Samla in, fråga och visualisera hälsotillstånd
För att korrekt representera en hälsomodell måste du samla in olika datamängder från systemet. Datauppsättningarna innehåller loggar och prestandamått från programkomponenter och underliggande Azure-resurser. Det är viktigt att korrelera data mellan datauppsättningarna för att skapa en skiktad representation av hälsotillståndet för systemet.
Instrumenteringskod och infrastruktur
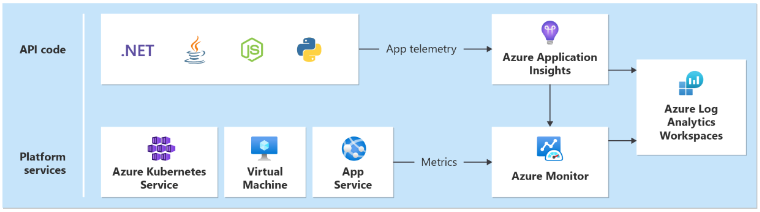
En enhetlig datamottagare krävs för att säkerställa att alla driftdata lagras och är tillgängliga på en enda plats där all telemetri samlas in. När en anställd till exempel skapar en kommentar i sin webbläsare kan du spåra den här åtgärden och se att begäran gick via katalog-API:et till Azure Event Hubs. Därifrån hämtade bakgrundsprocessorn kommentaren och lagrar den i Azure Cosmos DB.
Azure Monitor Log Analytics fungerar som den centrala Azure-interna enhetliga datamottagaren för att lagra och analysera driftdata:
Application Insights är det rekommenderade APM-verktyget (Application Performance Monitoring) för alla programkomponenter för att samla in programloggar, mått och spårningar. Application Insights distribueras i en arbetsytebaserad konfiguration i varje region.
I exempelprogrammet används Azure Functions på Microsoft .NET 6 för sina serverdelstjänster för intern integrering. Eftersom serverdelsprogram redan finns skapar Contoso Shoes bara en ny Application Insights-resurs i Azure och konfigurerar inställningen för
APPLICATIONINSIGHTS_CONNECTION_STRINGbåda funktionsapparna. Azure Functions-körningen registrerar Application Insights-loggningsprovidern automatiskt, så telemetri visas i Azure utan extra ansträngning. Om du vill ha mer anpassad loggning kan du användaILoggergränssnittet.Centraliserad datauppsättning är ett antimönster för verksamhetskritiska arbetsbelastningar. Varje region måste ha sin dedikerade Log Analytics-arbetsyta och en Application Insights-instans. För globala resurser rekommenderas separata instanser. Information om kärnarkitekturmönstret finns i Arkitekturmönster för verksamhetskritiska arbetsbelastningar i Azure.
Varje lager bör skicka data till samma Log Analytics-arbetsyta för att göra analys- och hälsoberäkningar enklare.
Hälsoövervakningsfrågor
Log Analytics, Application Insights och Azure Data Explorer använder alla Kusto-frågespråk (KQL) för sina frågor. Du kan använda KQL för att skapa frågor och använda funktioner för att hämta mått och beräkna hälsopoäng.
Information om enskilda tjänster som beräknar hälsostatus finns i följande exempelfrågor.
Katalog-API
Följande exempel visar en katalog-API-fråga:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds=datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 10, 50, // Failed requests, anything non-200, allow a few more than 0 for user-caused errors like 404s
"avgProcessingTime", 150, 500 // Average duration of the request, in ms
];
// Calculate average processing time for each request
let avgProcessingTime = AppRequests
| where AppRoleName startswith "CatalogService"
| where OperationName != "GET /health/liveness" // Liveness requests don't do any processing, including them would skew the results
| make-series Value = avg(DurationMs) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'avgProcessingTime';
// Calculate failed requests
let failureCount = AppRequests
| where AppRoleName startswith "CatalogService" // Liveness requests don't do any processing, including them would skew the results
| where OperationName != "GET /health/liveness"
| make-series Value=countif(Success != true) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'failureCount';
// Union all together and join with the thresholds
avgProcessingTime
| union failureCount
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
| project-reorder TimeGenerated, MetricName, Value, IsYellow, IsRed, YellowThreshold, RedThreshold
| extend ComponentName="CatalogService"
Azure Key Vault
Följande exempel visar en Azure Key Vault-fråga:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds = datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 3, 10 // Failure count on key vault requests
];
let failureStats = AzureDiagnostics
| where TimeGenerated > _timespanStart
| where ResourceProvider == "MICROSOFT.KEYVAULT"
// Ignore authentication operations that have a 401. This is normal when using Key Vault SDK. First an unauthenticated request is made, then the response is used for authentication
| where Category=="AuditEvent" and not (OperationName == "Authentication" and httpStatusCode_d == 401)
| where OperationName in ('SecretGet','SecretList','VaultGet') or '*' in ('SecretGet','SecretList','VaultGet')
// Exclude Not Found responses because these happen regularly during 'Terraform plan' operations, when Terraform checks for the existence of secrets
| where ResultSignature != "Not Found"
// Create ResultStatus with all the 'success' results bucketed as 'Success'
// Certain operations like StorageAccountAutoSyncKey have no ResultSignature; for now, also set to 'Success'
| extend ResultStatus = case ( ResultSignature == "", "Success",
ResultSignature == "OK", "Success",
ResultSignature == "Accepted", "Success",
ResultSignature);
failureStats
| make-series Value=countif(ResultStatus != "Success") default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName="failureCount", ComponentName="Keyvault"
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
Katalogpoäng för Tjänststatus
Slutligen kan du koppla ihop olika hälsostatusfrågorför att beräkna en komponents hälsopoäng. Följande exempelfråga visar hur du beräknar en katalog Tjänststatus poäng:
CatalogServiceHealthStatus()
| union AksClusterHealthStatus()
| union KeyvaultHealthStatus()
| union EventHubHealthStatus()
| where TimeGenerated < ago(2m)
| summarize YellowScore = max(IsYellow), RedScore = max(IsRed) by bin(TimeGenerated, 2m)
| extend HealthScore = 1 - (YellowScore * 0.25) - (RedScore * 0.5)
| extend ComponentName = "CatalogService", Dependencies="AKSCluster,Keyvault,EventHub" // These values are added to build the dependency visualization
| order by TimeGenerated desc
Dricks
Se fler frågeexempel på GitHub-lagringsplatsen Azure Mission-Critical Online .
