Använda text-till-tal-API:et
På samma sätt som tal till text-API :er erbjuder Azure AI Speech-tjänsten andra REST-API:er för talsyntes:
- API:et text till tal , vilket är det primära sättet att utföra talsyntes.
- Batch-syntes-API:et, som är utformat för att stödja batchåtgärder som konverterar stora mängder text till ljud , till exempel för att generera en ljudbok från källtexten.
Du kan läsa mer om REST API:er i dokumentationen för REST API för text till tal. I praktiken använder de flesta interaktiva talaktiverade program Azure AI Speech-tjänsten via en (programmering) språkspecifik SDK.
Använda Azure AI Speech SDK
Precis som med taligenkänning skapas i praktiken de flesta interaktiva talaktiverade program med Hjälp av Azure AI Speech SDK.
Mönstret för att implementera talsyntes liknar taligenkänning:
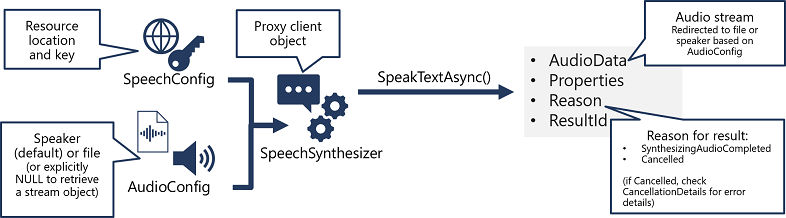
- Använd ett SpeechConfig-objekt för att kapsla in den information som krävs för att ansluta till din Azure AI Speech-resurs. Mer specifikt dess plats och nyckel.
- Du kan också använda en AudioConfig för att definiera utdataenheten för talet som ska syntetiseras. Som standard är detta standardsystemhögtalaren, men du kan också ange en ljudfil, eller genom att uttryckligen ange värdet till ett null-värde, kan du bearbeta ljudströmsobjektet som returneras direkt.
- Använd SpeechConfig och AudioConfig för att skapa ett SpeechSynthesizer-objekt. Det här objektet är en proxyklient för API:et Text till tal .
- Använd metoderna för SpeechSynthesizer-objektet för att anropa de underliggande API-funktionerna. Metoden SpeakTextAsync() använder till exempel Azure AI Speech-tjänsten för att konvertera text till talat ljud.
- Bearbeta svaret från Azure AI Speech-tjänsten. När det gäller metoden SpeakTextAsync är resultatet ett SpeechSynthesisResult-objekt som innehåller följande egenskaper:
- AudioData
- Egenskaper
- Anledning
- ResultId
När tal har syntetiserats är egenskapen Reason inställd på synthesizingAudioCompleted-uppräkningen och egenskapen AudioData innehåller ljudströmmen (som, beroende på AudioConfig , automatiskt har skickats till en talare eller fil).