Anpassad textklassificeringsfärdighet
Med anpassad textklassificering kan du mappa ett textavsnitt till olika användardefinierade klasser. Du kan till exempel träna en modell på synopsisen på baksidan av böcker för att automatiskt identifiera en bokgenre. Du använder sedan den identifierade genren för att berika din sökmotor i onlinebutiken med en genrefasettering.
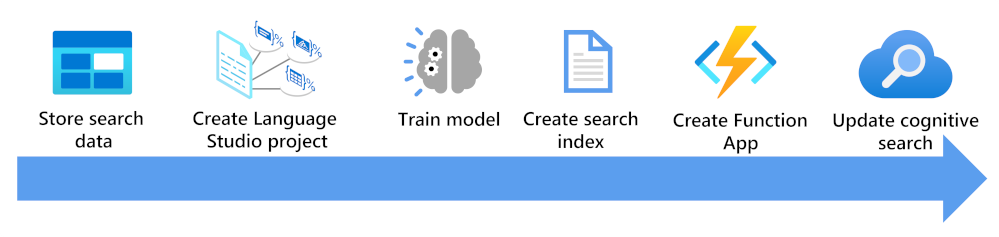
Här ser du vad du behöver tänka på för att utöka ett sökindex med hjälp av en anpassad textklassificeringsmodell:
- Lagra dina dokument så att de kan nås av Language Studio- och Azure AI Search-indexerare.
- Skapa ett anpassat textklassificeringsprojekt.
- Träna och testa din modell.
- Skapa ett sökindex baserat på dina lagrade dokument.
- Skapa en funktionsapp som använder din distribuerade tränade modell.
- Uppdatera din söklösning, ditt index, indexerare och din anpassade kompetensuppsättning.
Lagra dina data
Azure Blob Storage kan nås från både Language Studio och Azure AI Services. Containern måste vara tillgänglig, så det enklaste alternativet är att välja Container, men det är också möjligt att använda privata containrar med ytterligare konfiguration.
Tillsammans med dina data behöver du också ett sätt att tilldela klassificeringar för varje dokument. Language Studio innehåller ett grafiskt verktyg som du kan använda för att klassificera varje dokument en i taget manuellt.
Du kan välja mellan två olika typer av projekt. Om ett dokument mappas till en enskild klass använder du ett klassificeringsprojekt med en etikett. Om du vill mappa ett dokument till mer än en klass använder du klassificeringsprojektet för flera etiketter.
Om du inte vill klassificera varje dokument manuellt kan du märka alla dokument innan du skapar ditt Azure AI Language-projekt. Den här processen innebär att skapa ett JSON-dokument för etiketter i det här formatet:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
Du lägger till så många klasser som du har i matrisen classes . Du lägger till en post för varje dokument i matrisen documents , inklusive vilka klasser dokumentet matchar.
Skapa ditt Azure AI Language-projekt
Det finns två sätt att skapa ditt Azure AI Language-projekt. Om du börjar använda Language Studio utan att först skapa en språktjänst i Azure Portal erbjuder Language Studio att skapa en åt dig.
Det mest flexibla sättet att skapa ett Azure AI Language-projekt är att först skapa din språktjänst med hjälp av Azure Portal. Om du väljer det här alternativet får du möjlighet att lägga till anpassade funktioner.
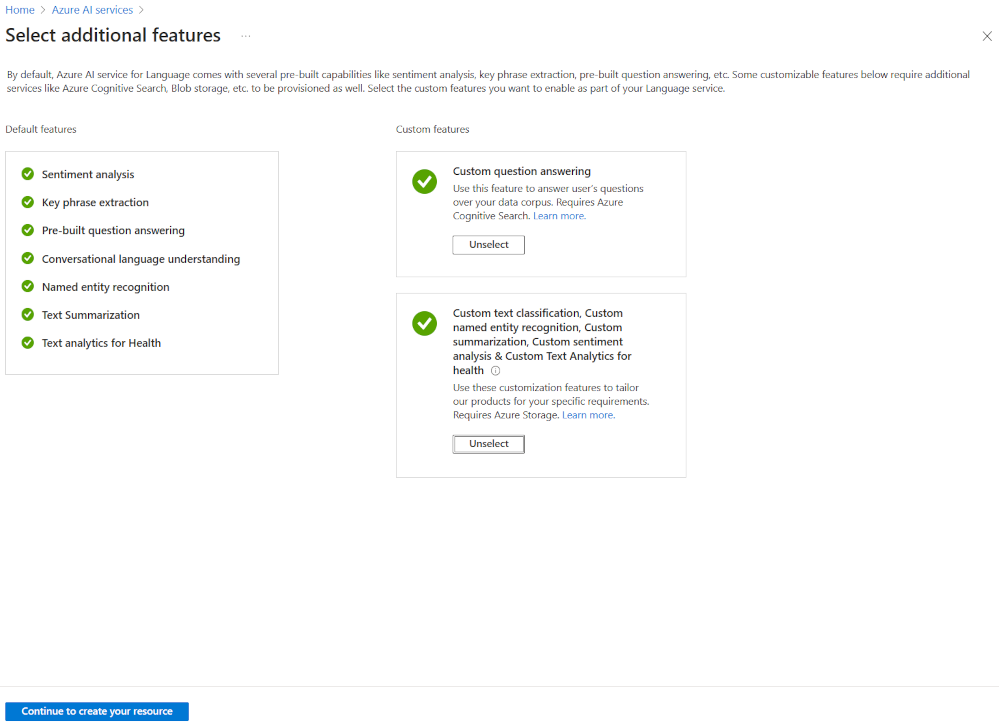
När du ska skapa en anpassad textklassificering väljer du den anpassade funktionen när du skapar din språktjänst. Du länkar även språktjänsten till ett lagringskonto med den här metoden.
När resursen har distribuerats kan du navigera direkt till Language Studio från översiktsfönstret för språktjänsten. Du kan sedan skapa ett nytt anpassat textklassificeringsprojekt.
Kommentar
Om du har skapat din språktjänst från Language Studio kan du behöva följa dessa steg. Ange roller för din Azure Language-resurs och ditt lagringskonto för att ansluta lagringscontainern till ditt anpassade textklassificeringsprojekt.
Träna klassificeringsmodellen
Precis som med alla AI-modeller måste du ha identifierat data som du kan använda för att träna dem. Modellen måste se exempel på hur du mappar data till en klass och har några exempel som den kan använda för att testa modellen. Du kan välja att låta modellen automatiskt dela dina träningsdata. Som standard använder den 80 % av dokumenten för att träna modellen och 20 % för att blindtesta den. Om du har några specifika dokument som du vill testa din modell med kan du märka dokument för testning.

