Förklara PaaS-alternativ för att distribuera SQL Server i Azure
PaaS (Platform as a Service) tillhandahåller en fullständig utvecklings- och distributionsmiljö i molnet, som kan användas för enkla molnbaserade program samt för avancerade företagsprogram.
Azure SQL Database och Azure SQL Managed Instance ingår i PaaS-erbjudandet för Azure SQL.
Azure SQL Database – en del av en produktfamilj som bygger på SQL Server-motorn i molnet. Det ger utvecklare stor flexibilitet när det gäller att skapa nya programtjänster och detaljerade distributionsalternativ i stor skala. SQL Database erbjuder en lösning med lågt underhåll som kan vara ett bra alternativ för vissa arbetsbelastningar.
Azure SQL Managed Instance – Det är bäst för de flesta migreringsscenarier till molnet eftersom det tillhandahåller fullständigt hanterade tjänster och funktioner.
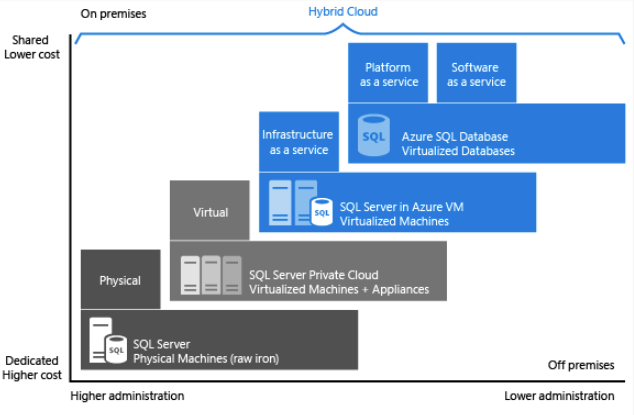
Som du ser i bilden ovan ger varje erbjudande en viss administrationsnivå som du har över infrastrukturen, beroende på graden av kostnadseffektivitet.
Distributionsmodeller
Azure SQL Database finns i två olika distributionsmodeller:
Enkel databas – en enkel databas som faktureras och hanteras på databasnivå. Du hanterar var och en av dina databaser individuellt från skalnings- och datastorleksperspektiv. Varje databas som distribueras i den här modellen har egna dedikerade resurser, även om den distribueras till samma logiska server.
Elastiska pooler – en grupp databaser som hanteras tillsammans och delar en gemensam uppsättning resurser. Elastiska pooler är en kostnadseffektiv lösning för programvara som en tjänstprogrammodell, eftersom resurser delas mellan alla databaser. Du kan konfigurera resurser baserat antingen på den DTU-baserade inköpsmodellen eller den vCore-baserade inköpsmodellen.
Köpmodell
I Azure backas alla tjänster upp av fysisk maskinvara och du kan välja mellan två olika inköpsmodeller:
Databastransaktionsenhet (DTU)
DTU:er beräknas baserat på en formel som kombinerar beräknings-, lagrings- och I/O-resurser. Det är ett bra val för kunder som vill ha enkla, förkonfigurerade resursalternativ.
DTU-inköpsmodellen finns på flera olika tjänstnivåer, till exempel Basic, Standard och Premium. Varje nivå har olika funktioner, vilket ger ett brett utbud av alternativ när du väljer den här plattformen.
När det gäller prestanda används Basic-nivån för mindre krävande arbetsbelastningar, medan Premium används för intensiva arbetsbelastningskrav.
Beräknings- och lagringsresurser är beroende av DTU-nivån, och de ger en mängd prestandafunktioner till en fast lagringsgräns, kvarhållning av säkerhetskopior och kostnad.
Kommentar
DTU-köpmodellen stöds endast av Azure SQL Database.
Mer information om köpmodellen för DTU finns i Översikt över DTU-baserad köpmodell.
V-kärna
Med modellen för virtuell kärna kan du köpa ett angivet antal virtuella kärnor baserat på dina arbetsbelastningar. virtuell kärna är standardköpsmodellen när du köper Azure SQL Database-resurser. vCore-databaser har en specifik relation mellan antalet kärnor och mängden minne och lagring som tillhandahålls till databasen. Köpmodellen för virtuella kärnor stöds av antingen Azure SQL Database och Azure SQL Managed Instance.
Du kan även köpa virtuella kärnor i tre olika tjänstnivåer:
Generell användning – Den här nivån är för arbetsbelastningar för generell användning. Den backas upp av Azure Premium Storage. Den har högre svarstid än Affärskritisk. Den innehåller också följande beräkningsnivåer:
- Etablerad – Beräkningsresurser är förallokerade. Faktureras per timme baserat på konfigurerade virtuella kärnor.
- Serverlös – Beräkningsresurser skalas automatiskt. Faktureras per sekund baserat på virtuella kärnor som används.
