Beskriva kritiska prestandamått
Du har sett hur du samlar in data i både Azure Monitor och Windows Performance Monitor. Nu får du lära dig hur du skapar mått i Azure Monitor, vilket gör att du kan utlösa aviseringar eller köra automatiserade felsvar.
Granskning av Azure-mått
Azure Monitor-tjänsten innehåller möjligheten att spåra olika mått om den övergripande hälsan för en viss resurs. Mått samlas in med jämna mellanrum och är gatewayen för aviseringsprocesser som hjälper dig att lösa problem snabbt och effektivt. Azure Monitor Metrics är ett kraftfullt undersystem som gör att du inte bara kan analysera och visualisera dina prestandadata, utan även utlösa aviseringar som meddelar administratörer eller automatiserade åtgärder som kan utlösa en Azure Automation-runbook eller en webhook. Du har också möjlighet att arkivera dina Azure Metrics-data till Azure Storage, eftersom aktiva data endast lagras i 93 dagar.
Skapa måttaviseringar
Med hjälp av Azure Portal kan du skapa aviseringsregler baserat på definierade mått i översiktsavsnittet på Azure Monitor-bladet. Azure Monitor-aviseringar kan begränsas på tre sätt. Om du till exempel använder Azure Virtual Machines som exempel kan du ange omfånget som:
En lista över virtuella datorer i en Azure-region inom en prenumeration
Alla virtuella datorer (i en Azure-region) i en eller flera resursgrupper i en prenumeration
Alla virtuella datorer (i en Azure-region) i en prenumeration
På så sätt kan du skapa en aviseringsregel baserat på resurser i resursgrupper som visas.
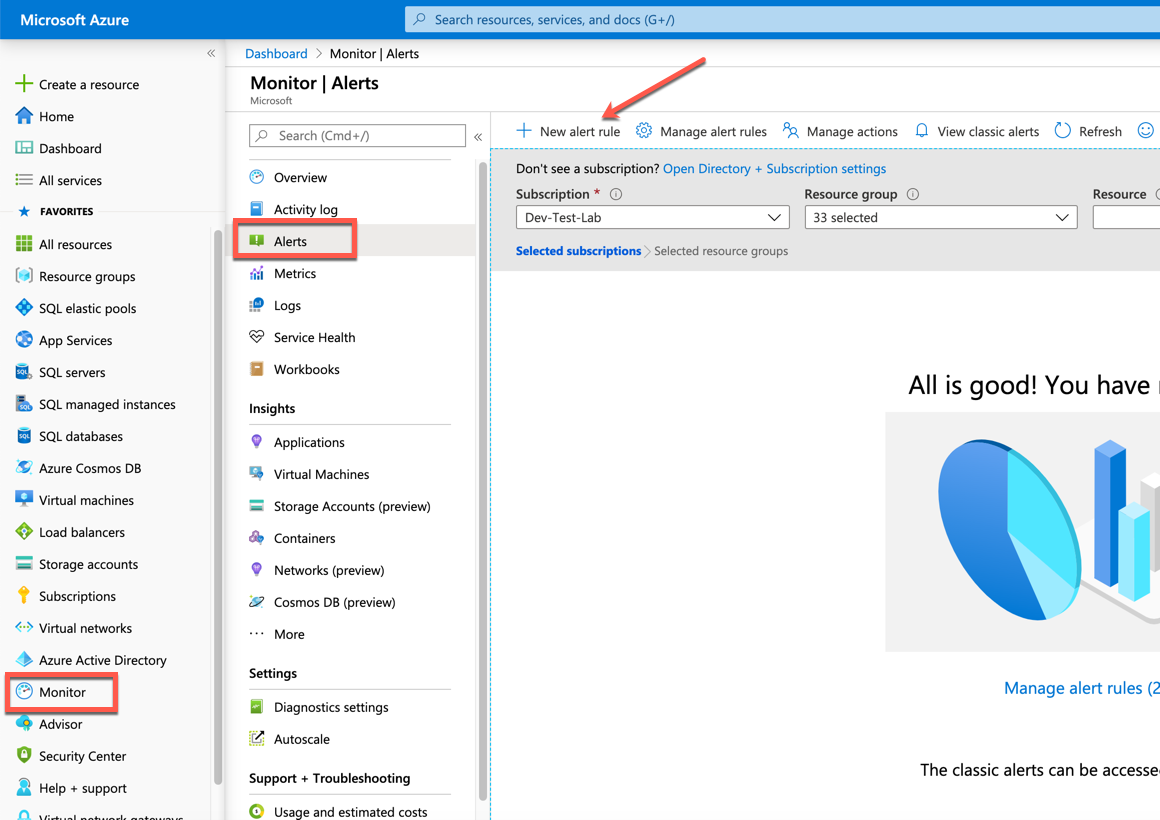
Exemplet nedan visar en virtuell dator med namnet SQL2019 där vi skapar en avisering som ligger i omfånget för den enskilda virtuella datorn.
