Öppna en Jupyter Notebook i HDInsight Spark-kluster
När HDInsight Spark-klustret har skapats kan du köra interaktiva Spark SQL-frågor eller jobb mot ett Apache Spark-kluster i Azure HDInsight. För att kunna göra detta måste du först skapa en notebook-fil. En notebook-fil är en interaktiv redigerare som gör det möjligt för Dataingenjör och Dataforskare att använda en mängd olika språk för att interagera med data. Detta kan omfatta Python, SQL, Scala och andra språk. HDInsight har stöd för Jupyter, Zeppelin och Livy för att interagera med data. Interaktionsnivån beror på vilken arbetsbelastning du hanterar.
Apache Spark på HDInsight stöder följande arbetsbelastningar:
Interaktiv dataanalys och BI
Du kan använda en notebook-fil för att mata in ostrukturerade/halvstrukturerade data och sedan definiera ett schema i anteckningsboken. Du kan sedan använda schemat för att skapa en modell i verktyg som Power BI som gör det möjligt för företagsanvändare att utföra dataanalys på data i notebook-filen
Spark-maskininlärning
Du kan använda en notebook-fil för att arbeta med MLlib (ett maskininlärningsbibliotek som bygger på Spark) för att skapa maskininlärningsprogram
Spark-strömning och dataanalys i realtid
Spark-kluster i HDInsight innehåller omfattande stöd för att skapa lösningar för realtidsanalys. Spark har redan anslutningsappar för att mata in data från många källor som Kafka, Flume, X, ZeroMQ eller TCP-socketar, men Spark i HDInsight lägger till förstklassigt stöd för att mata in data från Azure Event Hubs.
Skapa en Jupyter-anteckningsbok
Använd följande steg för att skapa en Jupyter-anteckningsbok i Azure Portal.
I avsnittet Klusterinstrumentpaneler i portalen väljer du Jupyter Notebook. Ange autentiseringsuppgifterna för klusterinloggning för klustret om du uppmanas att göra det.
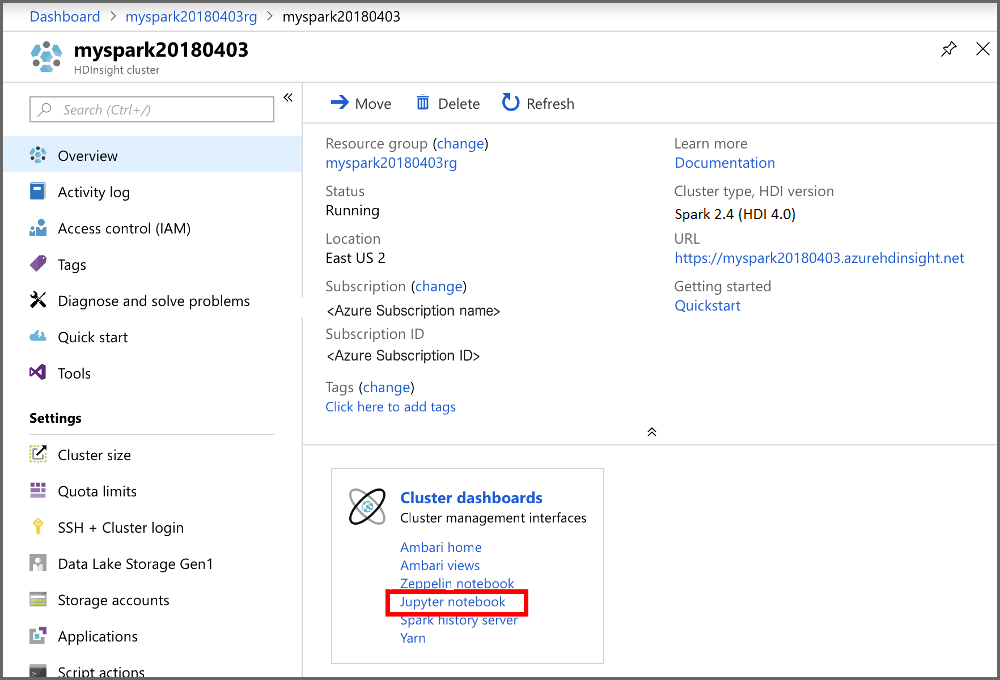
Välj Ny > PySpark för att skapa en notebook-fil.
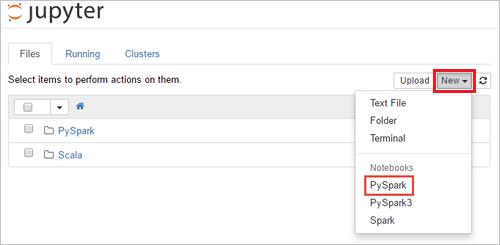
En ny notebook-fil skapas och öppnas med namnet Untitled (Untitled.pynb) som gör att du kan börja skapa jobb kör frågor