Affärskritisk – Den här nivån är avsedd för högpresterande arbetsbelastningar som erbjuder den lägsta svarstiden för någon av tjänstnivåerna. Den här nivån backas upp av lokala SSD:er i stället för Azure Blob Storage. Det ger också den högsta motståndskraften mot fel och ger en inbyggd skrivskyddad databasreplik som kan användas för rapporteringsarbetsbelastningar utanför belastningen.
Hyperskala – Hyperskala-databaser kan skalas långt bortom gränsen på 4 TB för andra Azure SQL Database-erbjudanden och har en unik arkitektur som stöder databaser på upp till 100 TB.
Utan server
Namnet "Serverlös" kan vara lite förvirrande eftersom du fortfarande distribuerar din Azure SQL Database till en logisk server som du ansluter till. Serverlös Azure SQL Database är en beräkningsnivå som automatiskt skalar upp eller ned resurserna för en viss databas baserat på efterfrågan på arbetsbelastningar. Om arbetsbelastningen inte längre kräver beräkningsresurser blir databasen "pausad" och endast lagring faktureras under den period som databasen är inaktiv. När ett anslutningsförsök görs "återupptas" databasen och blir tillgänglig.
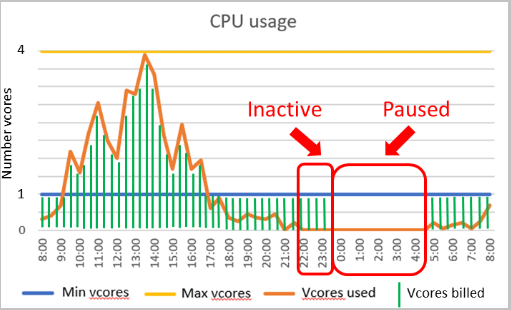
Inställningen för att styra pausning kallas för fördröjning av autopaus och har ett minimivärde på 60 minuter och ett maximalt värde på sju dagar. Om databasen har varit inaktiv under den tidsperioden pausas den.
När databasen har varit inaktiv under den angivna tiden pausas den tills en efterföljande anslutning görs. Att konfigurera ett beräkningsintervall för automatisk skalning och en fördröjning med automatisk paus påverkar databasens prestanda och beräkningskostnader.
Alla program som använder serverlös bör konfigureras för att hantera anslutningsfel och inkludera logik för återförsök, eftersom anslutning till en pausad databas genererar ett anslutningsfel.
En annan skillnad mellan serverlös och den normala virtuella kärnor-modellen i Azure SQL Database är att du med serverlös kan ange ett minsta och maximalt antal virtuella kärnor. Minnes- och I/O-gränser är proportionella mot det angivna intervallet.
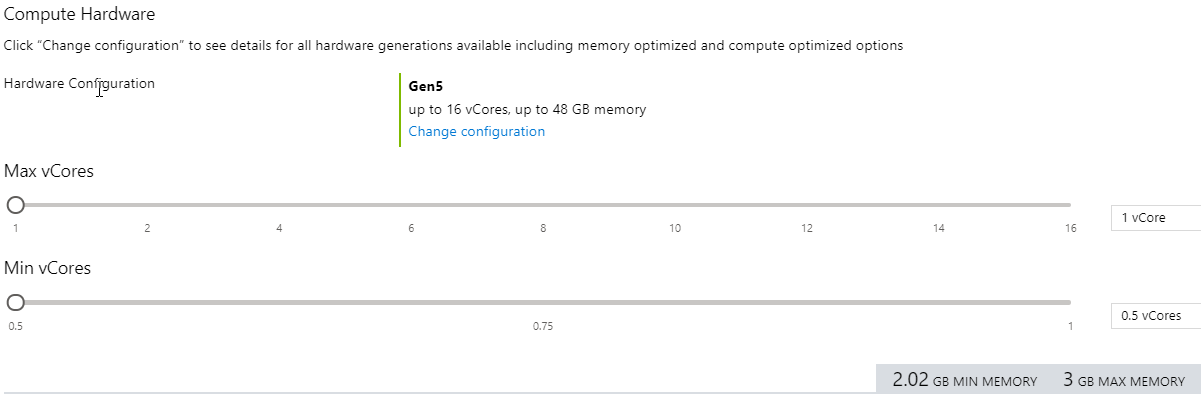
Bilden ovan visar konfigurationsskärmen för en serverlös databas i Azure-portalen. Du har möjlighet att välja ett minimum så lågt som hälften av en virtuell kärna och högst 16 virtuella kärnor.