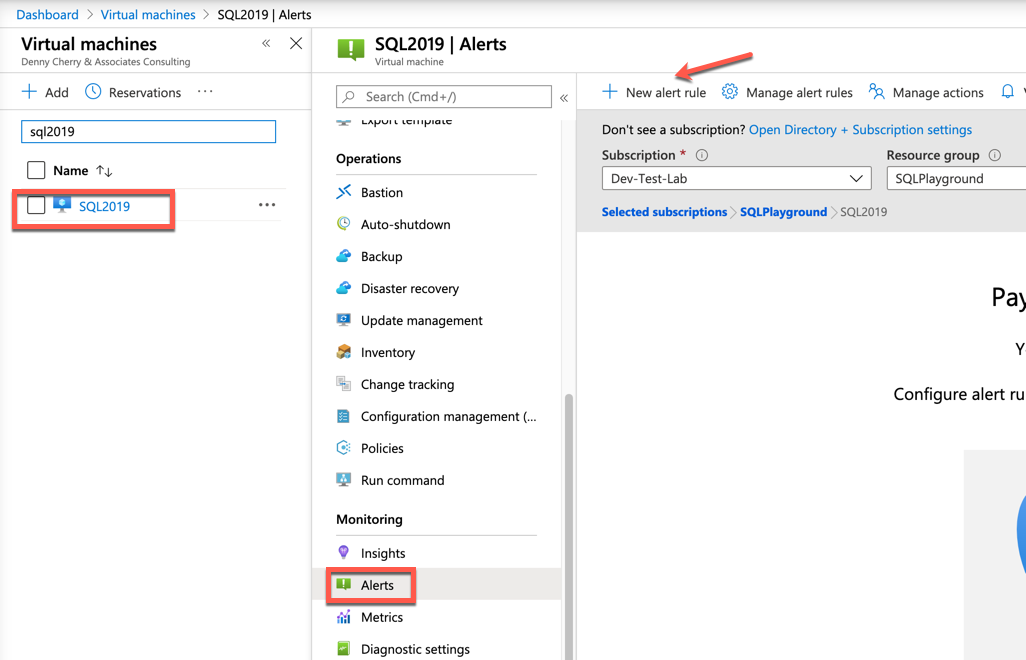
Oavsett omfånget för aviseringen är skapandeprocessen densamma.
Från aviseringsskärmen klickar du på Ny aviseringsregel. Om en avisering skapas inom omfånget för en resurs bör resursvärdena fyllas i åt dig. Du kan se att resursen är den SQL2019 virtuella datorn, prenumerationen är Dev-Test-Lab och resursgruppen där den finns är SQLPlayground.
