Övning – Lägga till en anpassad nodmatris i ett HPC-kluster
Varning
Det här innehållet refererar till CentOS, en Linux-distribution som har statusen End Of Life (EOL). Överväg att använda och planera i enlighet med detta. Mer information finns i CentOS End Of Life-vägledningen.
En nodearray är en samling identiskt konfigurerade noder i ett Azure CycleCloud-kluster. Syftet är att hantera den horisontella skalningen av klusterberäkningsresurserna när antalet jobb i kö ändras. Varje nodearray har ett namn, en uppsättning attribut som gäller för var och en av noderna och valfria attribut som beskriver hur nodearray ska skalas.
Slurm-jobbschemaläggaren partitionerar noder i logiska och potentiellt överlappande uppsättningar. Syftet är att optimera bearbetningen av jobb genom att ta hänsyn till deras specifika begränsningar, till exempel resurs- eller tidsgränser. Schemaläggaren allokerar jobb till noder i en partition tills deras resurser är uttömda eller alla jobb bearbetas.
Du vill ändra ditt nyligen distribuerade Azure CycleCloud-hanterade kluster för att ta hänsyn till jobbspecifika resursbehov. För att uppnå det här målet bestämmer du dig för att tillämpa fler ändringar på den underliggande mallen och verifiera din metod.
I den här övningen utför du följande uppgifter:
- Uppgift 1: Lägga till en nodearray-definition i Azure CycleCloud-mallen
- Uppgift 2: Lägg till grafiska gränssnittsparametrar i Azure CycleCloud-mallen
- Uppgift 3: Exportera Azure CycleCloud-klusteregenskaper
- Uppgift 4: Redigera egenskapsfilen så att den innehåller de nya parametrarna
- Uppgift 5: Importera den ändrade mallen och parameterfilen till det befintliga klustret
Kommentar
Kontrollera att du har slutfört föregående övning innan du påbörjar den här övningen.
Uppgift 1: Lägga till en nodearray-definition i Azure CycleCloud-mallen
Du börjar med att lägga till en definition av en nodearray i Slurm-mallen som du anpassade i föregående övning. Exempelmallen innehåller två partitioner märkta hpc och htc. Du skapar en annan partition och motsvarande nodearray som är avsedd för jobb som drar nytta av CUDA-funktionerna (Compute Unified Device Architecture).
Navigera till Azure-portalen. När du uppmanas att autentisera med ett Microsoft-konto eller ett Microsoft Entra-konto som har rollen Deltagare eller Ägare i Den Azure-prenumeration som du använder i den här modulen.
Från Azure Portal öppnar du Cloud Shell genom att välja dess ikon i verktygsfältet bredvid söktextrutan och se till att du kör en Bash-session.
Kör följande kommando i Cloud Shell för att ange arbetskatalogen till den som är värd för den GitHub-lagringsplats som du hämtade i föregående övning:
cd ~/cyclecloud-slurm/templatesKör följande kommando för att öppna den nedladdade mallen i nanoredigeraren:
nano slurm.txtI nano-redigerargränssnittet bläddrar du till
[parameters About]avsnittet och lägger till följande innehåll direkt före det:[[nodearray cuda]] MachineType = $CUDAMachineType ImageName = $CUDAImageName MaxCoreCount = $MaxCUDAExecuteCoreCount AdditionalClusterInitSpecs = $CUDAClusterInitSpecs [[[configuration]]] slurm.autoscale = true slurm.hpc = true [[[cluster-init cyclecloud/slurm:execute]]] [[[network-interface eth0]]] AssociatePublicIpAddress = $ExecuteNodesPublicKommentar
Om du använder en Windows-dator kan du klistra in innehållet i Urklipp med hjälp av tangentkombinationen Skift + Infoga .
Kommentar
Dina ändringar definierar en extra nodearray.
Uppgift 2: Lägg till grafiska gränssnittsparametrar i Azure CycleCloud-mallen
För att kunna ändra värdena för mallparametrar med det grafiska Gränssnittet Azure CycleCloud tillämpar du fler ändringar i mallen.
