Beskriva intelligent frågebearbetning
I SQL Server 2017 och 2019, och med Azure SQL, har Microsoft introducerat många nya funktioner i kompatibilitetsnivåer 140 och 150. Många av dessa funktioner korrigerar vad som tidigare var antimönster som att använda användardefinierade skalära värdefunktioner och använda tabellvariabler.
Dessa funktioner delas in i några familjer med funktioner:
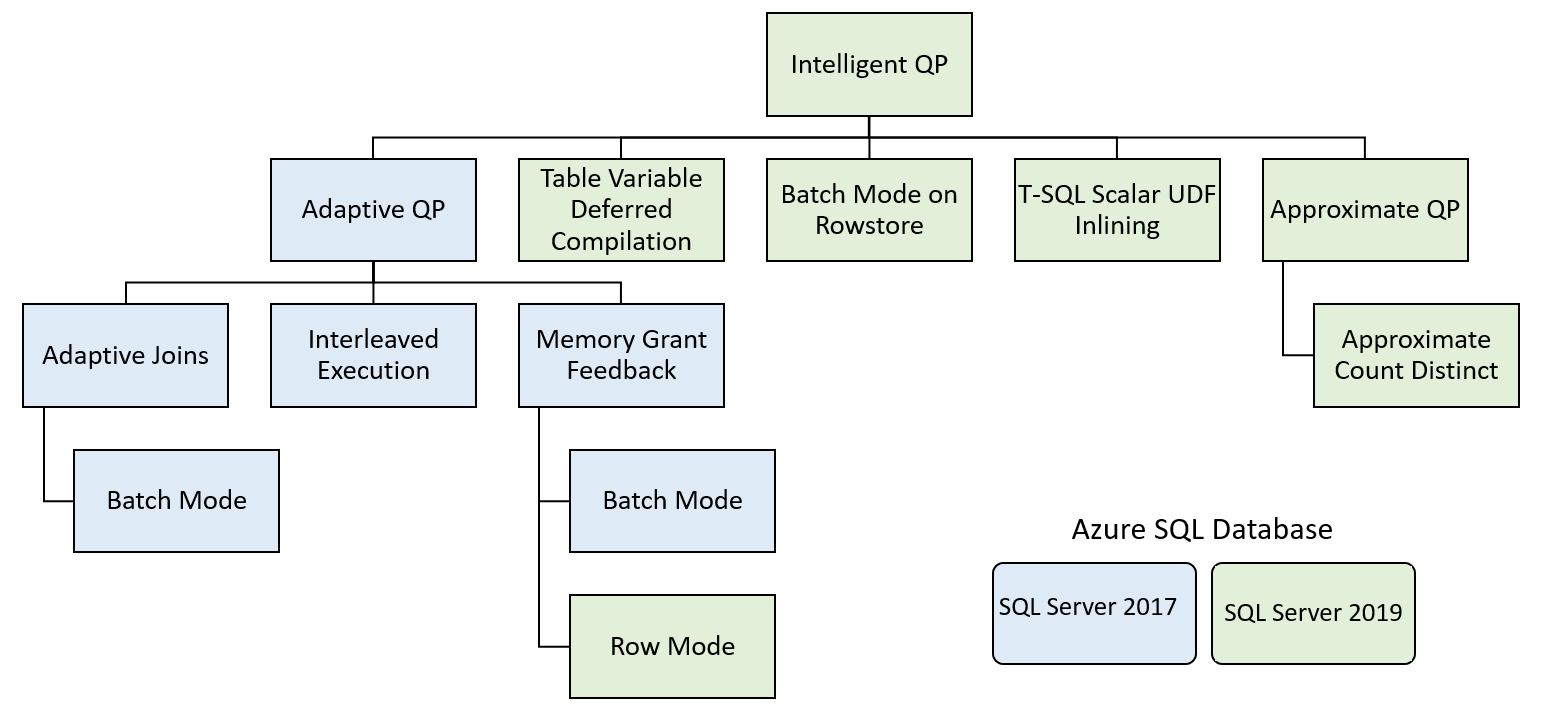
Intelligent frågebearbetning innehåller funktioner som förbättrar befintliga arbetsbelastningsprestanda med minimal implementering.
