Utforska vanliga element i dataströmbearbetningsarkitekturen
Det finns många tekniker som du kan använda för att implementera en dataströmbearbetningslösning, men även om specifik implementeringsinformation kan variera finns det vanliga element i de flesta strömningsarkitekturer.
En allmän arkitektur för dataströmbearbetning
Det enklaste är att en arkitektur på hög nivå för dataströmbearbetning ser ut så här:
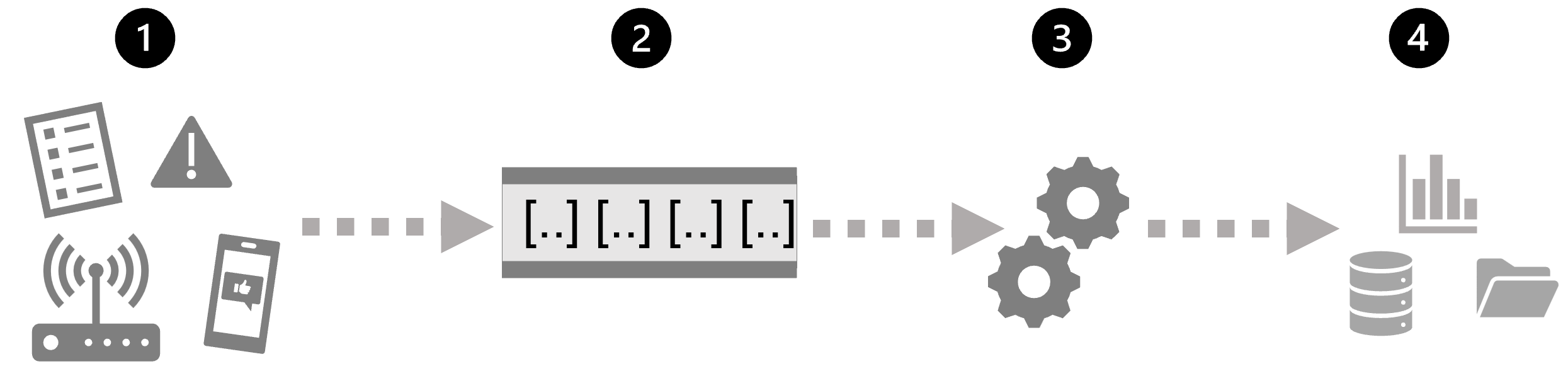
- En händelse genererar vissa data. Detta kan vara en signal som genereras av en sensor, ett meddelande på sociala medier som publiceras, en loggfilspost som skrivs eller någon annan förekomst som resulterar i vissa digitala data.
- Genererade data samlas in i en strömmande källa för bearbetning. I enkla fall kan källan vara en mapp i ett molndatalager eller en tabell i en databas. I mer robusta strömningslösningar kan källan vara en "kö" som kapslar in logik för att säkerställa att händelsedata bearbetas i ordning och att varje händelse endast bearbetas en gång.
- Händelsedata bearbetas ofta av en evig fråga som körs på händelsedata för att välja data för specifika typer av händelser, projektdatavärden eller aggregerade datavärden över tidsbaserade perioder (eller fönster) – till exempel genom att räkna antalet sensorutsläpp per minut.
- Resultatet av dataströmbearbetningsåtgärden skrivs till utdata (eller mottagare), som kan vara en fil, en databastabell, en instrumentpanel i realtid eller en annan kö för vidare bearbetning av en efterföljande nedströmsfråga.
Realtidsanalystjänster
Microsoft har stöd för flera tekniker som du kan använda för att implementera realtidsanalys av strömmande data, inklusive:
- Azure Stream Analytics: En PaaS-lösning (plattform som en tjänst) som du kan använda för att definiera strömmande jobb som matar in data från en strömningskälla, tillämpar en evig fråga och skriver resultatet till utdata.
- Spark Structured Streaming: Ett bibliotek med öppen källkod som gör att du kan utveckla komplexa strömningslösningar på Apache Spark-baserade tjänster, inklusive Microsoft Fabric och Azure Databricks.
- Microsoft Fabric: En databas- och analysplattform med höga prestanda som omfattar Dataingenjör ing, Data Factory, Datavetenskap, realtidsanalys, informationslager och databaser.
Källor för dataströmbearbetning
Följande tjänster används ofta för att mata in data för dataströmbearbetning i Azure:
- Azure Event Hubs: En datainmatningstjänst som du kan använda för att hantera köer med händelsedata för att säkerställa att varje händelse bearbetas i ordning, exakt en gång.
- Azure IoT Hub: En datainmatningstjänst som liknar Azure Event Hubs, men optimerad för att hantera händelsedata från IoT-enheter (Internet-of-things ).
- Azure Data Lake Store Gen 2: En mycket skalbar lagringstjänst som ofta används i scenarier för batchbearbetning , men kan också användas som källa för strömmande data.
- Apache Kafka: En datainmatningslösning med öppen källkod som ofta används tillsammans med Apache Spark.
Mottagare för dataströmbearbetning
Utdata från dataströmbearbetning skickas ofta till följande tjänster:
- Azure Event Hubs: Används för att köa bearbetade data för ytterligare nedströmsbearbetning.
- Azure Data Lake Store Gen 2, Microsoft OneLake eller Azure Blob Storage: Används för att bevara de bearbetade resultaten som en fil.
- Azure SQL Database, Azure Databricks eller Microsoft Fabric: Används för att bevara de bearbetade resultaten i en tabell för frågor och analys.
- Microsoft Power BI: Används för att generera datavisualiseringar i realtid i rapporter och instrumentpaneler.