Förstå grunderna i informationslager
Processen att skapa ett modernt informationslager består vanligtvis av:
- Datainmatning – flytta data från källsystem till ett informationslager.
- Datalagring – lagra data i ett format som är optimerat för analys.
- Databearbetning – omvandla data till ett format som är redo för förbrukning med analysverktyg.
- Dataanalys och leverans – analysera data för att få insikter och leverera dessa insikter till verksamheten.
Med Microsoft Fabric kan datatekniker och analytiker mata in, lagra, transformera och visualisera data i ett enda verktyg med både låg kod och traditionell upplevelse.
Förstå infrastrukturresursernas informationslagerupplevelse
Fabrics informationslager är ett relationsdatalager som stöder de fullständiga transaktions-T-SQL-funktioner som du kan förvänta dig från ett företags informationslager. Det är ett fullständigt hanterat, skalbart och högtillgängligt informationslager som kan användas för att lagra och fråga efter data i Lakehouse. Med hjälp av informationslagret har du fullständig kontroll över att skapa tabeller, läsa in, transformera och köra frågor mot data med hjälp av antingen Fabric-portalen eller T-SQL-kommandon. Du kan använda SQL för att fråga och analysera data, eller använda Spark för att bearbeta data och skapa maskininlärningsmodeller.
Informationslager i Fabric underlättar samarbete mellan datatekniker och dataanalytiker och arbetar tillsammans i samma upplevelse. Datatekniker skapar ett relationslager ovanpå data i Lakehouse, där analytiker kan använda T-SQL och Power BI för att utforska data.
Utforma ett informationslager
Precis som alla relationsdatabaser innehåller Fabrics informationslager tabeller för att lagra dina data för analys senare. De här tabellerna är oftast ordnade i ett schema som är optimerat för flerdimensionell modellering. I den här metoden grupperas numeriska data relaterade till händelser (t.ex. försäljningsorder) efter olika attribut (t.ex. datum, kund, butik). Du kan till exempel analysera det totala belopp som betalats för försäljningsorder som inträffat vid ett visst datum eller i ett visst lager.
Tabeller i ett informationslager
Tabeller i ett informationslager organiseras vanligtvis på ett sätt som stöder effektiv och effektiv analys av stora mängder data. Den här organisationen kallas ofta för dimensionsmodellering, vilket innebär att strukturera tabeller till faktatabeller och dimensionstabeller.
Faktatabeller innehåller de numeriska data som du vill analysera. Faktatabeller har vanligtvis ett stort antal rader och är den primära datakällan för analys. En faktatabell kan till exempel innehålla det totala belopp som betalats för försäljningsorder som inträffat vid ett visst datum eller i ett visst lager.
Dimensionstabeller innehåller beskrivande information om data i faktatabellerna. Dimensionstabeller har vanligtvis ett litet antal rader och används för att ge kontext för data i faktatabellerna. En dimensionstabell kan till exempel innehålla information om de kunder som lade försäljningsorder.
Förutom attributkolumner innehåller en dimensionstabell en unik nyckelkolumn som unikt identifierar varje rad i tabellen. I själva verket är det vanligt att en dimensionstabell innehåller två nyckelkolumner:
- En surrogatnyckel är en unik identifierare för varje rad i dimensionstabellen. Det är ofta ett heltalsvärde som genereras automatiskt av databashanteringssystemet när en ny rad infogas i tabellen.
- En alternativ nyckel är ofta en naturlig nyckel eller affärsnyckel som identifierar en specifik instans av en entitet i transaktionskällans system , till exempel en produktkod eller ett kund-ID.
Du behöver både surrogatnycklar och alternativa nycklar i ett informationslager eftersom de har olika syften. Surrogatnycklar är specifika för informationslagret och hjälper till att upprätthålla konsekvens och noggrannhet i data. Alternativa nycklar är å andra sidan specifika för källsystemet och hjälper till att upprätthålla spårbarheten mellan informationslagret och källsystemet.
Särskilda typer av dimensionstabeller
Särskilda typer av dimensioner ger ytterligare kontext och möjliggör mer omfattande dataanalys.
Tidsdimensioner ger information om tidsperioden då en händelse inträffade. Med den här tabellen kan dataanalytiker aggregera data över tidsintervall. En tidsdimension kan till exempel innehålla kolumner för året, kvartalet, månaden och dagen där en försäljningsorder har placerats.
Dimensioner som ändras långsamt är dimensionstabeller som spårar ändringar i dimensionsattribut över tid, till exempel ändringar i en kunds adress eller en produkts pris. De är viktiga i ett informationslager eftersom de gör det möjligt för användare att analysera och förstå ändringar i data över tid. Långsamt föränderliga dimensioner säkerställer att data förblir uppdaterade och korrekta, vilket är absolut nödvändigt för att fatta bra affärsbeslut.
Schemadesign för informationslager
I de flesta transaktionsdatabaser som används i affärsprogram normaliseras data för att minska dupliceringen. I ett informationslager avnormaliseras dock dimensionsdata vanligtvis för att minska antalet kopplingar som krävs för att köra frågor mot data.
Ofta ordnas ett informationslager som ett stjärnschema, där en faktatabell är direkt relaterad till dimensionstabellerna, som du ser i det här exemplet:
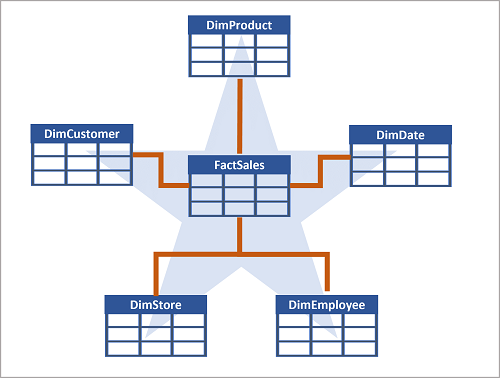
Du kan använda attributen för något för att gruppera tal i faktatabellen på olika nivåer. Du kan till exempel hitta de totala försäljningsintäkterna för en hel region eller bara för en kund. Informationen för varje nivå kan lagras i samma dimensionstabell.
Dricks
Mer information om hur du utformar star-scheman för Infrastruktur finns i Vad är ett star-schema?
Om det finns många nivåer eller om viss information delas av olika saker kan det vara klokt att använda ett snowflake-schema i stället. Här är ett exempel:
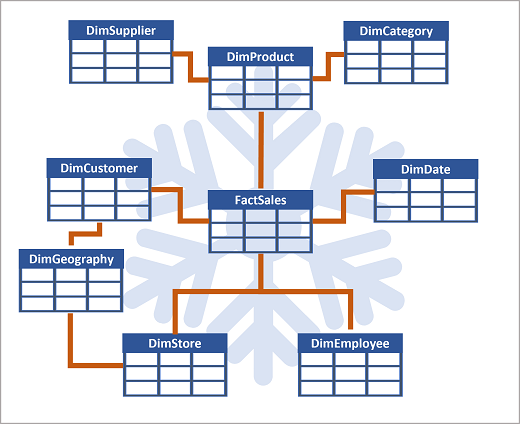
I det här fallet har tabellen DimProduct delats upp (normaliserats) för att skapa separata dimensionstabeller för produktkategorier och leverantörer.
- Varje rad i tabellen DimProduct innehåller nyckelvärden för motsvarande rader i tabellerna DimCategory och DimSupplier.
En DimGeography-tabell har lagts till som innehåller information om var kunder och butiker finns.
- Varje rad i tabellerna DimCustomer och DimStore innehåller ett nyckelvärde för motsvarande rad i tabellen DimGeography.