanterar NFS och parallella filsystem. Användningen av parallella filsystem kan bättre uppfylla dina krav.
När du har slutfört den här lektionen är du mer bekant med huvudfunktionerna i parallella filsystem.
Parallella filsystem har historiskt sett varit en fullständig funktionsklass som kräver djupgående kunskaper om program-I/O. Den här informationen finns här för att skapa förståelse, inte expertis.
Distribuerad NAS (NFS) jämfört med parallella filsystem
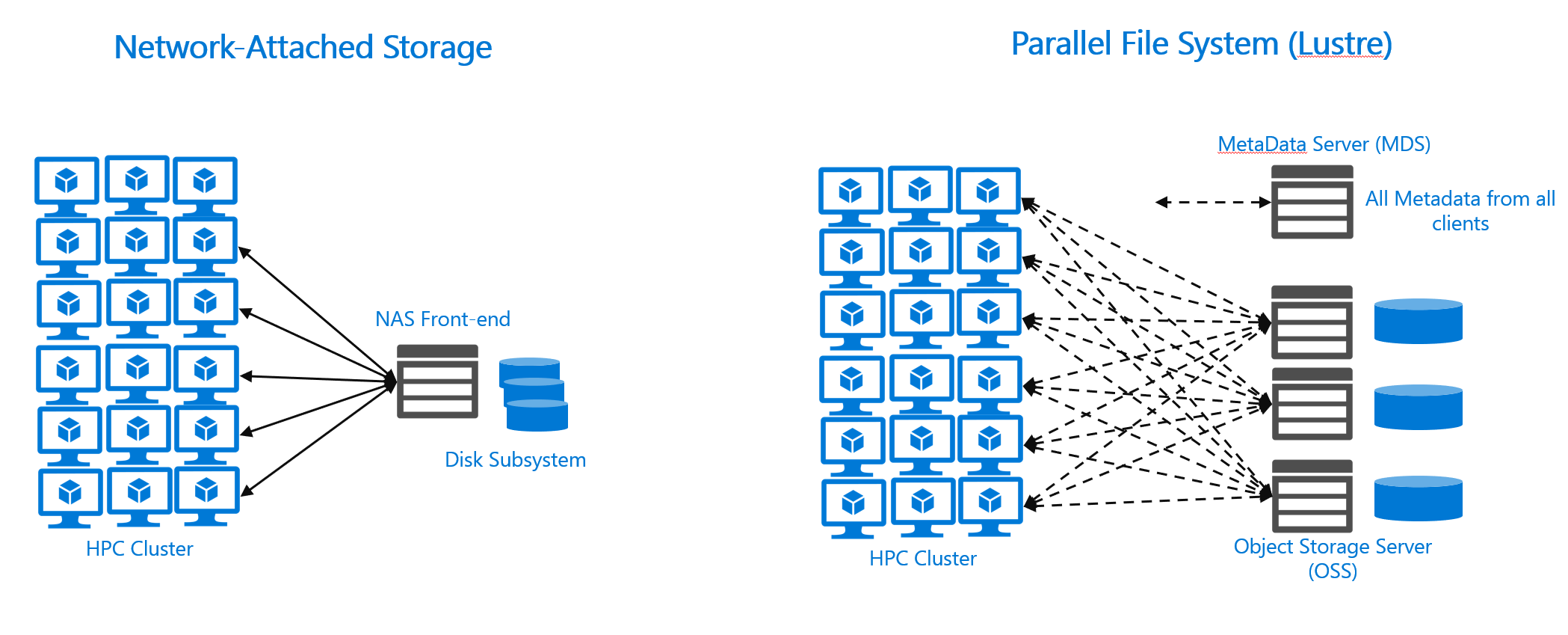
Både distribuerade NAS- och parallella filsystem är delade filsystem. Flera klienter läser filer samtidigt, filer skrivs till och låses, metadata kan ändras med mera.
Du kan skala båda dessa system genom att lägga till eller uppgradera maskinvarutekniker för lagring, lägga till klientdelsservrar för att skala klientåtkomst eller förbättra nätverksanslutningen.
