Övning – Köra frågor i HDInsight Spark-kluster
I den här övningen får du lära dig hur du skapar en dataram från en csv-fil och hur du kör interaktiva Spark SQL-frågor mot ett Apache Spark-kluster i Azure HDInsight. I Spark är en dataram en distribuerad datasamling som har ordnats i namngivna kolumner. Dataramen motsvarar en tabell i en relationsdatabas eller en dataram i R/Python.
I den här självstudien lär du dig att:
- Skapa en dataram från en csv-fil
- Köra frågor i dataramen
Skapa en dataram från en csv-fil
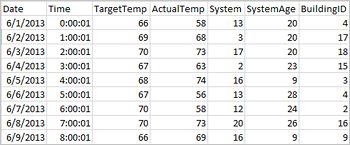
Följande csv-exempelfil innehåller temperaturinformation för en byggnad och lagras i filsystemet i Spark-klustret.
Klistra in följande kod i en tom cell i Jupyter Notebook och tryck sedan på SKIFT + RETUR för att köra koden. Koden importerar de typer som krävs för det här scenariot
from pyspark.sql import * from pyspark.sql. types import *När du kör en interaktiv fråga i Jupyter visar fönstret i webbläsaren eller fliktiteln statusen (Upptagen) tillsammans med anteckningsbokens titel. Du ser även en fylld cirkel bredvid PySpark-texten i det övre högra hörnet. När jobbet har slutförts ändras detta till en tom cirkel.
Kör följande kod för att skapa en dataram och en tillfällig tabell (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
Köra frågor i dataramen
När tabellen har skapats kan du köra en interaktiv fråga på datan.
Kör följande kod i en tom cell i anteckningsboken:
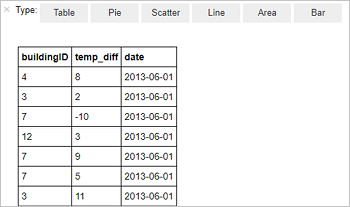
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Följande tabellutdata visas.
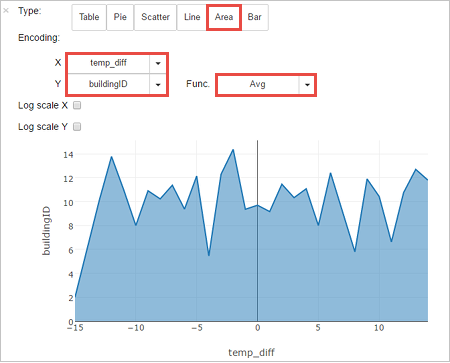
Du kan också visa resultaten i andra visualiseringar. Om du vill se ett ytdiagram för samma utdata väljer du Yta och anger sedan de andra värden som visas.
Från menyraden för notebook-filer går du till Spara fil > och Kontrollpunkt.
Stäng anteckningsboken för att frigöra klusterresurserna: från menyraden för notebook-filer går du till Arkivstängning > och Stoppa.