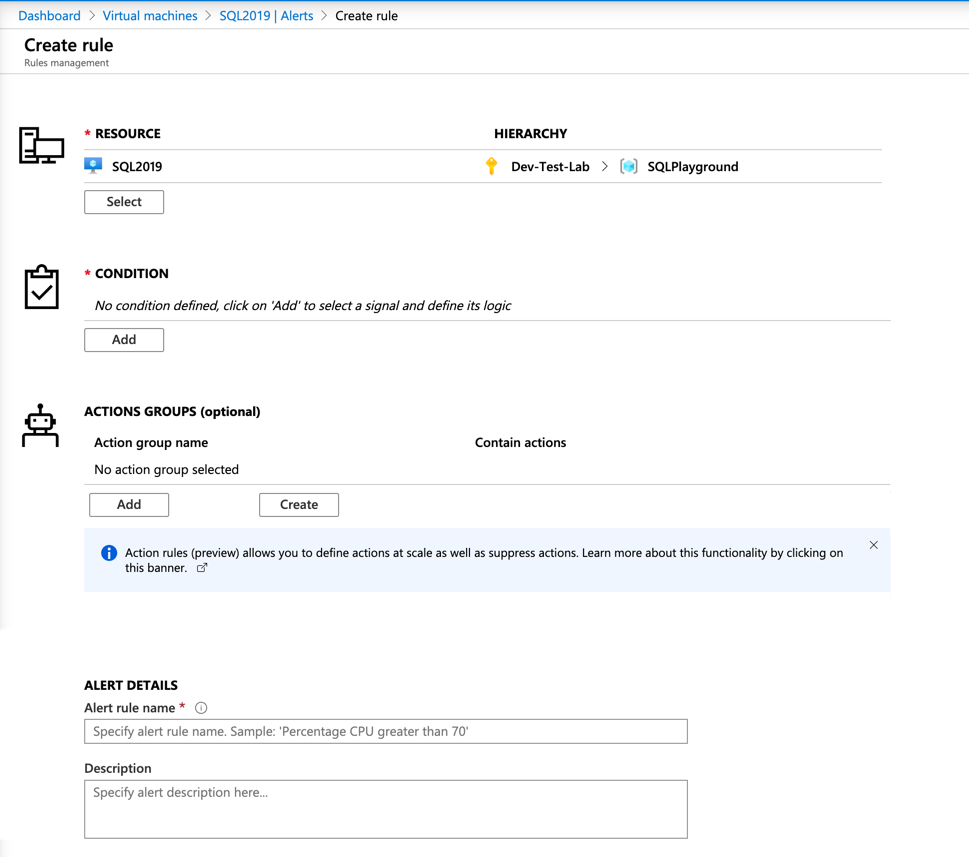
Under avsnittet Villkor klickar du på Lägg till:
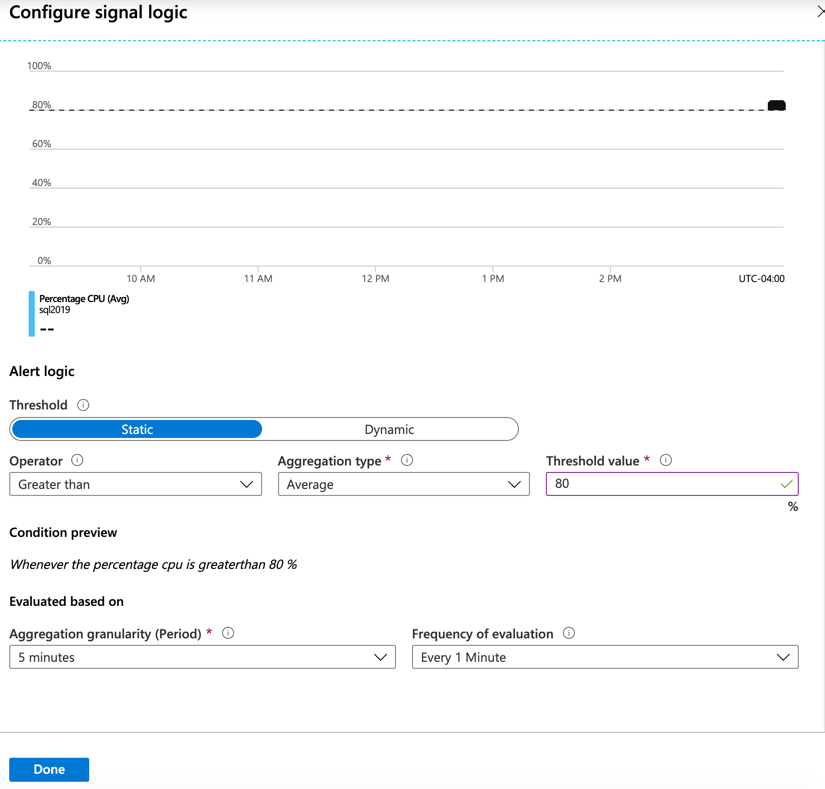
Välj det mått som du vill avisera om. Följande bild visar Procent cpu, som du sedan ser valt.