I Language Studio väljer du Dataetiketter i projektet. Du ser alla dokument. Välj varje dokument som du vill lägga till i testuppsättningen och välj sedan Testa modellens prestanda. Spara dina uppdaterade etiketter och skapa sedan ett nytt träningsjobb.
Skapa sökindex
Det finns inget specifikt du behöver göra för att skapa ett sökindex som berikas av en anpassad textklassificeringsmodell. Följ stegen i Skapa en Azure AI Search-lösning. Du kommer att uppdatera indexet, indexeraren och den anpassade färdigheten när du har skapat en funktionsapp.
Skapa en Azure-funktionsapp
Du kan välja det språk och de tekniker som du vill använda för din funktionsapp. Appen måste kunna skicka JSON till slutpunkten för anpassad textklassificering, till exempel:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Bearbeta sedan JSON-svaret från modellen, till exempel:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
Funktionen returnerar sedan ett strukturerat JSON-meddelande tillbaka till en anpassad kompetensuppsättning i AI Search, till exempel:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
Det finns fem saker som funktionsappen behöver veta:
- Texten som ska klassificeras.
- Slutpunkten för din tränade distribuerade modell för anpassad textklassificering.
- Primärnyckeln för det anpassade textklassificeringsprojektet.
- Projektnamnet.
- Distributionsnamnet.
Texten som ska klassificeras skickas från din anpassade kompetensuppsättning i AI Search till funktionen som indata. De återstående fyra objekten finns i Language Studio.

Slutpunkten och distributionsnamnet finns i fönstret distribuera en modell.

Projektnamnet och primärnyckeln finns i fönstret projektinställningar.
Uppdatera din Azure AI Search-lösning
Det finns tre ändringar i Azure Portal du behöver göra för att utöka ditt sökindex:
- Du måste lägga till ett fält i indexet för att lagra den anpassade textklassificeringsberikningen.
- Du måste lägga till en anpassad kompetensuppsättning för att anropa funktionsappen med texten som ska klassificeras.
- Du måste mappa svaret från kunskapsuppsättningen till indexet.
Lägga till ett fält i ett befintligt index
I Azure Portal går du till din AI Search-resurs, väljer indexet och lägger till JSON i det här formatet:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Den här JSON-filen lägger till ett sammansatt fält i indexet för att lagra klassen i ett category fält som är sökbart. Det andra confidenceScore fältet lagrar konfidensprocenten i ett dubbelt fält.
Redigera den anpassade kompetensuppsättningen
I Azure Portal väljer du kompetensuppsättningen och lägger till JSON i det här formatet:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Den här WebApiSill kunskapsdefinitionen anger att språket och innehållet i ett dokument skickas som indata till funktionsappen. Appen returnerar JSON-text med namnet class.
Mappa utdata från funktionsappen till indexet
Den senaste ändringen är att mappa utdata till indexet. I Azure Portal väljer du indexeraren och redigerar JSON för att ha en ny utdatamappning:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
Indexeraren vet nu att utdata från funktionsappen document/class ska lagras i fältet classifiedtext . Eftersom detta har definierats som ett sammansatt fält måste funktionsappen returnera en JSON-matris som innehåller ett och-fält category confidenceScore .
Nu kan du söka i ett utökat sökindex efter din anpassade klassificerade text.