Förstå SQL Database-hyperskala
Azure SQL Database har begränsats till 4 TB lagringsutrymme per databas i många år. Den här begränsningen beror på en fysisk begränsning av Azure-infrastrukturen. Azure SQL Database Hyperscale ändrar paradigmet och gör det möjligt för databaser att vara 100 TB eller mer. Hyperskala introducerar nya horisontella skalningstekniker för att lägga till beräkningsnoder när datastorlekarna växer. Kostnaden för Hyperskala är samma som kostnaden för Azure SQL Database. Det finns dock en kostnad per terabyte för lagring. Observera att när en Azure SQL Database har konverterats till Hyperskala kan du inte konvertera tillbaka den till en "vanlig" Azure SQL Database. Hyperskala är möjligheten för en arkitektur att skalas på rätt sätt efter behov.
Azure SQL Database Hyperscale är ett bra alternativ för de flesta företagsarbetsbelastningar eftersom det ger stor flexibilitet och höga prestanda med oberoende skalbara beräknings- och lagringsresurser.
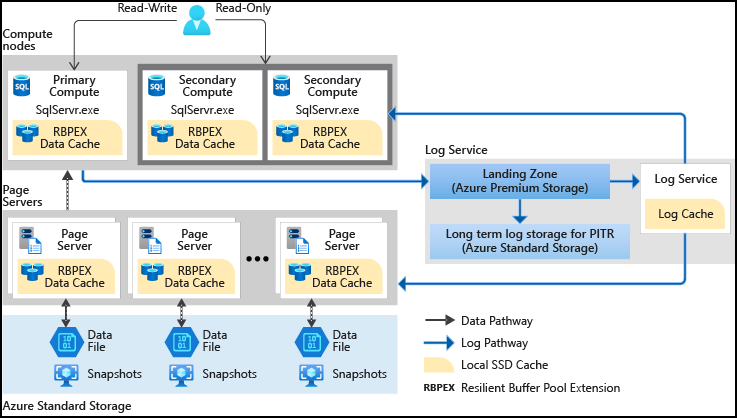
Hyperskala separerar frågebearbetningsmotorn, där semantiken för olika datamotorer skiljer sig från de komponenter som ger långsiktig lagring och hållbarhet för data. På så sätt kan lagringskapaciteten skalas ut smidigt så långt det behövs.
Tjänstnivån Hyperskala i Azure SQL Database är den senaste tjänstnivån i den vCore-baserade inköpsmodellen. Den här tjänstnivån är en mycket skalbar lagrings- och beräkningsprestandanivå som använder Azure för att skala ut lagrings- och beräkningsresurserna för en Azure SQL Database avsevärt utöver de gränser som är tillgängliga för tjänstnivåerna Generell användning och Affärskritisk.
Förmåner
Tjänstnivån Hyperskala tar bort många av de praktiska gränser som traditionellt sett setts i molndatabaser. Om de flesta andra databaser begränsas av de resurser som är tillgängliga i en enda nod har databaser på tjänstnivån Hyperskala inga sådana gränser. Med sin flexibla lagringsarkitektur växer lagringen efter behov. Faktum är att Hyperskala-databaser inte skapas med en definierad maxstorlek. En Hyperskala-databas växer efter behov – och du debiteras endast för den kapacitet du använder. För läsintensiva arbetsbelastningar ger tjänstnivån Hyperskala snabb utskalning genom att etablera extra repliker efter behov för avlastning av läsarbetsbelastningar.
Dessutom är den tid som krävs för att skapa databassäkerhetskopior eller för att skala upp eller ned inte längre knuten till datavolymen i databasen. Hyperskala-databaser kan säkerhetskopieras omedelbart. Du kan också skala en databas i tiotals terabyte upp eller ned på några minuter. Den här funktionen befriar dig från problem med att bli inrutad av dina första konfigurationsalternativ. Hyperskala ger också snabba databasåterställningar som körs på några minuter i stället för timmar eller dagar.
