Förklara datafabriksprocessen
Datadrivna arbetsflöden
Pipelines (datadrivna arbetsflöden) i Azure Data Factory utför vanligen följande fyra steg:
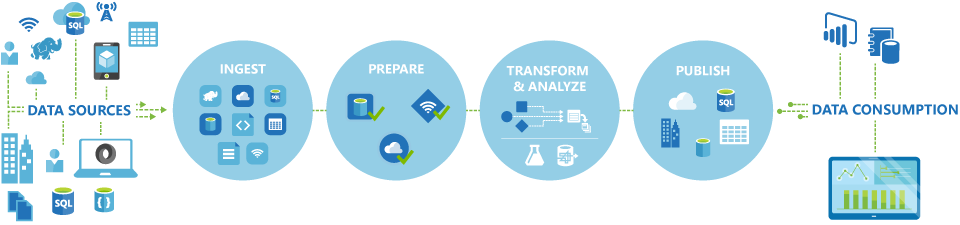
Ansluta och samla in
Det första steget i att skapa ett orkestreringssystem är att definiera och ansluta alla nödvändiga datakällor, till exempel databaser, filresurser och FTP-webbtjänster. Nästa steg är att mata in data efter behov till en central plats för efterföljande bearbetning.
Omvandla och berika
Beräkningstjänster som Databricks och Machine Learning kan användas för att förbereda eller producera transformerade data enligt ett underhållsbart och kontrollerat schema för att mata produktionsmiljöer med rensade och transformerade data. I vissa fall kan du till och med utöka källdata med ytterligare data för att underlätta analysen eller konsolidera dem genom en normaliseringsprocess som ska användas i ett Machine Learning-experiment som exempel.
Publicera
När rådata har förfinats till ett företagsklart förbrukningsformulär från transformerings- och berikarfasen kan du läsa in data i Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB eller den analysmotor som företagsanvändarna kan peka på från sina business intelligence-verktyg
Monitor
Azure Data Factory har inbyggt stöd för pipelineövervakning via Azure Monitor, API, PowerShell, Azure Monitor-loggar och hälsopaneler på Azure Portal för att övervaka schemalagda aktiviteter och pipelines för framgångs- och felfrekvens.