Utforska pipelines för datainmatning
Nu när du förstår lite om arkitekturen för en storskalig datalagerlösning och några av de distribuerade bearbetningstekniker som kan användas för att hantera stora mängder data är det dags att utforska hur data matas in i ett analysdatalager från en eller flera källor.
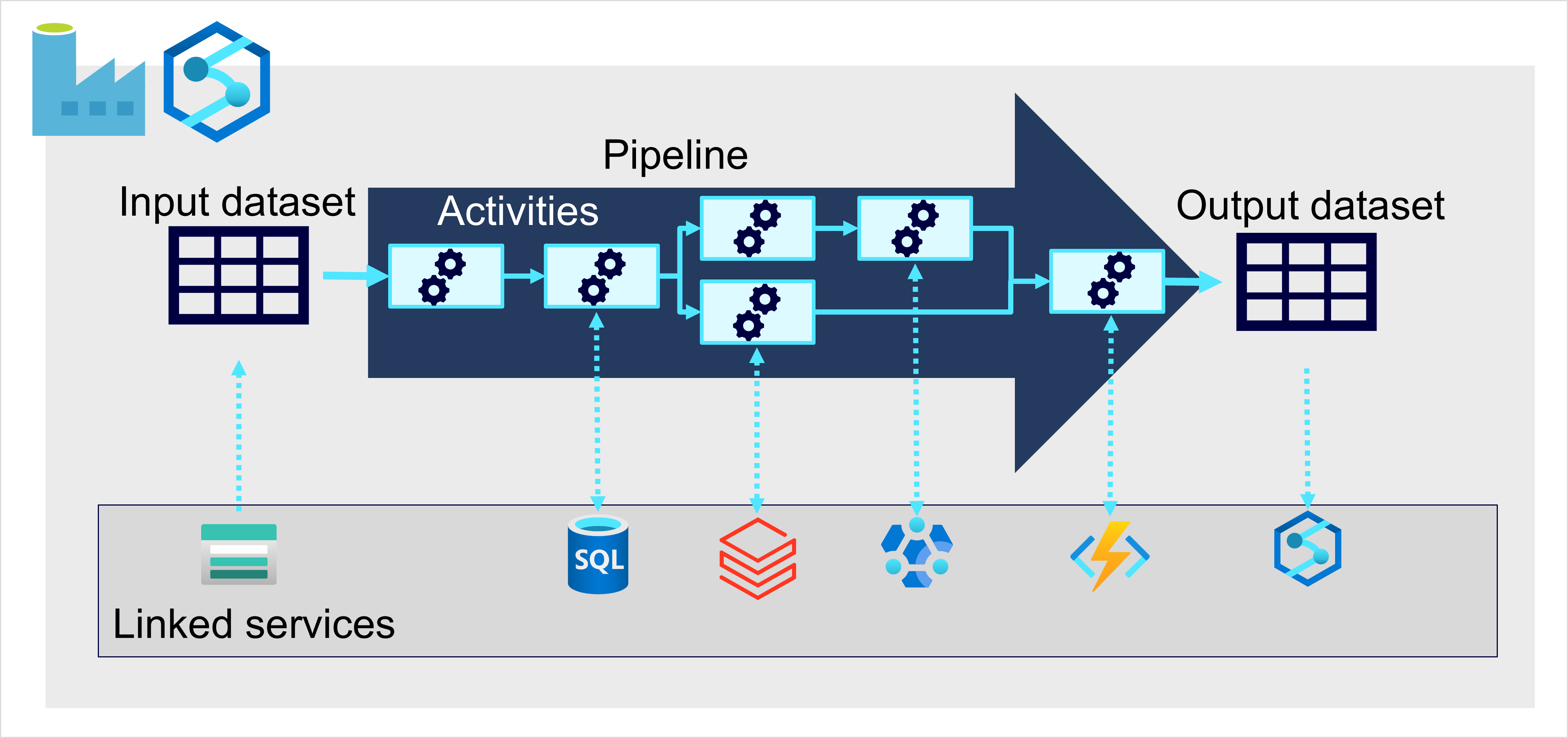
I Azure implementeras storskalig datainmatning bäst genom att skapa pipelines som samordnar ETL-processer. Du kan skapa och köra pipelines med Hjälp av Azure Data Factory, eller så kan du använda pipelinefunktionen i Microsoft Fabric om du vill hantera alla komponenter i din datalagerlösning på en enhetlig arbetsyta.
I båda fallen består pipelines av en eller flera aktiviteter som körs på data. En indatauppsättning tillhandahåller källdata och aktiviteter kan definieras som ett dataflöde som stegvis manipulerar data tills en utdatauppsättning skapas. Pipelines använder länkade tjänster för att läsa in och bearbeta data – så att du kan använda rätt teknik för varje steg i arbetsflödet. Du kan till exempel använda en länkad Azure Blob Store-tjänst för att mata in indatauppsättningen och sedan använda tjänster som Azure SQL Database för att köra en lagrad procedur som söker efter relaterade datavärden innan du kör en databearbetningsuppgift på Azure Databricks eller använder anpassad logik med hjälp av en Azure-funktion. Slutligen kan du spara utdatauppsättningen i en länkad tjänst, till exempel Microsoft Fabric. Pipelines kan också innehålla vissa inbyggda aktiviteter som inte kräver en länkad tjänst.