Beskriva medaljongarkitektur
Data lakehouses i Fabric bygger på Delta Lake-formatet, som internt stöder ACID-transaktioner (Atomicity, Consistency, Isolation, Durability). Inom det här ramverket är medaljongarkitekturen ett rekommenderat mönster för datadesign som används för att organisera data i ett lakehouse logiskt. Det syftar till att förbättra datakvaliteten när den rör sig genom olika lager. Arkitekturen har vanligtvis tre lager – brons (rå), silver (validerad) och guld (berikad), som var och en representerar högre datakvalitetsnivåer. Vissa kallar det också en "multi-hop"-arkitektur, vilket innebär att data kan flyttas mellan lager efter behov.
Den här arkitekturen säkerställer att data är tillförlitliga och konsekventa när de genomgår olika kontroller och ändringar. Det garanterar också att data lagras säkert på ett sätt som gör det enklare och snabbare att analysera.
Medaljongarkitekturen kompletterar andra dataorganisationsmetoder i stället för att ersätta dem. Du kan se medaljongarkitekturen som ramverket för datarensning i stället för en dataarkitektur eller modell. Det säkerställer kompatibilitet och flexibilitet för företag att anta sina fördelar tillsammans med befintliga datamodeller, så att du kan anpassa datalösningar och bevara expertis samtidigt som de förblir anpassningsbara i det ständigt föränderliga datalandskapet.
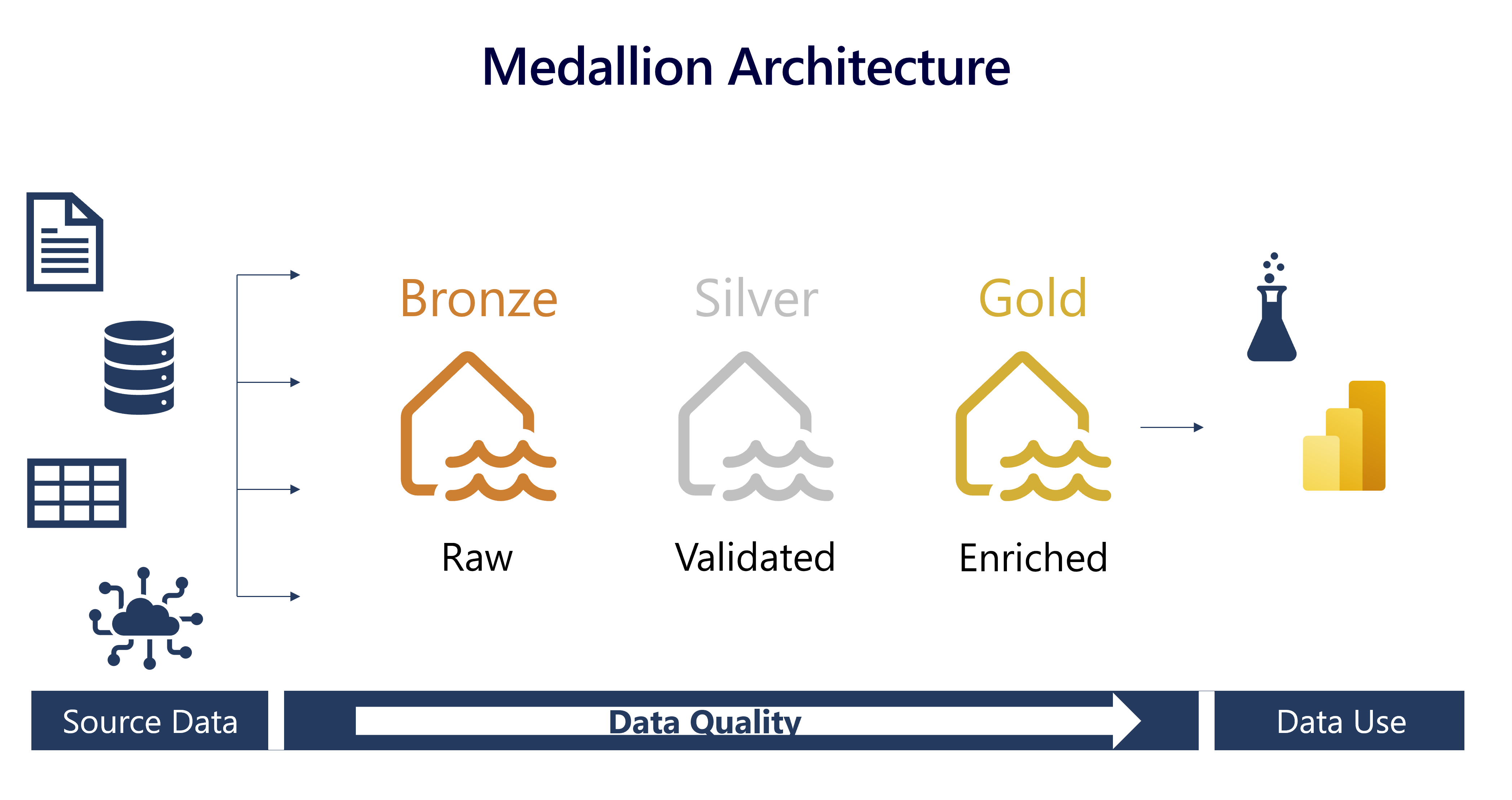
Förstå arkitekturformatet medallion
Bronsskikt
Brons- eller råskiktet i medaljongarkitekturen är det första lagret i sjöhuset. Det är landningszonen för alla data, oavsett om de är strukturerade, halvstrukturerade eller ostrukturerade. Data lagras i sitt ursprungliga format och inga ändringar görs i dem.
