Vad är språkmodeller?
Generativa AI-program drivs av språkmodeller, som är en specialiserad typ av maskininlärningsmodell som du kan använda för att utföra nlp-uppgifter (natural language processing ), inklusive:
- Fastställa sentiment eller på annat sätt klassificera text på naturligt språk.
- Sammanfattar text.
- Jämföra flera textkällor för semantisk likhet.
- Genererar ett nytt naturligt språk.
Även om de matematiska principerna bakom dessa språkmodeller kan vara komplexa, kan en grundläggande förståelse av arkitekturen som används för att implementera dem hjälpa dig att få en konceptuell förståelse för hur de fungerar.
Transformeringsmodeller
Maskininlärningsmodeller för bearbetning av naturligt språk har utvecklats under många år. Dagens banbrytande stora språkmodeller baseras på transformeringsarkitekturen, som bygger på och utökar vissa tekniker som har visat sig vara framgångsrika i modellering av vokabulärer för att stödja NLP-uppgifter - och särskilt för att generera språk. Transformeringsmodeller tränas med stora mängder text, vilket gör att de kan representera de semantiska relationerna mellan ord och använda dessa relationer för att fastställa troliga textsekvenser som är meningsfulla. Transformatormodeller med tillräckligt stor vokabulär kan generera språksvar som är svåra att skilja från mänskliga svar.
Transformerarmodellarkitektur består av två komponenter eller block:
- Ett kodarblock som skapar semantiska representationer av träningsförrådet.
- Ett avkodarblock som genererar nya språksekvenser.
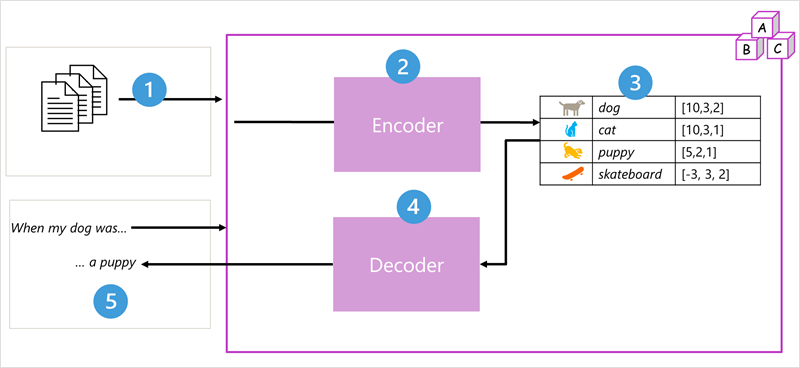
- Modellen tränas med en stor mängd text på naturligt språk, som ofta hämtas från Internet eller andra offentliga textkällor.
- Textsekvenserna är uppdelade i token (till exempel enskilda ord) och kodarblocket bearbetar dessa tokensekvenser med hjälp av en teknik som kallas uppmärksamhet för att fastställa relationer mellan token (till exempel vilka token som påverkar förekomsten av andra token i en sekvens, olika token som ofta används i samma kontext och så vidare.)
- Utdata från kodaren är en samling vektorer (numeriska matriser med flera värden) där varje element i vektorn representerar ett semantiskt attribut för tokens. Dessa vektorer kallas inbäddningar.
- Avkodarblocket fungerar på en ny sekvens med texttoken och använder de inbäddningar som genereras av kodaren för att generera lämpliga naturliga språkutdata.
- Med en indatasekvens som "När min hund var" kan modellen till exempel använda uppmärksamhetstekniken för att analysera indatatoken och de semantiska attribut som kodas i inbäddningarna för att förutsäga en lämplig avslutning av meningen, till exempel "en valp".
I praktiken varierar de specifika implementeringarna av arkitekturen – till exempel använder modellen Bidirectional Encoder Representations from Transformers (BERT) som utvecklats av Google för att stödja sökmotorn endast kodarblocket, medan GPT-modellen (Generative Pretrained Transformer) som utvecklats av OpenAI endast använder avkodarblocket.
En fullständig förklaring av alla aspekter av transformeringsmodeller ligger utanför den här modulens omfång, men en förklaring av några av de viktigaste elementen i en transformerare kan hjälpa dig att få en uppfattning om hur de stöder generativ AI.
Tokenisering
Det första steget i att träna en transformeringsmodell är att dela upp träningstexten i token – med andra ord identifiera varje unikt textvärde. För enkelhetens skull kan du tänka på varje distinkt ord i träningstexten som en token (men i verkligheten kan token genereras för partiella ord eller kombinationer av ord och skiljetecken).