Parallell I/O
Parallella filsystem delar upp filer i diskreta block eller ränder och distribuerar dessa filer över flera lagringsservrar. Det finns distribuerade filsystem som strimlar data. Skillnaden är att parallella filsystem sedan exponerar ränder direkt för klienter, via kommunikation med själva värdlagringsservrarna. Striping möjliggör betydande parallell I/O över ett standard distribuerat NAS-system. NFS-klienter som körs med de vanligaste skalbara NAS-miljöerna måste komma åt en fil via en enda server. När klienter får åtkomst till en enskild server orsakar det problem när antalet samtidiga begäranden växa utöver vad servern kan hantera. Och den parallella filsystemmetoden för parallell åtkomst och striping gör dem till en bra lösning för arbetsflöden som behöver komma åt stora filer över ett stort antal samtidiga klienter.
Här är tre stora parallella filsystem:
- IBM:s GPFS, känd som Spectrum Scale
- Lustre, som är öppen källkod men har vissa kommersiella implementeringar
- BeeGFS
Dessa system uppnår parallell I/O på olika sätt. GPFS använder servrar som kallas nätverkslagringsenheter (NSDs) som ansluter till ett SAN (storprestanda lagringsareanätverk). GPFS-servrar har rådisk-I/O som underliggande lagringssystem. BeeGFS har många av samma arkitektoniska komponenter som Lustre, men det har också en robust distribuerad metadataarkitektur. BeeOND, förkortning för BeeGFS On Demand, aktiverar BeeGFS-miljöer på begäran som använder lagring på varje klient. Sådana tillfälliga filsystemmiljöer kan användas för burst-buffring.
I båda fallen kan dock parallella filsystem skalas genom att lägga till fler lagringsservrar, vilket i sin tur ger mer parallell I/O till klienter. Och det totala antalet klienter kan vara stort, vilket sträcker sig till tiotusentals.
Metadata
NFS-klienter samverkar direkt med en NFS-server, som tillhandahåller metadatainformation och hämtar data för klienterna. Du måste storleksanpassa serverkomponenten enligt antalet klienter och den förväntade trafikhastigheten. Den här komponenten kan bli en flaskhals. NAS-leverantörer kan implementera vissa metadataoptimeringar, men de flesta NFS-implementeringar känner inte igen en separat metadatatjänst.
Parallella filsystem implementerar däremot vanligtvis strategier för bättre skalning av klientdataåtkomst. Lustre implementerar till exempel en separat metadataserver (MDS). Klienter hämtar alla metadata från systemet. Och Lustre-klienter kan direkt komma åt lagringsservern där en viss fil finns och kan läsa/skriva flera parallella trådar. Med den här metoden kan arkitekturen skala bandbredd baserat på antalet distribuerade lagringsservrar.
Blockstorlek
Vi diskuterade blockstorlek tidigare i samband med NFS. Blockstorlekar för parallella filsystem kan vara större än NFS-blockstorlekar. Den förvalda storleken för rsize/wsize för NFS-klienter är vanligtvis 64 000. Lustre har till exempel blockstorlekar i megabyte. Den här större storleken har två effekter. För det första är läsning/skrivning av stora filer överlägsen i ett parallellt filsystem. Men parallella filsystem har liten fördel när filstorlekarna är små och antalet filer är stort.
Komplexitet
Distribuerade filsystemlösningar som kör NFS är enkla att konfigurera och köra för vanliga användningsfall. Precis som alla system kan de justeras för prestanda, inklusive att ändra blockstorlekar för klient-server (rsize/wsize) baserat på arbetsbelastningar.
Parallella filsystem fungerar vanligtvis mot komplexa arbetsbelastningar i skalningsmiljöer. De är mer benägna att kräva konfiguration och justering för att säkerställa tillräcklig prestanda och skala.
Distributionsöverväganden
Azure erbjuder flera skräddarsydda lösningar för parallella filsystem. Du kan gå till Azure Marketplace för att se alternativen, däribland BeeGFS och Lustre. (Sök efter Whamcloud.) Du kan också installera Lustre på vanliga virtuella Linux-datorer, eller så kan du använda ARM-mallarna (Azure Resource Manager) som finns på Azure-snabbstart webbplats.