I nano-redigerargränssnittet bläddrar du till
[[parameters Auto-Scaling]]avsnittet och lägger till följande innehåll direkt före det:[[[parameter CUDAMachineType]]] Label = CUDA VM Type Description = The VM type for CUDA execute nodes ParameterType = Cloud.MachineType DefaultValue = Standard_NC24Rulla till avsnittet
[[[parameter HPCMaxScalesetSize]]]och lägg till följande innehåll direkt före det:[[[parameter MaxCUDAExecuteCoreCount]]] Label = Max CUDA Cores Description = The total number of CUDA execute cores to start DefaultValue = 100 Config.Plugin = pico.form.NumberTextBox Config.MinValue = 0 Config.IntegerOnly = trueRulla till avsnittet
[[[parameter SchedulerClusterInitSpecs]]]och lägg till följande innehåll direkt före det:[[[parameter CUDAImageName]]] Label = CUDA OS ParameterType = Cloud.Image Config.OS = linux DefaultValue = cycle.image.centos7 Config.Filter := Package in {"cycle.image.centos7", "cycle.image.ubuntu18"}Rulla till avsnittet
[[parameters Advanced Networking]]och lägg till följande innehåll direkt före det:[[[parameter CUDAClusterInitSpecs]]] Label = CUDA Cluster-Init DefaultValue = =undefined Description = Cluster init specs to apply to CUDA execute nodes ParameterType = Cloud.ClusterInitSpecsVälj tangentkombinationen Ctrl + O, välj returnyckelnoch välj sedan tangentkombinationen Ctrl + X för att spara de ändringar du har gjort och stänga filen.
Uppgift 3: Exportera Azure CycleCloud-klusteregenskaper
Innan du tillämpar konfigurationsändringarna som du gjorde i Azure CycleCloud-mallen på målklustret måste du först exportera klusteregenskaperna.
Kör följande kommando i Cloud Shell för att visa en lista över befintliga kluster:
cyclecloud show_clusterKommentar
Kontrollera att utdata innehåller posten contoso-custom-slurm-lab-cluster .
Kör följande kommando för att exportera till filen params.json listan över parametrar i klustret contoso-custom-slurm-lab-cluster och deras värden:
cyclecloud export_parameters contoso-custom-slurm-lab-cluster > ~/params.jsonKör följande kommando för att granska den exporterade listan med parametrar och deras värden:
cat ~/params.json
Uppgift 4: Redigera egenskapsfilen så att den innehåller de nya parametrarna
Även om de ändringar som du tillämpade på Azure CycleCloud-mallen innehöll standardvärden för alla nyligen introducerade parametrar, kan du behöva ändra dem för att ta hänsyn till dina specifika krav. I den här uppgiften anger du värdena för parametrarna CUDAMachineType och MaxCUDAExecuteCoreCount .
Kör följande kommando i Cloud Shell för att öppna filen med nedladdade parametrar i nanoredigeraren:
nano ~/params.jsonI nanoredigeraren bläddrar du till slutet av filen och lägger till följande innehåll som börjar med en ny rad före de avslutande klammerparenteserna (}):
"CUDAMachineType" : "Standard_NC6", "MaxCUDAExecuteCoreCount" : 60Lägg till ett kommatecken i slutet av raden före raden som du lade till i föregående steg:
"CUDAMachineType" : "Standard_NC6"Välj tangentkombinationen Ctrl + O, välj returnyckelnoch välj sedan tangentkombinationen Ctrl + X för att spara de ändringar du har gjort och stänga filen.
Uppgift 5: Importera den ändrade mallen och parameterfilen till det befintliga klustret
För att slutföra den här övningen importerar du den ändrade mallen och dess parameterfil till det befintliga klustret, vilket överskrider den aktuella konfigurationen.
Kör följande kommando i Cloud Shell för att importera den ändrade mallen och dess parameterfil till det befintliga klustret:
cyclecloud import_cluster contoso-custom-slurm-lab-cluster --file ~/cyclecloud-slurm/templates/slurm.txt -p ~/params.json -c Slurm --forceKommentar
Du måste ange namnet på målklustret och
--forceflaggan för att skriva över det befintliga klustrets konfiguration.Öppna ett annat webbläsarfönster på datorn och gå till url: en https://< IP_address> . Bekräfta att du vill fortsätta om du uppmanas att göra det.
Om du uppmanas att autentisera loggar du in genom att ange autentiseringsuppgifter för samma Azure CycleCloud-programanvändarkonto som du använde för att konfigurera Azure CycleCloud CLI.
I det grafiska Gränssnittet Azure CycleCloud går du till sidan Kluster . I listan över kluster väljer du posten contoso-custom-slurm-lab-cluster och väljer sedan Redigera.
