Skala om beräkningsresurser
En av de viktigaste fördelarna med molnet är att du kan skala om resurser i ett system på begäran. Genom att skala upp (etablera större resurser) eller skala ut (etablera fler resurser) kan du minska belastningen på ett system genom att användningsgraden minskar när kapaciteten ökar eller arbetsbelastningen fördelas bredare.
Skalning kan ge kortare svarstider (och därmed bättre prestanda ur användarens perspektiv) genom att dataflödet ökar när ett större antal förfrågningar kan hanteras. Det här kan även ge kortare svarstider under belastningstoppar, eftersom färre förfrågningar placeras i kö hos varje resurs under toppen. