Förstå informationslager i Infrastrukturresurser
Fabric's Lakehouse är en samling filer, mappar, tabeller och genvägar som fungerar som en databas över en datasjö. Den används av Spark-motorn och SQL-motorn för bearbetning av stordata och har funktioner för ACID-transaktioner när du använder deltaformaterade tabeller med öppen källkod.
Med fabrics informationslagerupplevelse kan du övergå från sjövyn över Lakehouse (som stöder datateknik och Apache Spark) till de SQL-upplevelser som ett traditionellt informationslager skulle tillhandahålla. Lakehouse ger dig möjlighet att läsa tabeller och använda SQL-analysslutpunkten, medan informationslagret gör att du kan ändra data.
I informationslagermiljön ska du modellera data med hjälp av tabeller och vyer, köra T-SQL för att fråga efter data i informationslagret och Lakehouse, använda T-SQL för att utföra DML-åtgärder på data i informationslagret och hantera rapporteringslager som Power BI.
Nu när du förstår de grundläggande arkitekturprinciperna för ett relationsdatalagerschema ska vi utforska hur du skapar ett informationslager.
Beskriva ett informationslager i Infrastrukturresurser
I datalagerupplevelsen i Fabric kan du skapa ett relationslager ovanpå fysiska data i Lakehouse och exponera det för analys- och rapporteringsverktyg. Du kan skapa ditt informationslager direkt i Fabric från skapa hubben eller på en arbetsyta. När du har skapat ett tomt lager kan du lägga till objekt i det.
När ditt lager har skapats kan du skapa tabeller med hjälp av T-SQL direkt i infrastrukturgränssnittet.
Mata in data i informationslagret
Det finns några sätt att mata in data i ett infrastrukturlager, inklusive pipelines, dataflöden, frågor mellan databaser och kommandot COPY INTO. Efter inmatning blir data tillgängliga för analys av flera företagsgrupper, som kan använda funktioner som frågor mellan databaser och delning för att komma åt dem.
Skapa tabeller
Om du vill skapa en tabell i informationslagret kan du använda SQL Server Management Studio (SSMS) eller en annan SQL-klient för att ansluta till informationslagret och köra en CREATE TABLE-instruktion. Du kan också skapa tabeller direkt i användargränssnittet för infrastrukturresurser.
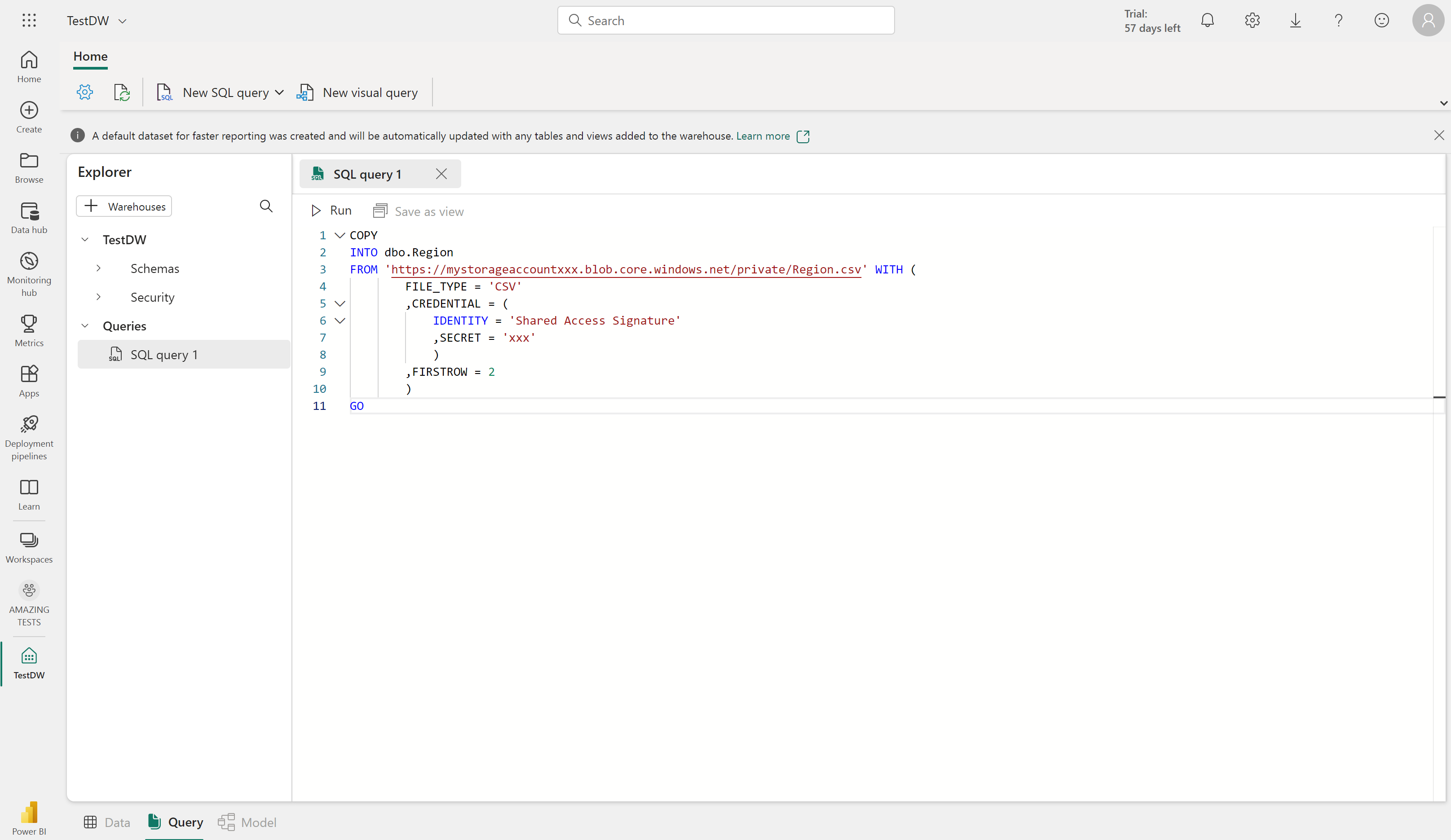
Du kan kopiera data från en extern plats till en tabell i informationslagret med hjälp av syntaxen COPY INTO . Till exempel:
COPY INTO dbo.Region
FROM 'https://mystorageaccountxxx.blob.core.windows.net/private/Region.csv' WITH (
FILE_TYPE = 'CSV'
,CREDENTIAL = (
IDENTITY = 'Shared Access Signature'
, SECRET = 'xxx'
)
,FIRSTROW = 2
)
GO
Den här SQL-frågan läser in data från en CSV-fil som lagras i Azure Blob Storage till en tabell med namnet "Region" i informationslagret för infrastrukturresurser.
Klona tabeller
Du kan skapa nollkopieringstabellkloer med minimala lagringskostnader i ett informationslager. Dessa kloner är i princip repliker av tabeller som skapats genom att kopiera metadata medan de fortfarande refererar till samma datafiler i OneLake. Det innebär att underliggande data som lagras som parquet-filer inte dupliceras, vilket bidrar till att spara lagringskostnader.
Tabellkloer är särskilt användbara i flera scenarier.
- Utveckling och testning: Kloner gör det möjligt för utvecklare och testare att skapa kopior av tabeller i lägre miljöer, vilket underlättar utveckling, felsökning, testning och valideringsprocesser.
- Dataåterställning: I händelse av en misslyckad version eller skadade data kan tabellkloer behålla det tidigare datatillståndet, vilket möjliggör dataåterställning.
- Historisk rapportering: De hjälper dig att skapa historiska rapporter som återspeglar datastatus vid specifika tidpunkter och bevarar data vid specifika affärsmilstolpar.
Du kan skapa en tabellkloning med hjälp av CREATE TABLE AS CLONE OF T-SQL-kommandot.
Mer information om tabellkloningar finns i Självstudie: Klona en tabell med T-SQL i Microsoft Fabric.
Tabellöverväganden
När du har skapat tabeller i ett informationslager är det viktigt att överväga processen med att läsa in data i dessa tabeller. En vanlig metod är att använda mellanlagringstabeller. I Infrastruktur kan du använda T-SQL-kommandon för att läsa in data från filer till mellanlagringstabeller i informationslagret.
Mellanlagringstabeller är tillfälliga tabeller som kan användas för att utföra datarensning, datatransformeringar och dataverifiering. Du kan också använda mellanlagringstabeller för att läsa in data från flera källor till en enda måltabell.
Vanligtvis utförs datainläsning som en periodisk batchprocess där infogningar och uppdateringar av informationslagret samordnas för att ske med jämna mellanrum (till exempel dagligen, varje vecka eller varje månad).
I allmänhet bör du implementera en informationslagerinläsningsprocess som utför uppgifter i följande ordning:
- Mata in de nya data som ska läsas in i en datasjö och tillämpa rensning eller transformeringar före belastning efter behov.
- Läs in data från filer i mellanlagringstabeller i informationslagret för relationer.
- Läs in dimensionstabellerna från dimensionsdata i mellanlagringstabellerna, uppdatera befintliga rader eller infoga nya rader och generera surrogatnyckelvärden efter behov.
- Läs in faktatabellerna från faktadata i mellanlagringstabellerna och leta upp lämpliga surrogatnycklar för relaterade dimensioner.
- Utför optimering efter belastningen genom att uppdatera index och tabelldistributionsstatistik.
Om du har tabeller i lakehouse och vill kunna köra frågor mot dem i ditt lager – men inte göra ändringar – med ett Infrastrukturdatalager behöver du inte kopiera data från lakehouse till informationslagret. Du kan köra frågor mot data i lakehouse direkt från informationslagret med hjälp av frågor mellan databaser.
Viktigt!
Att arbeta med tabeller i Informationslagret för infrastrukturresurser har för närvarande vissa begränsningar. Mer information finns i Tabeller i datalager i Microsoft Fabric .