Tänk till exempel på följande mening:
I heard a dog bark loudly at a cat
Om du vill tokenisera den här texten kan du identifiera varje diskret ord och tilldela token-ID:t till dem. Till exempel:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
Meningen kan nu representeras med token: {1 2 3 4 5 6 7 3 8}. På samma sätt kunde meningen "Jag hörde en katt" representeras som {1 2 3 8}.
När du fortsätter att träna modellen läggs varje ny token i träningstexten till i vokabulären med lämpliga token-ID:n:
- meow (9)
- skateboard (10)
- och så vidare...
Med en tillräckligt stor uppsättning träningstext kan ett ordförråd med tusentals token kompileras.
Inbäddningar
Även om det kan vara praktiskt att representera token som enkla ID:er – i princip skapar ett index för alla ord i vokabulären, berättar de ingenting om innebörden av orden eller relationerna mellan dem. För att skapa ett ordförråd som kapslar in semantiska relationer mellan token definierar vi kontextuella vektorer, så kallade inbäddningar, för dem. Vektorer är numeriska representationer av information med flera värden, till exempel [10, 3, 1] där varje numeriskt element representerar ett visst attribut för informationen. För språktoken representerar varje element i en tokens vektor något semantiskt attribut för token. De specifika kategorierna för elementen i vektorerna i en språkmodell bestäms under träningen baserat på hur ofta ord används tillsammans eller i liknande sammanhang.
Vektorer representerar linjer i flerdimensionellt utrymme och beskriver riktning och avstånd längs flera axlar (du kan imponera på dina matematiker genom att kalla dessa amplitud och storlek). Det kan vara användbart att tänka på elementen i en inbäddningsvektor för en token som representerar steg längs en sökväg i flerdimensionellt utrymme. En vektor med tre element representerar till exempel en sökväg i ett tredimensionellt utrymme där elementvärdena anger de enheter som färdas framåt/bakåt, vänster/höger och upp/ned. Sammantaget beskriver vektorn sökvägens riktning och avstånd från ursprung till slut.
Elementen i token i inbäddningsutrymmet representerar ett semantiskt attribut för token, så att semantiskt liknande token bör resultera i vektorer som har en liknande orientering – med andra ord pekar de i samma riktning. En teknik som kallas cosinisk likhet används för att avgöra om två vektorer har liknande riktningar (oavsett avstånd) och representerar därför semantiskt länkade ord. Som ett enkelt exempel antar vi att inbäddningarna för våra token består av vektorer med tre element, till exempel:
- 4 ("hund"): [10,3,2]
- 8 ("katt"): [10,3,1]
- 9 ("valp"): [5,2,1]
- 10 ("skateboard"): [-3,3,2]
Vi kan rita dessa vektorer i tredimensionellt utrymme, så här:
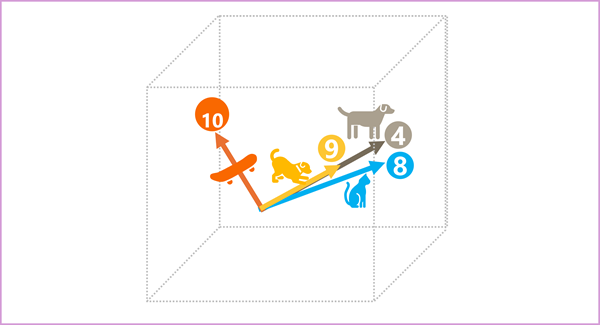
Inbäddningsvektorerna för "hund" och "valp" beskriver en väg i nästan identisk riktning, som också är ganska lik riktningen för "katt". Inbäddningsvektorn för "skateboard" beskriver dock resan i en helt annan riktning.
Kommentar
I föregående exempel visas en enkel exempelmodell där varje inbäddning bara har tre dimensioner. Verkliga språkmodeller har många fler dimensioner.
Det finns flera sätt att beräkna lämpliga inbäddningar för en viss uppsättning token, inklusive språkmodelleringsalgoritmer som Word2Vec eller kodarblocket i en transformeringsmodell.
Observera!
Kodaren och avkodarblocken i en transformeringsmodell innehåller flera lager som utgör det neurala nätverket för modellen. Vi behöver inte gå in på information om alla dessa lager, men det är användbart att överväga en av de typer av lager som används i båda blocken: uppmärksamhetslager . Uppmärksamhet är en teknik som används för att undersöka en sekvens med texttoken och försöka kvantifiera styrkan i relationerna mellan dem. I synnerhet handlar självuppmärksamhet om hur andra token runt en viss token påverkar tokens betydelse.
I ett kodarblock granskas varje token noggrant i kontexten och en lämplig kodning bestäms för dess vektorbäddning. Vektorvärdena baseras på relationen mellan token och andra token som den ofta visas med. Den här kontextualiserade metoden innebär att samma ord kan ha flera inbäddningar beroende på i vilken kontext det används – till exempel betyder "barken i ett träd" något annat än "Jag hörde en hundbark".
