Förstå begrepp för djupinlärning
I hjärnan har du nervceller som kallas nervceller, som är anslutna till varandra av nervförlängningar som passerar elektrokemiska signaler genom nätverket.

När den första neuronen i nätverket stimuleras bearbetas indatasignalen, och om den överskrider ett visst tröskelvärde aktiveras neuronen och skickar signalen vidare till de nervceller som den är ansluten till. Dessa neuroner i sin tur kan aktiveras och skicka signalen vidare genom resten av nätverket. Med tiden förstärks anslutningarna mellan neuronerna av frekvent användning när du lär dig att svara effektivt. Om du till exempel får en bild av en pingvin kan du med dina neuronanslutningar bearbeta informationen i bilden och dina kunskaper om egenskaperna hos en pingvin för att identifiera den som sådan. Med tiden, om du visas flera bilder av olika djur, växer nätverket av neuroner som är involverade i att identifiera djur baserat på deras karakteristiska egenskaper starkare. Med andra ord blir du bättre på att exakt identifiera olika djur.
Djupinlärning emulerar den här biologiska processen med hjälp av artificiella neurala nätverk som bearbetar numeriska indata snarare än elektrokemiska stimuli.
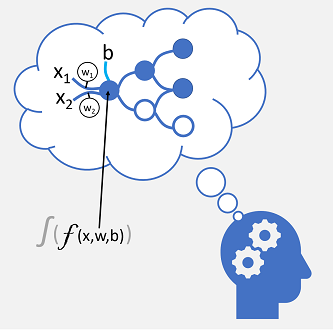
Inkommande nervanslutningar ersätts av numeriska indata som vanligtvis identifieras som x. När det finns fler än ett indatavärde anses x vara en vektor med elementen x1, x2 och så vidare.
Associerad med varje x-värde är en vikt (w), som används för att stärka eller försvaga effekten av x-värdet för att simulera inlärning. Dessutom läggs en bias -indata (b) till för att möjliggöra detaljerad kontroll över nätverket. Under träningsprocessen justeras w- och b-värdena för att justera nätverket så att det "lär sig" att producera korrekta utdata.
Själva neuronen kapslar in en funktion som beräknar en viktad summa av x, w och b. Den här funktionen omges i sin tur av en aktiveringsfunktion som begränsar resultatet (ofta till ett värde mellan 0 och 1) för att avgöra om neuronet skickar utdata till nästa lager av neuroner i nätverket.
Träna en djupinlärningsmodell
Djupinlärningsmodeller är neurala nätverk som består av flera lager av artificiella neuroner. Varje lager representerar en uppsättning funktioner som utförs på x-värdena med associerade w-vikter och b-fördomar, och det slutliga lagerresultatet på utdata från y-etiketten som modellen förutsäger. När det gäller en klassificeringsmodell (som förutsäger den mest sannolika kategorin eller klassen för indata) är utdata en vektor som innehåller sannolikheten för varje möjlig klass.
Följande diagram representerar en djupinlärningsmodell som förutsäger klassen för en dataentitet baserat på fyra funktioner (x-värdena). Modellens utdata ( y-värdena ) är sannolikheten för var och en av tre möjliga klassetiketter.
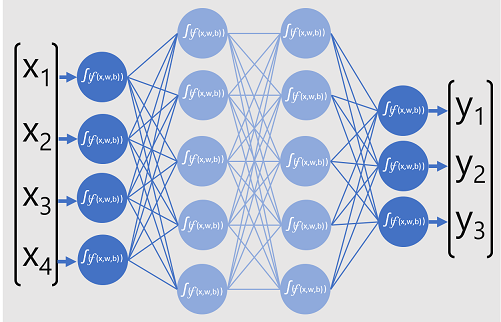
För att träna modellen matar ett ramverk för djupinlärning flera batchar med indata (för vilka de faktiska etikettvärdena är kända), tillämpar funktionerna i alla nätverksskikt och mäter skillnaden mellan utdataannolikheterna och de faktiska kända klassetiketterna för träningsdata. Den aggregerade skillnaden mellan förutsägelseutdata och de faktiska etiketterna kallas för förlusten.
Efter att ha beräknat den aggregerade förlusten för alla databatcherna använder djupinlärningsramverket en optimerare för att avgöra hur vikter och fördomar i modellen ska justeras för att minska den totala förlusten. Dessa justeringar backpropageras sedan till lagren i den neurala nätverksmodellen och sedan skickas data genom nätverket igen och förlusten beräknas om. Den här processen upprepas flera gånger (varje iteration kallas en epok) tills förlusten minimeras och modellen har "lärt sig" rätt vikter och fördomar för att kunna förutsäga korrekt.
Under varje epok justeras vikterna och fördomarna för att minimera förlusten. Den mängd som de justeras av styrs av den inlärningstakt som du anger för optimeringen. Om inlärningsfrekvensen är för låg kan träningsprocessen ta lång tid att fastställa optimala värden. men om den är för hög kanske optimeraren aldrig hittar de optimala värdena.