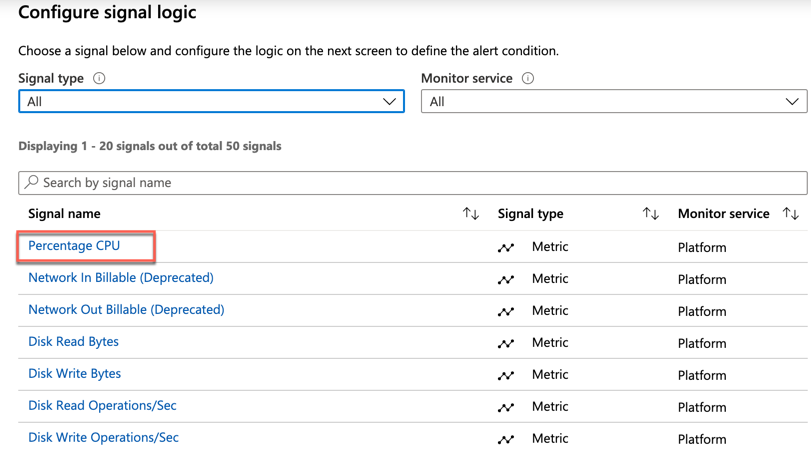
Aviseringarna kan konfigureras statiskt (till exempel generera en avisering när PROCESSORn överskrider 95 %) eller på ett dynamiskt sätt med dynamiska tröskelvärden. Dynamiska tröskelvärden lär sig måttets historiska beteende och skapar en avisering när resurserna fungerar på ett onormalt sätt. Dessa dynamiska tröskelvärden kan identifiera säsongsvariationer i dina arbetsbelastningar och justera aviseringarna i enlighet med detta.
Om statiska aviseringar används måste du ange ett tröskelvärde för det valda måttet. I det här exemplet angavs 80 procent. Det här tröskelvärdet innebär att om CPU-användningen överskrider 80 procent under en viss period utlöses en avisering och reagerar enligt angiven.
Båda typerna av aviseringar erbjuder booleska operatorer, till exempel operatorerna "större än" eller "mindre än". Tillsammans med booleska operatorer finns det aggregerade mått att välja bland, till exempel medelvärde, minimum, maximum, antal, medelvärde och total. Med de här alternativen är det enkelt att skapa en flexibel avisering som passar nästan alla aviseringar på företagsnivå.
När du har skapat aviseringen måste en åtgärdsgrupp konfigureras för att meddela administratörer eller starta en automatiseringsprocess.