Serverlös är inte helt kompatibel med alla funktioner i Azure SQL Database eftersom vissa av dem kräver att bakgrundsprocesser körs hela tiden, till exempel:
- Geo-replikering
- Långsiktig kvarhållning av säkerhetskopior
- En jobbdatabas i elastiska jobb
- Synkroniseringsdatabasen i SQL Data Sync (datasynkronisering är en tjänst som replikerar data mellan en grupp databaser)
Kommentar
SQL Database-serverlös stöds för närvarande endast på nivån Generell användning i köpmodellen för virtuell kärna.
Säkerhetskopior
En av de viktigaste funktionerna i erbjudandet Plattform som en tjänst är säkerhetskopieringar. I det här fallet utförs säkerhetskopior automatiskt utan några åtgärder från dig. Säkerhetskopior lagras i geo-redundant lagring i Azure Blob och behålls som standard i mellan 7 och 35 dagar, baserat på databasens tjänstnivå. Grundläggande databaser och virtuella kärnor är som standard sju dagars kvarhållning, och på databaserna med virtuella kärnor kan det här värdet justeras av administratören. Kvarhållningstiden kan förlängas genom att konfigurera långsiktig kvarhållning (LTR), vilket gör att du kan behålla säkerhetskopior i upp till 10 år.
För att tillhandahålla redundans kan du också använda lästillgänglig geo-redundant bloblagring. Den här lagringen replikerar dina databassäkerhetskopior till en sekundär region som du föredrar. Du kan också läsa från den sekundära regionen om det behövs. Manuella säkerhetskopior av databaser stöds inte, och plattformen nekar alla förfrågningar om att göra det.
Databassäkerhetskopior görs enligt ett visst schema:
- Full – en gång i veckan
- Differentiell – var 12:e timme
- Logg – var 5–10:e minut beroende på transaktionsloggaktivitet
Det här säkerhetskopieringsschemat bör uppfylla behoven för de flesta mål för återställningspunkt/tid (RPO/RTO), men varje kund bör utvärdera om de uppfyller dina affärskrav.
Det finns flera tillgängliga alternativ för att återställa en databas. På grund av typen plattform som en tjänst kan du inte manuellt återställa en databas med konventionella metoder, till exempel att utfärda T-SQL-kommandot RESTORE DATABASE.
Oavsett vilken återställningsmetod som implementeras går det inte att återställa över en befintlig databas. Om en databas behöver återställas måste den befintliga databasen tas bort eller byta namn innan återställningsprocessen påbörjas. Tänk dessutom på att återställningstiderna, beroende på plattformstjänstnivån, inte garanteras och kan variera. Vi rekommenderar att du testar återställningsprocessen för att få ett baslinjemått för hur lång tid en återställning kan ta.
De tillgängliga återställningsalternativen är:
Återställ med Hjälp av Azure-portalen – Med Hjälp av Azure-portalen kan du återställa en databas till samma Azure SQL Database-server, eller så kan du använda återställningen för att skapa en ny databas på en ny server i valfri Azure-region.
Återställ med skriptspråk – Både PowerShell och Azure CLI kan användas för att återställa en databas.
Kommentar
Kopieringssäkerhetskopiering till Azure Blob Storage är tillgänglig för SQL Managed Instance. SQL Database stöder inte den här funktionen.
Mer information om automatiserade säkerhetskopieringar finns i Automatiserade säkerhetskopieringar – Azure SQL Database och Azure SQL Managed Instance.
Aktiv geo-replikering
Geo-replikering är en funktion för affärskontinuitet som asynkront replikerar en databas till upp till fyra sekundära repliker. När transaktionerna checkas in till den primära (och dess repliker inom samma region) skickas transaktionerna till sekundärfilerna för att spelas upp igen. Eftersom den här kommunikationen sker asynkront behöver det anropande programmet inte vänta tills den sekundära repliken checkar in transaktionen innan SQL Server returnerar kontrollen till anroparen.
De sekundära databaserna är läsbara och kan användas för att avlasta skrivskyddade arbetsbelastningar, vilket frigör resurser för transaktionsarbetsbelastningar på den primära arbetsbelastningen eller placerar data närmare slutanvändarna. Dessutom kan de sekundära databaserna finnas i samma region som den primära eller i en annan Azure-region.
Med geo-replikering kan du initiera en redundansväxling manuellt av användaren eller från programmet. Om en redundansväxling inträffar måste du eventuellt uppdatera programmet anslutningssträng så att det återspeglar den nya slutpunkten för det som nu är den primära databasen.
Redundansgrupper
Redundansgrupper bygger på den teknik som används i geo-replikering, men ger en enda slutpunkt för anslutning. Den främsta orsaken till att använda redundansgrupper är att tekniken tillhandahåller slutpunkter som kan användas för att dirigera trafik till rätt replik. Programmet kan sedan ansluta efter en redundansväxling utan anslutningssträng ändringar.