Hyperskala ger snabb skalbarhet baserat på din arbetsbelastningsefterfrågan.
Skala upp/ned – Du kan skala upp den primära beräkningsstorleken när det gäller resurser som CPU och minne och sedan skala ned i konstant tid. Eftersom lagringen delas länkas inte skalning upp och ned till mängden data i databasen.
Skala in/ut – Du får också möjlighet att etablera en eller flera beräkningsrepliker som du kan använda för att hantera dina läsbegäranden. Det innebär att du kan använda extra beräkningsrepliker som skrivskyddade repliker för att avlasta läsarbetsbelastningen från den primära beräkningen. Förutom skrivskyddad fungerar dessa repliker också som frekventa väntelägen till redundansväxling från den primära.
Etablering av var och en av dessa extra beräkningsrepliker kan göras i konstant tid och är en onlineåtgärd. Du kan ansluta till skrivskyddade beräkningsrepliker genom att ange argumentet ApplicationIntent på din anslutningssträng till ReadOnly. Alla anslutningar med avsikten ReadOnly-programmet dirigeras automatiskt till en av de skrivskyddade beräkningsreplikerna.
Hyperskala separerar frågebearbetningsmotorn från de komponenter som ger långsiktig lagring och hållbarhet för data. Den här arkitekturen ger möjlighet att smidigt skala lagringskapaciteten så långt det behövs (det ursprungliga målet är 100 TB) och möjligheten att skala beräkningsresurser snabbt.
Säkerhetsfrågor
Säkerhet för tjänstnivån Hyperskala har samma fantastiska funktioner som de andra Azure SQL Database-nivåerna. De skyddas av den skiktade metoden för skydd på djupet enligt bilden nedan och flyttas från utsidan i:
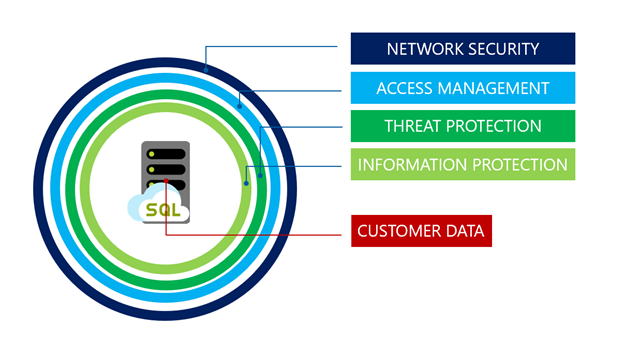
Nätverkssäkerhet är det första försvarsskiktet och använder IP-brandväggsregler för att tillåta åtkomst baserat på den ursprungliga IP-adressen och brandväggsreglerna för virtuellt nätverk för att tillåta möjligheten att acceptera kommunikation som skickas från valda undernät i ett virtuellt nätverk.
Åtkomsthantering tillhandahålls via nedanstående autentiseringsmetoder för att säkerställa att en användare är den som de påstår sig vara:
- SQL-autentisering
- Microsoft Entra-autentisering
- Windows-autentisering för Microsoft Entra-huvudnamn (förhandsversion)
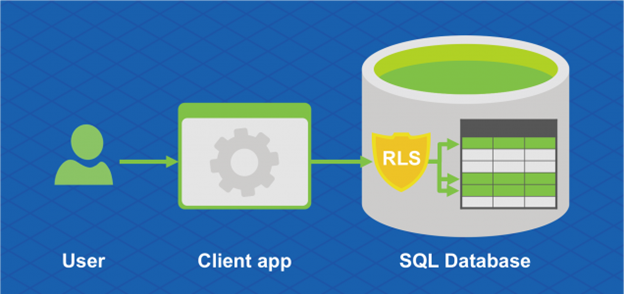
Azure SQL Database Hyperscale stöder även säkerhet på radnivå. Säkerhet på radnivå gör det möjligt för kunder att styra åtkomsten till rader i en databastabell baserat på egenskaperna hos användaren som kör en fråga (till exempel gruppmedlemskap eller körningskontext).
Hotskyddsfunktioner i gransknings- och hotidentifieringsfunktioner. SQL Database- och SQL Managed Instance-granskning spårar databasaktiviteter och hjälper till att upprätthålla efterlevnad av säkerhetsstandarder genom att registrera databashändelser i en granskningslogg i ett kundägt Azure-lagringskonto. Advanced Threat Protection kan aktiveras per server mot en extra avgift och analyserar loggarna för att identifiera ovanligt beteende och potentiellt skadliga försök att komma åt eller utnyttja databaser. Aviseringar skapas för misstänkta aktiviteter som SQL-inmatning, potentiell datainfiltration och råstyrkeattacker eller avvikelser i åtkomstmönster för att fånga privilegiereskaleringar och användning av autentiseringsuppgifter som har brutits.
Information Protection tillhandahålls på följande olika sätt:
- TLS (kryptering under överföring)
- transparent datakryptering (kryptering i vila)
- Nyckelhantering med Azure Key Vault
- Always Encrypted (kryptering används)
- Dynamisk datamaskning
Prestandaöverväganden
Tjänstnivån Hyperskala är avsedd för kunder som har stora lokala SQL Server-databaser och som vill modernisera sina program genom att flytta till molnet eller för kunder som redan använder Azure SQL Database och som vill utöka databastillväxten avsevärt. Hyperskala är också avsett för kunder som söker både hög prestanda och hög skalbarhet.
Hyperskala ger följande prestandafunktioner:
- Nästan omedelbar säkerhetskopiering av databaser (baserat på ögonblicksbilder av filer som lagras i Azure Blob Storage) oavsett storlek utan I/O-effekt på beräkningsresurser.
- Snabb databasåterställning (baserat på ögonblicksbilder av filer) i minuter i stället för timmar eller dagar (inte en storlek på dataåtgärden).
- Högre övergripande prestanda på grund av högre dataflöde för transaktionsloggar och snabbare transaktionsincheckningstider oavsett datavolymer.
- Snabb utskalning – du kan etablera en eller flera skrivskyddade repliker för avlastning av läsarbetsbelastningen och för användning som frekventa väntelägen.
- Snabb uppskalning – du kan i konstant tid skala upp dina beräkningsresurser för att hantera tunga arbetsbelastningar vid behov och sedan skala ned beräkningsresurserna igen när de inte behövs.
Kommentar
SQL Database Hyperscale stöder inte följande funktioner:
- SQL-hanterad instans
- Elastiska pooler
- Geo-replikering
- Query Performance Insights
Distribuera Azure SQL Database Hyperscale
Så här distribuerar du Azure SQL Database med Hyperskala-nivån:
Bläddra till alternativsidan Välj SQL-distribution .
Under SQL-databaser lämnar du Resurstyp inställd på Enskild databas och väljer Skapa.
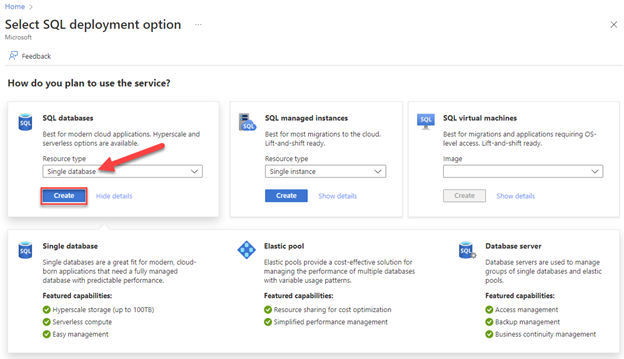
På fliken Grundläggande på sidan Skapa SQL Database väljer du önskad prenumeration, resursgrupp och databasnamn.
Välj länken Skapa ny för servern och fyll i den nya serverinformationen, till exempel servernamn, inloggning och lösenord för serveradministratör och plats.
Under Beräkning + lagring väljer du länken Konfigurera databas .
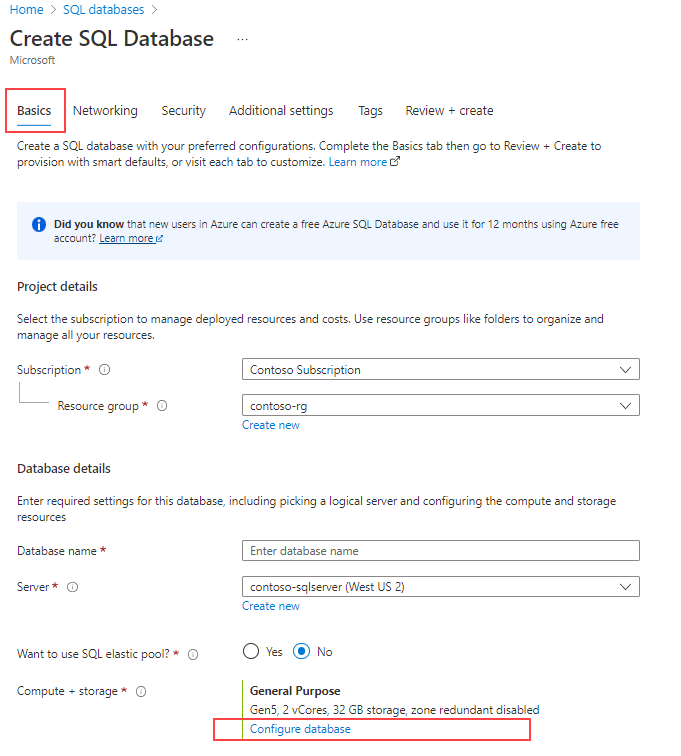
För Tjänstnivå väljer du Hyperskala.
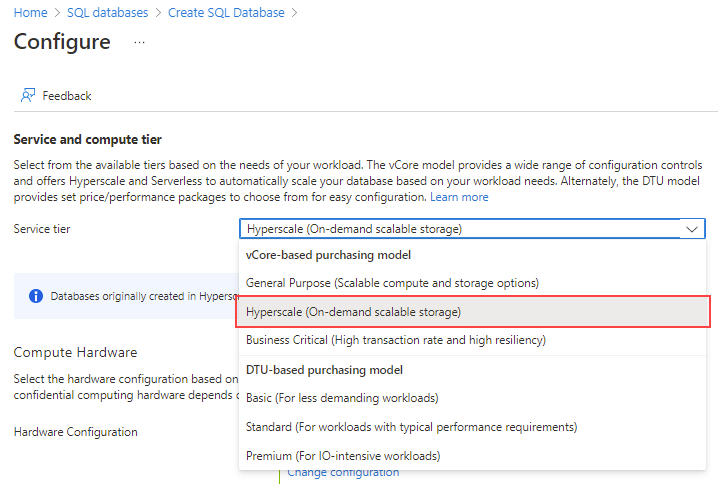
Under Maskinvarukonfiguration väljer du länken Ändra konfiguration . Granska de tillgängliga maskinvarukonfigurationerna och välj den lämpligaste konfigurationen för databasen. I det här exemplet väljer vi Gen5-konfigurationen .
Välj OK för att bekräfta maskinvarugenereringen.
Du kan också justera skjutreglaget för virtuella kärnor om du vill öka antalet virtuella kärnor för databasen. I det här exemplet väljer vi 2 virtuella kärnor.
Justera skjutreglaget för sekundära repliker med hög tillgänglighet för att skapa en ha-replik (hög tillgänglighet). Välj Använd.
Välj Nästa: Nätverk längst ned på sidan.