Kommentar
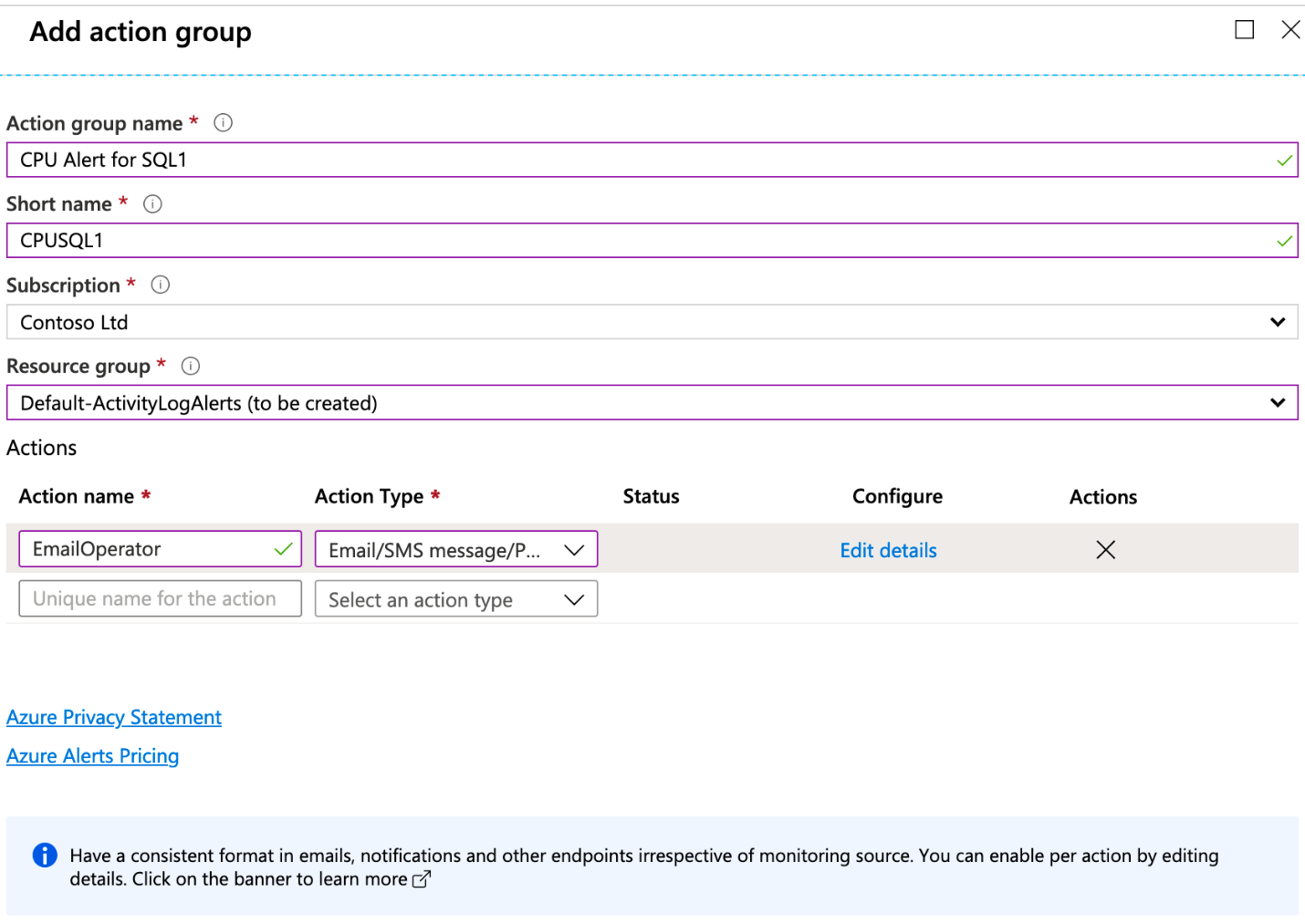
Det är valfritt att definiera en åtgärdsgrupp, och om en inte har konfigurerats loggar aviseringen bara meddelandet till lagring utan att någon ytterligare åtgärd vidtas. Du kan skapa en ny åtgärdsgrupp från måttskärmen genom att klicka på Lägg till bredvid Åtgärdsgrupper. Sedan visas den här dialogrutan:

När du klickar på Gruppen Skapa åtgärd visas skärmen nedan. Du namnger åtgärdsgruppen och definierar en avisering och svaret. I det här exemplet kommer administratören att skickas via e-post om aviseringens villkor utlöses.
Du kan konfigurera e-post- eller SMS-information som du ser nedan. Du kan nå den här skärmen antingen genom att klicka på Redigera information under Konfigurera eller genom att lägga till en ny åtgärd som även visar konfigurationsskärmen.