Om du vill göra arbetsbelastningar automatiskt berättigade till intelligent frågebearbetning ändrar du den tillämpliga databaskompatibilitetsnivån till 150. Till exempel:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Anpassningsbar frågebearbetning
Anpassningsbar frågebearbetning innehåller många alternativ som gör frågebearbetningen mer dynamisk, baserat på körningskontexten för en fråga. Dessa alternativ omfattar flera funktioner som förbättrar bearbetningen av frågor.
Adaptiva kopplingar – databasmotorn defers val av koppling mellan hash och kapslade loopar baserat på antalet rader som går in i kopplingen. Anpassningsbara kopplingar fungerar för närvarande endast i batchkörningsläge.
Interleaved Execution – För närvarande har den här funktionen stöd för tabellvärdesfunktioner med flera instruktioner (MSTVF). Före SQL Server 2017 använde MSTVF:er en fast raduppskattning på antingen en eller 100 rader, beroende på version SQL Server. Den här uppskattningen kan leda till suboptimala frågeplaner om funktionen returnerade många fler rader. Ett verkligt radantal genereras från MSTVF innan resten av planen kompileras med interfolierad körning.
Feedback om minnesbeviljande – SQL Server genererar ett minnesbeviljande i den första planen för frågan, baserat på uppskattningar av radantal från statistik. Allvarlig datasnedvridning kan leda till över- eller underuppskattningar av radantal, vilket kan orsaka övertilldel av minne som minskar samtidigheten eller underbidrag, vilket kan leda till att frågan spiller data till tempdb. Med feedback om minnesbeviljande identifierar SQL Server dessa villkor och minskar eller ökar mängden minne som har beviljats frågan för att antingen undvika spill eller överbeläggning.
De här funktionerna aktiveras automatiskt i kompatibilitetsläge 150 och kräver inga andra ändringar för att aktivera.
Uppskjuten kompilering av tabellvariabel
Precis som MSTVF:er har tabellvariabler i SQL Server-körningsplaner en fast radräkningsuppskattning på en rad. Precis som MSTVFs ledde den här fasta uppskattningen till dåliga prestanda när variabeln hade ett mycket större radantal än förväntat. Med SQL Server 2019 analyseras nu tabellvariabler och har ett faktiskt radantal. Uppskjuten kompilering liknar den interfolierade körningen för MSTVF:er, förutom att den utförs vid den första kompilering av frågan i stället för dynamiskt i körningsplanen.
Batchläge på radarkiv
Med batchkörningsläget kan data bearbetas i batchar i stället för rad för rad. Frågor som medför betydande CPU-kostnader för beräkningar och sammansättningar ser den största fördelen med den här bearbetningsmodellen. Genom att separera batchbearbetnings- och kolumnlagringsindex kan fler arbetsbelastningar dra nytta av bearbetning i batchläge.
Inlining av skalär användardefinierad funktion
I äldre versioner av SQL Server presterade skalärfunktioner dåligt av flera orsaker. Skalärfunktioner kördes iterativt och bearbetades effektivt en rad i taget. De hade inte rätt kostnadsuppskattning i en körningsplan och de tillät inte parallellitet i en frågeplan. Med användardefinierad funktionssammanfattning omvandlas dessa funktioner till skalära underfrågor i stället för den användardefinierade funktionsoperatorn i körningsplanen. Den här omvandlingen kan leda till betydande prestandaökningar för frågor som omfattar skalära funktionsanrop.
Ungefärligt antal distinkta
Ett vanligt frågemönster för informationslager är att köra ett distinkt antal beställningar eller användare. Det här frågemönstret kan vara dyrt mot en stor tabell. Ungefärligt antal distinkt introducerar en mycket snabbare metod för att samla in ett distinkt antal genom att gruppera rader. Den här funktionen garanterar en felfrekvens på 2 % med ett konfidensintervall på 97 %.