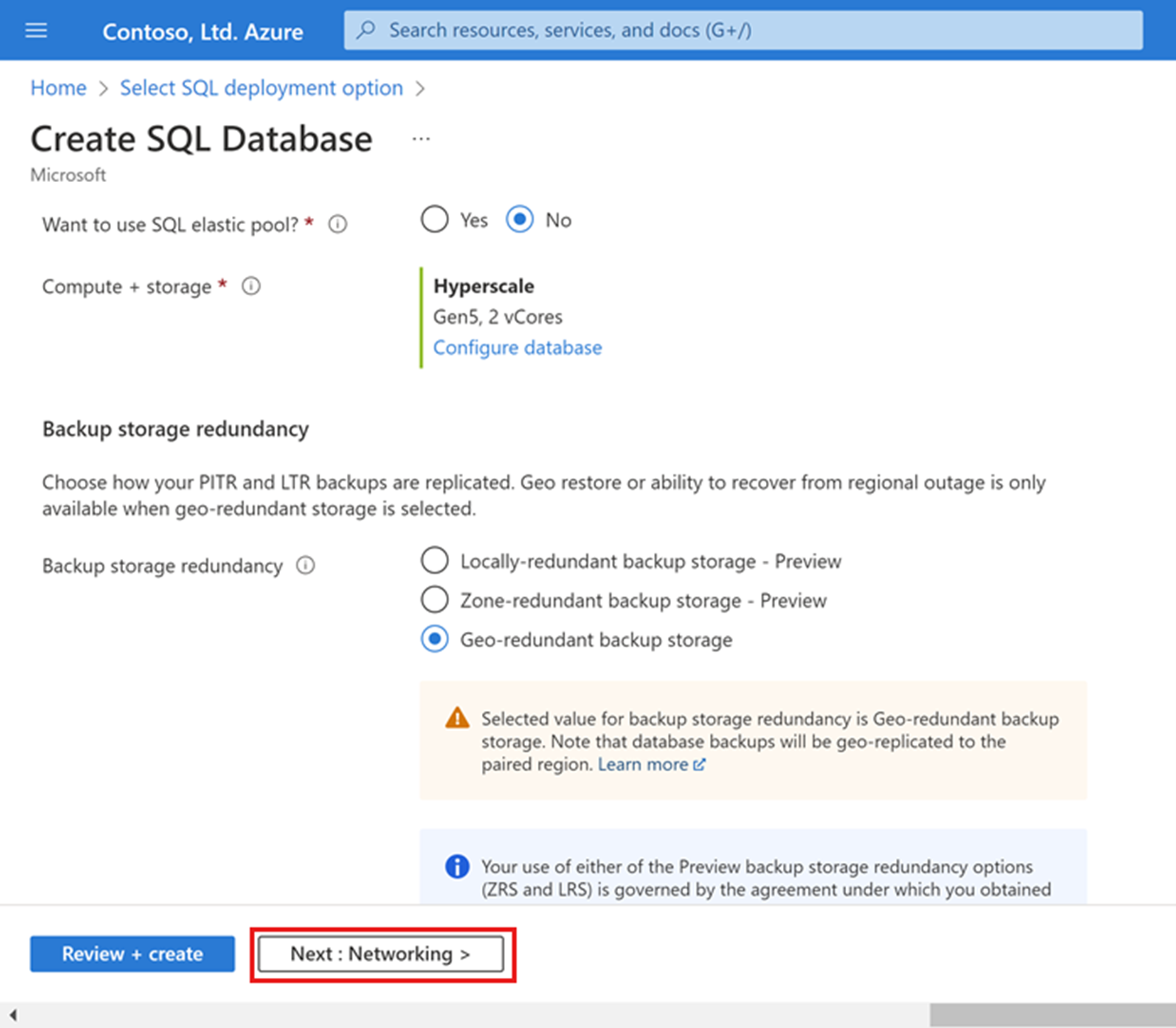
För Brandväggsregler på fliken Nätverk anger du Lägg till aktuell klient-IP-adress till Ja. Låt Tillåt Att Azure-tjänster och resurser får åtkomst till den här servern inställt på Nej.
Välj Nästa: Säkerhet längst ned på sidan.
På fliken Granska + skapa väljer du Skapa.