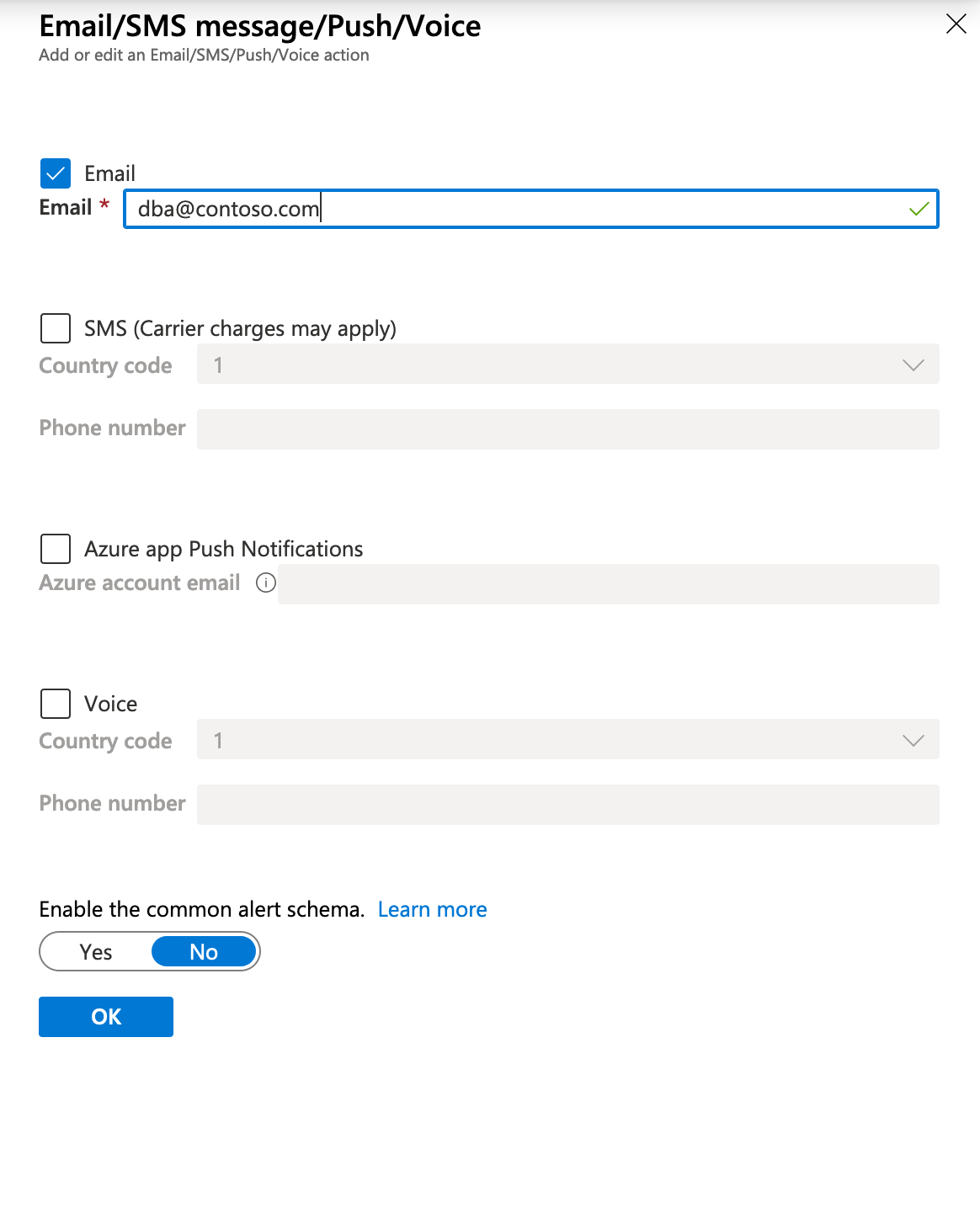
Med en åtgärdsgrupp finns det flera sätt på vilka du kan svara på aviseringen. Följande alternativ är tillgängliga för att definiera vilken åtgärd som ska vidtas:
- Automation Runbook
- Azure-funktion
- E-post till Azure Resource Manager-rollen
- E-post/SMS/push/röst
- ITSM
- Azure logic-app
- Säker webhook
- Webhook
Det finns två kategorier av dessa åtgärder – meddelande, vilket innebär att meddela en administratör eller grupp administratörer om en händelse och automatisering, som vidtar en definierad åtgärd för att svara på ett prestandavillkor.
