Förstå Azure Data Factory-komponenter
En Azure-prenumeration kan ha en eller flera Azure Data Factory-instanser. Azure Data Factory består av fyra kärnkomponenter. De här komponenterna samverkar för att tillhandahålla en plattform där du kan skapa datadrivna arbetsflöden med steg för att flytta och omvandla data.
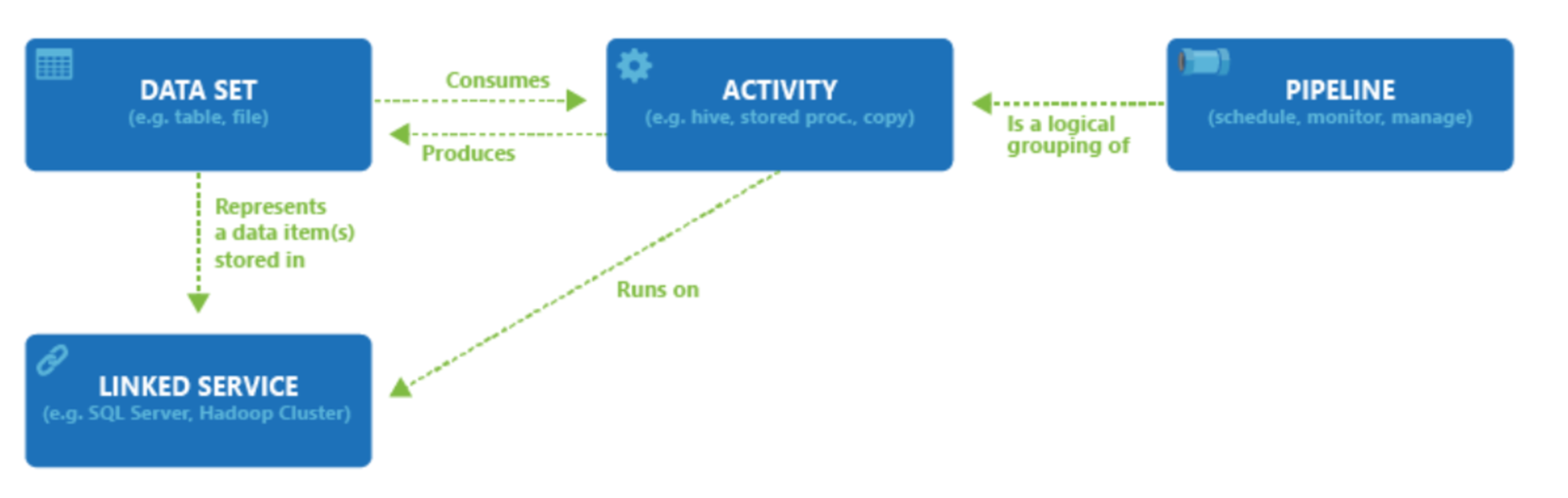
Data Factory stöder en mängd olika datakällor som du kan ansluta till genom att skapa ett objekt som kallas länkad tjänst, vilket gör att du kan mata in data från en datakälla i beredskap för att förbereda data för transformering och/eller analys. Dessutom kan Länkade tjänster starta beräkningstjänster på begäran. Du kan till exempel ha ett krav på att starta ett HDInsight-kluster på begäran för att bara bearbeta data via en Hive-fråga. Med Länkade tjänster kan du definiera datakällor eller beräkningsresurser som krävs för att mata in och förbereda data.
Med den länkade tjänsten definierad görs Azure Data Factory medveten om de datauppsättningar som den ska använda genom att skapa ett datauppsättningsobjekt . Datauppsättningar representerar datastrukturer i datalagret som refereras av objektet Länkad tjänst. Datauppsättningar kan också användas av ett ADF-objekt som kallas aktivitet.
Aktiviteter innehåller vanligtvis transformeringslogiken eller analyskommandona i Azure Data Factorys arbete. Aktiviteter inkluderar kopieringsaktiviteten som kan användas för att mata in data från en mängd olika datakällor. Den kan också innehålla Dataflöde mappning för att utföra kodfria datatransformeringar. Det kan också omfatta körning av en lagrad procedur, Hive Query eller Pig-skript för att transformera data. Du kan skicka data till en Machine Learning-modell för att utföra analys. Det är inte ovanligt att flera aktiviteter äger rum som kan innefatta att transformera data med hjälp av en SQL-lagrad procedur och sedan utföra analys med Databricks. I det här fallet kan flera aktiviteter grupperas logiskt tillsammans med ett objekt som kallas pipeline, och dessa kan schemaläggas att köras, eller så kan en utlösare definieras som avgör när en pipelinekörning måste startas. Det finns olika typer av utlösare för olika typer av händelser.
Kontrollflöde är en orkestrering av pipelineaktiviteter som inkluderar länkningsaktiviteter i en sekvens, förgrening, definition av parametrar på pipelinenivå och överföring av argument när pipelinen anropas på begäran eller från en utlösare. Den innehåller även containrar för anpassad tillståndsöverföring och loopning samt iteratorer för varje.
Parametrar är nyckel/värde-par med skrivskyddad konfiguration. Parametrar har definierats i pipelinen. Argumenten för de definierade parametrarna skickas vid körning från körningskontexten som skapats av en utlösare eller en pipeline som körs manuellt. Aktiviteter i pipelinen använder parametervärdena.
Azure Data Factory har en integreringskörning som gör det möjligt att överbrygga mellan aktiviteten och länkade tjänstobjekt. Den refereras av den länkade tjänsten och tillhandahåller beräkningsmiljön där aktiviteten körs eller skickas från. På så sätt kan aktiviteten utföras i den region som är närmast möjligt. Det finns tre typer av Integration Runtime, inklusive Azure, Self-hosted och Azure-SSIS.
När allt arbete är klart kan du sedan använda Data Factory för att publicera den slutliga datamängden till en annan länkad tjänst som sedan kan användas av tekniker som Power BI eller Machine Learning.