Silverskikt
Det silver- eller validerade lagret är det andra lagret i sjöhuset. Det är där du verifierar och förfinar dina data. Vanliga aktiviteter i silverskiktet är att kombinera och slå samman data och framtvinga dataverifieringsregler som att ta bort null-värden och deduplicera. Silverlagret kan betraktas som en central lagringsplats i en organisation eller ett team, där data lagras i ett konsekvent format och kan nås av flera team. I silverskiktet rensar du dina data tillräckligt så att allt är på ett ställe och redo att förfinas och modelleras i guldskiktet.
Guldskikt
Det guld- eller berikade lagret är det tredje lagret i sjöhuset. I guldskiktet genomgår data ytterligare förfining för att anpassas till specifika affärs- och analysbehov. Det kan handla om att aggregera data till en viss kornighet, till exempel dagligen eller varje timme, eller att utöka dem med extern information. När data når guldsteget blir de redo för användning av underordnade team, inklusive analys, datavetenskap eller MLOps.
Anpassa din medaljongarkitektur
Beroende på organisationens specifika användningsfall kan du behöva fler lager. Du kan till exempel ha ytterligare ett "raw"-lager för landningsdata i ett visst format innan de omvandlas till bronsskiktet. Eller så kan du ha ett "platina"-lager för data som har förfinats ytterligare och berikats för ett specifikt användningsfall. Oavsett namn och antal lager är medaljongarkitekturen flexibel och kan skräddarsys för att uppfylla organisationens särskilda krav.
Flytta data mellan lager i infrastrukturresurser
Flytta data över medaljongskikt förfinar, organiserar och förbereder dem för underordnade dataaktiviteter. I Fabrics lakehouse finns det mer än ett sätt att flytta data mellan lager, vilket säkerställer att du kan välja den metod som fungerar för ditt team.
Det finns några saker att tänka på när du bestämmer hur du ska flytta och transformera data mellan lager.
- Hur mycket data arbetar du med?
- Hur komplexa är de omvandlingar du behöver göra?
- Hur ofta behöver du flytta data mellan lager?
- Vilka verktyg är du mest bekväm med?
Genom att förstå skillnaden mellan datatransformering och dataorkestrering kan du välja rätt verktyg för jobbet i Fabric.
Datatransformering innebär att ändra strukturen eller innehållet i data för att uppfylla specifika krav. Verktyg för datatransformering i Infrastrukturresurser omfattar Dataflöden (Gen2) och notebook-filer. Dataflöden är ett bra alternativ för mindre semantiska modeller och enkla transformeringar. Notebook-filer är ett bättre alternativ för större semantiska modeller och mer komplexa omvandlingar. Med notebook-filer kan du också spara dina transformerade data som en hanterad Delta-tabell i lakehouse, redo för rapportering.
Dataorkestrering syftar på samordning och hantering av flera datarelaterade processer, vilket säkerställer att de fungerar tillsammans för att uppnå önskat resultat. Det primära verktyget för dataorkestrering i Infrastrukturresurser är pipelines. En pipeline är en serie steg som flyttar data från en plats till en annan, i det här fallet från ett lager av medaljongarkitekturen till nästa. Pipelines kan automatiseras för att köras enligt ett schema eller utlösas av en händelse.