Granska äldre prestandadata
En av fördelarna med att använda Azure Monitor är möjligheten att enkelt och snabbt granska tidigare mått som samlats in. Om du undersöker en resurs noterar du en datetime-väljare i det övre högra hörnet. Azure Monitor-mått behålls i 93 dagar, varefter de rensas, men du har möjlighet att arkivera dem i Azure Storage.
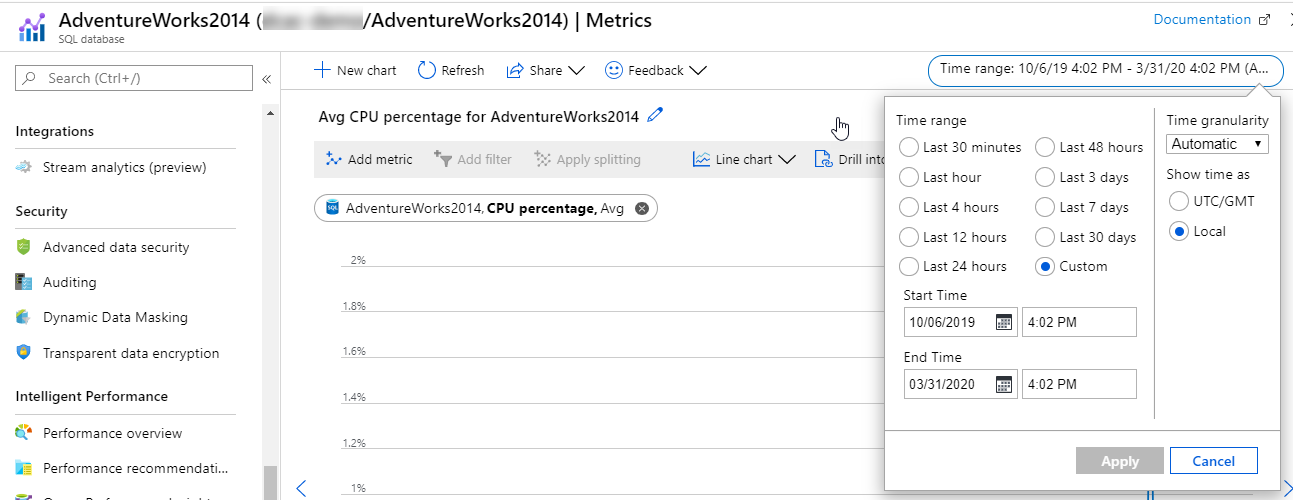
Du kan också välja ett mindre tidsfönster, till exempel de senaste 30 minuterna, den senaste timmen, de senaste 4 timmarna eller de senaste 12 timmarna. Flexibiliteten i Azure Monitor gör det möjligt för administratörer att snabbt identifiera problem och eventuellt diagnostisera tidigare problem.
SQL Server-mått som är viktiga
Microsoft SQL Server är en väl instrumenterad programvara som samlar in en hel del prestandametadata. Databasmotorn har mått som kan övervakas för att identifiera och förbättra prestandarelaterade problem. Vissa operativsystemmått kan bara visas inifrån prestandaövervakaren medan andra kan nås via T-SQL-frågor, särskilt genom att välja bland dynamiska hanteringsvyer (DMV). Det finns vissa mått som exponeras på båda platserna, så det är viktigt att veta var specifika mått ska identifieras. Ett exempel på data som bara kan samlas in från DMV:er är data och transaktionsloggfilens läs-/skrivfördröjning som exponeras i sys.dm_os_volume_stats. Å andra sidan är ett exempel på ett OS-mått som inte är tillgängligt direkt via SQL Server sekunderna per diskläsning och skrivning för diskvolymen. Genom att kombinera dessa två mått kan du få bättre förståelse för om ett prestandaproblem är relaterat till databasstrukturen eller en flaskhals för fysisk lagring.