Konfigurationsalternativ för HDInsight
HDInsight har ett brett utbud av OSS-tekniker inbäddade i den som kan användas för att hantera scenarier för både direktuppspelning och batchdata, vilket är termer som definieras i Lambda-arkitekturer. I den här arkitekturmodellen finns det en frekvent sökväg för data och en kall datasökväg. Den frekventa sökvägen till data genereras i realtid av enheter, sensorer eller program och dataanalys utförs nästan i realtid, vilket ofta kallas strömmande data. En kall datasökväg är när data flyttas i batchar, vanligtvis från andra datalager och ofta kallas batchdata.
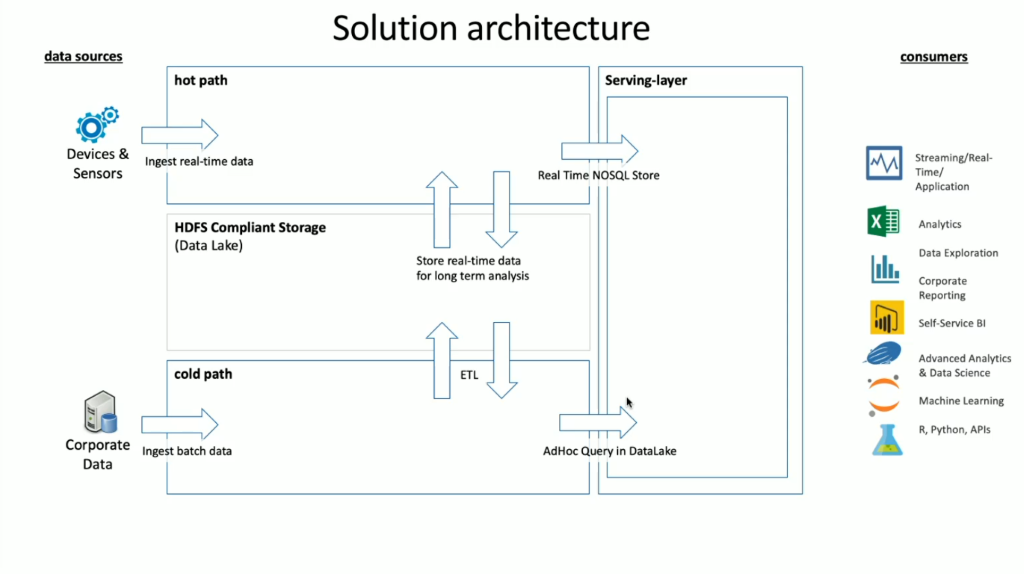
När du implementerar HDInsight lagras data i ett kompatibelt Hadoop Distributed File System (HDFS). I Azure används Data Lake Gen2 vanligtvis som ett datalager eftersom det är HDFS-kompatibelt. Data från den frekventa sökvägen och den kalla sökvägen efter bearbetning lagras i ett centraliserat datalager med namnet Data Lake. Datasjön i sig kan delas upp för att lagra data i olika fack, vilket kan definieras av tillståndet för data (landningszon, omvandlingszon osv.), åtkomstkrav (frekvent, varm och kall) och affärsgrupper. Serveringslagret är det sista facket i datasjön som innehåller data i ett format som är redo för förbrukning av olika typer av konsumenter.
Kritiskt är att beräkningsaspekten i HDInsight hanterar bearbetningen av strömnings- eller batchdata och kan variera beroende på vilken klustertyp du väljer när du etablerar ett HDInsight-kluster. HDInsight erbjuder tjänsterna i enskilda klusteralternativ enligt följande tabell.
| Klustertyp | Beskrivning |
|---|---|
| Apache Hadoop | Ett ramverk som använder HDFS och en enkel MapReduce-programmeringsmodell för att bearbeta och analysera batchdata. |
| Apache Spark | Ett ramverk för parallellbearbetning med öppen källkod som stöder intern bearbetning för att höja prestandan hos program för stordataanalys. |
| HBase | En NoSQL-databas som bygger på Hadoop och ger slumpmässig åtkomst och stark konsekvens för stora mängder ostrukturerade och delstrukturerade data – potentiellt miljarder rader gånger miljoner kolumner. |
| Apache Interaktiv fråga | Minnesintern cachelagring för interaktiva och snabba Hive-frågor. |
| Apache Kafka | En öppen källkodsplattform som används för att skapa strömmande datapipelines och program. Kafka tillhandahåller även en meddelandeköfunktion med vilken du kan publicera och prenumerera på dataströmmar. |
Därför är det viktigt att välja rätt klustertyp för att uppfylla det affärsfall som du försöker lösa. Oavsett vilken klustertyp som väljs läggs även ytterligare komponenter med öppen källkod till i klustret för att ge ytterligare funktioner, inklusive:
Hadoop-hantering
HCatalog – ett lager för tabell- och lagringshantering för Hadoop
Apache Ambari – Underlättar hantering och övervakning av ett Apache Hadoop-kluster
Apache Oozie – Ett schemaläggningssystem för arbetsflöden för att hantera Apache Hadoop-jobb
Apache Hadoop YARN – Hanterar resurshantering och schemaläggning/övervakning av jobb
Apache ZooKeeper – en centraliserad tjänst för att underhålla konfigurationsinformation, namnge, tillhandahålla distribuerad synkronisering och tillhandahålla grupptjänster.
Databehandling
Apache Hadoop MapReduce – ett ramverk för att enkelt skriva program, som bearbetar stora mängder data
Apache Tez – ett programramverk för bearbetning av data
Apache Hive – Underlättar hantering av stora datamängder som finns i distribuerad lagring med SQL
Dataanalys
Apache Pig – Tillhandahåller ett abstraktionslager över MapReduce för att analysera stora datamängder
Apache Phoenix – Aktiverar OLTP och driftanalys i Hadoop
Apache Mahout – Ett Algebra-ramverk för att skapa egna algoritmer
Kommentar
Azure Data Lake Gen1 och Azure Blob Storage stöds i skrivande stund datalagringslager för HDInsight. Du bör titta på migrera dessa data till Azure Data Lake Gen2 eftersom det är den rekommenderade lagringsplattformen för Spark och Hadoop, samt som standardval för HBase.