I popup-fönstret Redigera contoso-custom-slurm-lab-cluster väljer du Nästa på sidan Om.
På sidan Obligatoriska inställningar kontrollerar du förekomsten av posten CUDA VM Type inställd på Standard_NC6 värde och motsvarande alternativ för automatisk skalning:
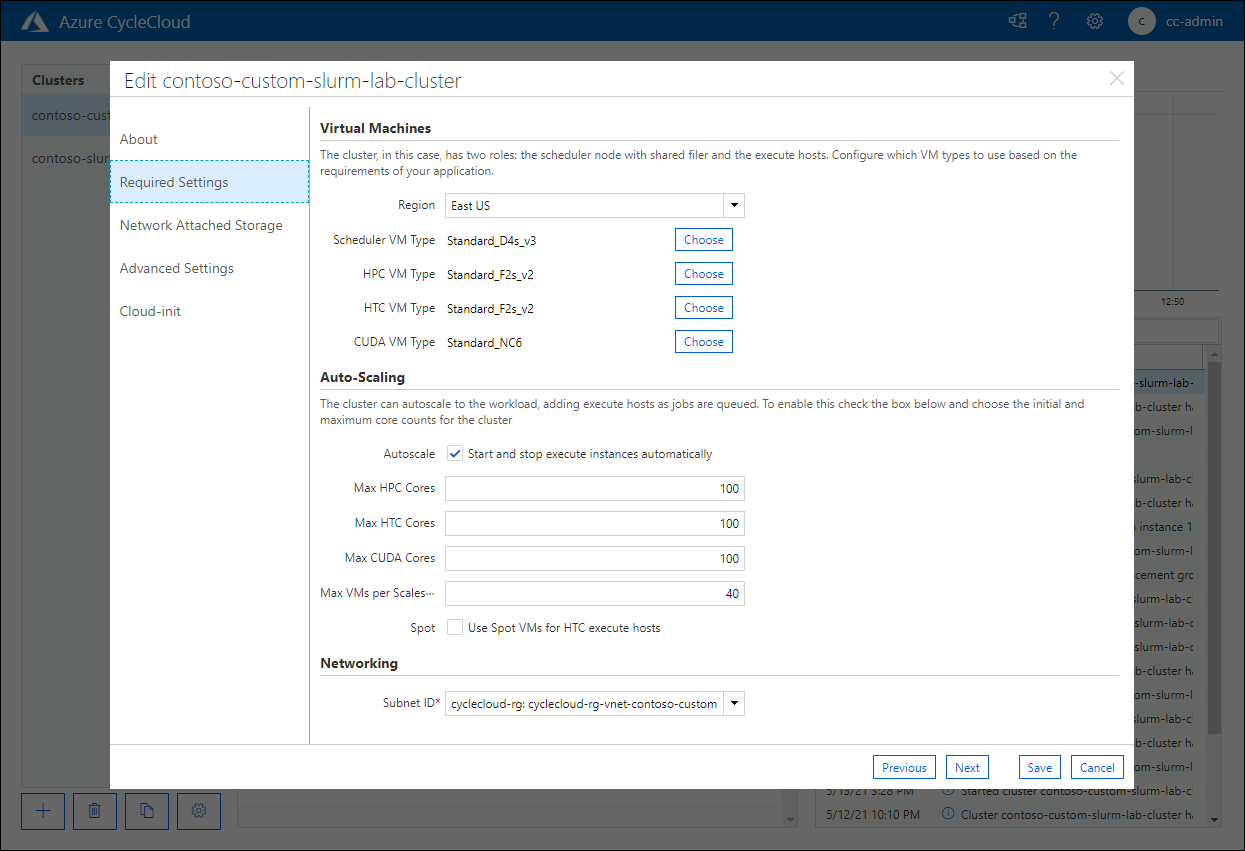
Grattis! Du har slutfört den andra övningen i den här modulen. I den här övningen anpassade du ditt Azure CycleCloud-kluster ytterligare med hjälp av en modifierad mall, inklusive definitionen av en ny nodearray med motsvarande partition. När du har redigerat mallen har du exporterat och redigerat klusterparametrar och importerat den, tillsammans med den ändrade mallen, till klustret.
Kommentar
Ta inte bort de resurser som du distribuerade och konfigurerade i den här övningen om du planerar att köra nästa övning. Dessa resurser krävs för att slutföra nästa övning.