Utforma ett informationslagerschema
Precis som alla relationsdatabaser innehåller ett informationslager tabeller där de data som du vill analysera lagras. De här tabellerna är oftast ordnade i ett schema som är optimerat för flerdimensionell modellering, där numeriska mått som är associerade med händelser som kallas fakta kan aggregeras av attributen för associerade entiteter över flera dimensioner. Mått som är associerade med en försäljningsorder (till exempel det betalda beloppet eller antalet beställda artiklar) kan till exempel aggregeras efter attribut för det datum då försäljningen ägde rum, kunden, butiken och så vidare.
Tabeller i ett informationslager
Ett vanligt mönster för relationsdatalager är att definiera ett schema som innehåller två typer av tabeller: dimensionstabeller och faktatabeller .
Dimensionstabeller
Dimensionstabeller beskriver affärsentiteter, till exempel produkter, personer, platser och datum. Dimensionstabeller innehåller kolumner för attribut för en entitet. En kundentitet kan till exempel ha ett förnamn, ett efternamn, en e-postadress och en postadress (som kan bestå av en gatuadress, en stad, ett postnummer och ett land eller en region). Förutom attributkolumner innehåller en dimensionstabell en unik nyckelkolumn som unikt identifierar varje rad i tabellen. I själva verket är det vanligt att en dimensionstabell innehåller två nyckelkolumner:
- en surrogatnyckel som är specifik för informationslagret och unikt identifierar varje rad i dimensionstabellen i informationslagret – vanligtvis ett inkrementellt heltalsnummer.
- En alternativ nyckel, ofta en naturlig nyckel eller affärsnyckel som används för att identifiera en specifik instans av en entitet i det transaktionskällasystem som entitetsposten kommer från, till exempel en produktkod eller ett kund-ID.
Kommentar
Varför har du två nycklar? Det finns några bra skäl:
- Informationslagret kan fyllas med data från flera källsystem, vilket kan leda till risk för duplicerade eller inkompatibla affärsnycklar.
- Enkla numeriska nycklar fungerar vanligtvis bättre i frågor som kopplar många tabeller – ett vanligt mönster i informationslagret.
- Attribut för entiteter kan ändras över tid , till exempel kan en kund ändra sin adress. Eftersom informationslagret används för att stödja historisk rapportering kanske du vill behålla en post för varje instans av en entitet vid flera tidpunkter. så att till exempel försäljningsorder för en viss kund räknas för den stad där de bodde när ordern gjordes. I det här fallet skulle flera kundposter ha samma affärsnyckel som är kopplad till kunden, men olika surrogatnycklar för varje diskret adress där kunden bodde vid olika tillfällen.
Ett exempel på en dimensionstabell för kunden kan innehålla följande data:
| CustomerKey | CustomerAltKey | Name | Gatuadress | City | PostalCode | CountryRegion | |
|---|---|---|---|---|---|---|---|
| 123 | I-543 | Navin Jones | navin1@contoso.com | 1 Main St. | Seattle | 90000 | USA |
| 124 | R-589 | Mary Smith | mary2@contoso.com | 234 190th Ave | Buffalo | 50001 | USA |
| 125 | I-321 | Antoine Dubois | antoine1@contoso.com | 2 Rue Jolie | Paris | 20098 | Frankrike |
| 126 | I-543 | Navin Jones | navin1@contoso.com | 24 125th Ave. | New York | 50000 | USA |
| ... | ... | ... | ... | ... | ... | ... | ... |
Kommentar
Observera att tabellen innehåller två poster för Navin Jones. Båda posterna använder samma alternativa nyckel för att identifiera den här personen (I-543), men varje post har en annan surrogatnyckel. Utifrån detta kan du anta att kunden flyttade från Seattle till New York. Försäljning som görs till kunden medan de bor i Seattle är associerade med nyckeln 123, medan inköp som görs efter flytten till New York registreras mot rekord 126.
Förutom dimensionstabeller som representerar affärsentiteter är det vanligt att ett informationslager innehåller en dimensionstabell som representerar tid. Med den här tabellen kan dataanalytiker aggregera data över tidsintervall. Beroende på vilken typ av data du behöver analysera kan den lägsta kornigheten (kallas kornighet) för en tidsdimension representera tider (till timme, sekund, millisekunder, nanosekunder eller till och med lägre) eller datum.
Ett exempel på en tidsdimensionstabell med ett korn på datumnivå kan innehålla följande data:
| DateKey | DateAltKey | DayOfWeek | DayOfMonth | Weekday | Månad | MånadNamn | Kvartal | År |
|---|---|---|---|---|---|---|---|---|
| 19990101 | 01-01-1999 | 6 | 1 | Fredag | 1 | Januari | 1 | 1999 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20220101 | 01-01-2022 | 7 | 1 | lördag | 1 | Januari | 1 | 2022 |
| 20220102 | 02-01-2022 | 1 | 2 | söndag | 1 | Januari | 1 | 2022 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20301231 | 31-12-2030 | 3 | 31 | Tisdag | 12 | December | 4 | 2030 |
Tidsintervallet som omfattas av posterna i tabellen måste innehålla de tidigaste och senaste tidpunkterna för associerade händelser som registrerats i en relaterad faktatabell. Vanligtvis finns det en post för varje intervall vid rätt korn i mellan.