I ett avkodarblock används uppmärksamhetslager för att förutsäga nästa token i en sekvens. För varje token som genereras har modellen ett uppmärksamhetslager som tar hänsyn till sekvensen av token fram till den punkten. Modellen tar hänsyn till vilka av token som är mest inflytelserika när man överväger vad nästa token ska vara. Med tanke på sekvensen "Jag hörde en hund" kan uppmärksamhetsskiktet till exempel tilldela större vikt till tokens "heard" och "dog" när du överväger nästa ord i sekvensen:
Jag hörde en hund [bark]
Kom ihåg att uppmärksamhetsskiktet fungerar med numeriska vektorrepresentationer av token, inte den faktiska texten. I en avkodare börjar processen med en sekvens med token-inbäddningar som representerar texten som ska slutföras. Det första som händer är att ett annat positionskodningslager lägger till ett värde för varje inbäddning för att ange dess position i sekvensen:
- [1,5,6,2] (I)
- [2,9,3,1] (hört)
- [3,1,1,2] (a)
- [4,10,3,2] (hund)
Under träningen är målet att förutsäga vektorn för den sista token i sekvensen baserat på föregående token. Uppmärksamhetsskiktet tilldelar en numerisk vikt till varje token i sekvensen hittills. Det använder det värdet för att utföra en beräkning på de viktade vektorer som ger en uppmärksamhetspoäng som kan användas för att beräkna en möjlig vektor för nästa token. I praktiken använder en teknik som kallas multi-head-uppmärksamhet olika element i inbäddningarna för att beräkna flera uppmärksamhetspoäng. Ett neuralt nätverk används sedan för att utvärdera alla möjliga token för att fastställa den mest sannolika token som sekvensen ska fortsätta med. Processen fortsätter iterativt för varje token i sekvensen, och utdatasekvensen används hittills regressivt som indata för nästa iteration – och skapar i princip utdata en token i taget.
Följande animering visar en förenklad representation av hur detta fungerar – i verkligheten är de beräkningar som utförs av uppmärksamhetsskiktet mer komplexa. men principerna kan förenklas enligt följande:

- En sekvens med token-inbäddningar matas in i uppmärksamhetsskiktet. Varje token representeras som en vektor med numeriska värden.
- Målet i en avkodare är att förutsäga nästa token i sekvensen, som också är en vektor som justeras till en inbäddning i modellens vokabulär.
- Uppmärksamhetsskiktet utvärderar sekvensen hittills och tilldelar vikter till varje token för att representera deras relativa påverkan på nästa token.
- Vikterna kan användas för att beräkna en ny vektor för nästa token med en uppmärksamhetspoäng. Uppmärksamhet med flera huvud använder olika element i inbäddningarna för att beräkna flera alternativa token.
- Ett fullständigt anslutet neuralt nätverk använder poängen i de beräknade vektorerna för att förutsäga den mest sannolika token från hela vokabulären.
- De förutsagda utdata läggs till i sekvensen hittills, som används som indata för nästa iteration.
Under träningen är den faktiska sekvensen av token känd – vi maskerar bara de som kommer senare i sekvensen än den tokenposition som för närvarande övervägs. Precis som i alla neurala nätverk jämförs det förutsagda värdet för tokenvektorn med det faktiska värdet för nästa vektor i sekvensen och förlusten beräknas. Vikterna justeras sedan stegvis för att minska förlusten och förbättra modellen. När det används för slutsatsdragning (förutsäga en ny sekvens av token) tillämpar det tränade uppmärksamhetsskiktet vikter som förutsäger den mest sannolika token i modellens vokabulär som är semantiskt anpassad till sekvensen hittills.
Vad allt detta innebär är att en transformeringsmodell som GPT-4 (modellen bakom ChatGPT och Bing) är utformad för att ta in en textinmatning (kallas en prompt) och generera syntaktiskt korrekta utdata (kallas slutförande). I själva verket är modellens "magi" att den har förmågan att stränga en sammanhängande mening tillsammans. Den här möjligheten innebär inte någon "kunskap" eller "intelligens" från modellens sida. bara ett stort ordförråd och förmågan att generera meningsfulla sekvenser av ord. Det som gör en stor språkmodell som GPT-4 så kraftfull är dock den stora mängden data som den har tränats med (offentliga och licensierade data från Internet) och nätverkets komplexitet. Detta gör det möjligt för modellen att generera slutföranden som baseras på relationerna mellan ord i vokabulären som modellen har tränats på. genererar ofta utdata som inte kan skiljas från ett mänskligt svar på samma fråga.