Konfigurera frågebaserade aviseringar
Aviseringar uppmärksammar omedelbart problem som återspeglar eller påverkar hälsotillståndet. När det sker en ändring i hälsotillståndet, antingen till ett degraderat (gult) tillstånd eller till ett tillstånd med feltillstånd (röd), bör meddelanden skickas till ansvarigt team. Ställ in aviseringar på rotnoden i hälsomodellen för att omedelbart bli medveten om eventuella ändringar på affärsnivå i lösningens hälsotillstånd. Sedan kan du titta på hälsomodellvisualiseringar för att få mer information och felsöka.
I exemplet används Azure Monitor-aviseringar för att köra automatiserade åtgärder som svar på ändringar i programmets hälsotillstånd.
Använda instrumentpaneler för visualisering
Det är viktigt att visualisera din hälsomodell så att du snabbt kan förstå effekten av ett komponentavbrott på hela systemet. Det slutliga målet med en hälsomodell är att underlätta snabb diagnos genom att ge en välinformerad vy över avvikelser från stabilt tillstånd.
Ett vanligt sätt att visualisera systemhälsoinformation är att kombinera en skiktad hälsomodellvy med funktioner för telemetri för ökad detaljnivå på en instrumentpanel.
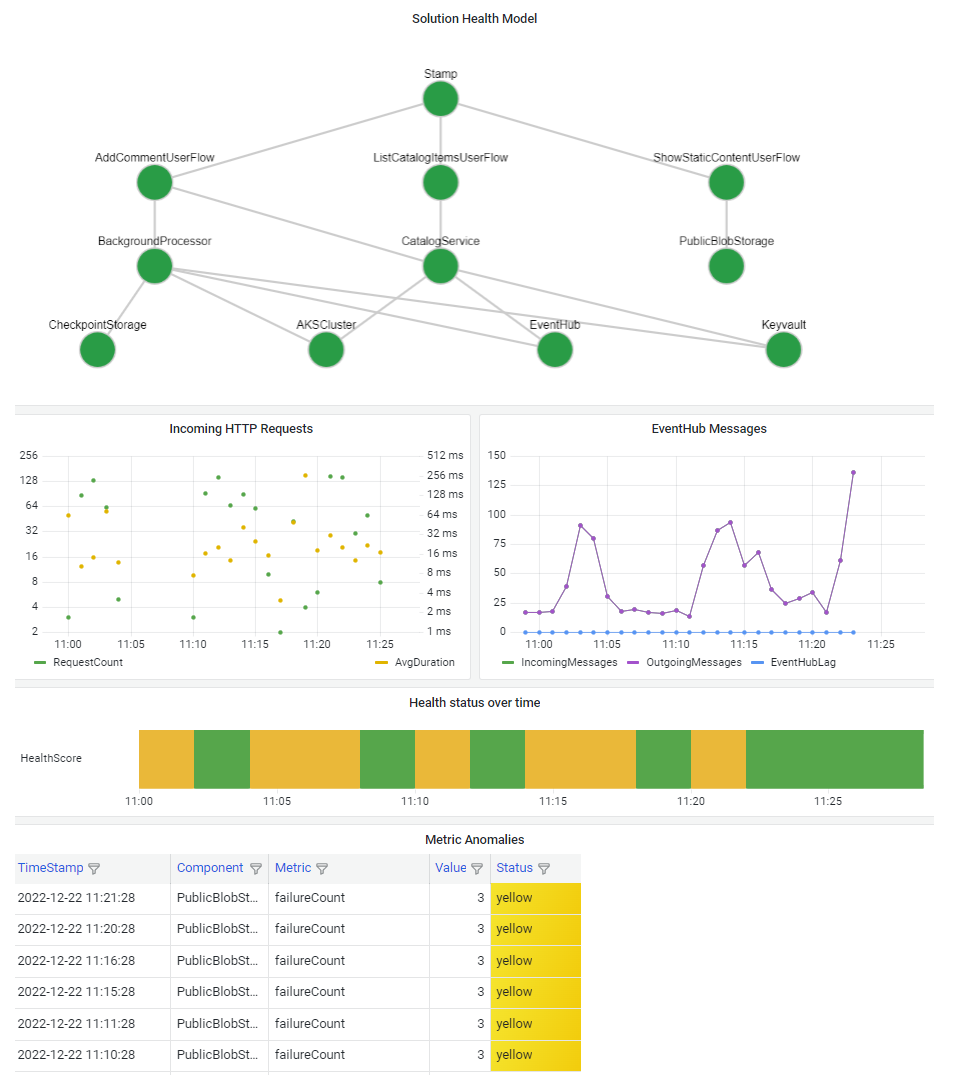
Instrumentpanelstekniken bör kunna representera hälsomodellen. Populära alternativ är Azure-instrumentpaneler, Power BI och Azure Managed Grafana.