Faktatabeller
Faktatabeller lagrar information om observationer eller händelser. till exempel försäljningsorder, lagersaldon, växelkurser eller registrerade temperaturer. En faktatabell innehåller kolumner för numeriska värden som kan aggregeras efter dimensioner. Förutom de numeriska kolumnerna innehåller en faktatabell nyckelkolumner som refererar till unika nycklar i relaterade dimensionstabeller.
Till exempel kan en faktatabell som innehåller information om försäljningsorder innehålla följande data:
| OrderDateKey | CustomerKey | StoreKey | ProductKey | OrderNo | LineItemNo | Kvantitet | UnitPrice | Moms | ItemTotal |
|---|---|---|---|---|---|---|---|---|---|
| 20220101 | 123 | 5 | 701 | 1001 | 1 | 2 | 2,50 | 0.50 | 5.50 |
| 20220101 | 123 | 5 | 765 | 1001 | 2 | 1 | 2.00 | 0.20 | 2,20 |
| 20220102 | 125 | 2 | 723 | 1002 | 1 | 1 | 4.99 | 0,49 | 5.48 |
| 20220103 | 126 | 1 | 823 | 1003 | 1 | 1 | 7.99 | 0.80 | 8.79 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
En faktatabells dimensionsnyckelkolumner avgör dess kornighet. Faktatabellen försäljningsorder innehåller till exempel nycklar för datum, kunder, butiker och produkter. En beställning kan innehålla flera produkter, så kornet representerar radartiklar för enskilda produkter som säljs i butiker till kunder under specifika dagar.
Schemadesign för informationslager
I de flesta transaktionsdatabaser som används i affärsprogram normaliseras data för att minska dupliceringen. I ett informationslager avnormaliseras dock dimensionsdata vanligtvis för att minska antalet kopplingar som krävs för att köra frågor mot data.
Ofta ordnas ett informationslager som ett stjärnschema , där en faktatabell är direkt relaterad till dimensionstabellerna, som du ser i det här exemplet:
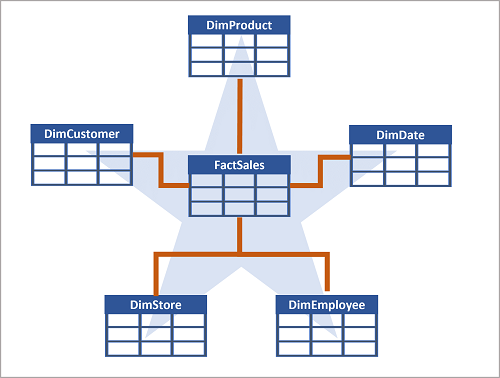
Attributen för en entitet kan användas för att aggregera mått i faktatabeller över flera hierarkiska nivåer, till exempel för att hitta totala försäljningsintäkter per land eller region, stad, postnummer eller enskild kund. Attributen för varje nivå kan lagras i samma dimensionstabell. Men när en entitet har ett stort antal hierarkiska attributnivåer, eller när vissa attribut kan delas av flera dimensioner (till exempel både kunder och butiker har en geografisk adress), kan det vara klokt att tillämpa viss normalisering på dimensionstabellerna och skapa ett snowflake-schema , som du ser i följande exempel:
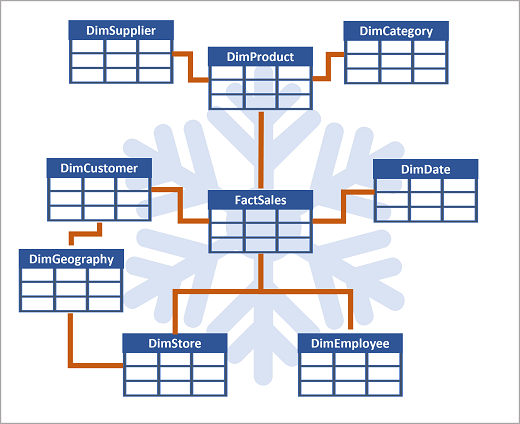
I det här fallet har dimproduct-tabellen normaliserats för att skapa separata dimensionstabeller för produktkategorier och leverantörer, och en DimGeography-tabell har lagts till för att representera geografiska attribut för både kunder och butiker. Varje rad i tabellen DimProduct innehåller nyckelvärden för motsvarande rader i tabellerna DimCategory och DimSupplier . Varje rad i tabellerna DimCustomer och DimStore innehåller ett nyckelvärde för motsvarande rad i tabellen DimGeography .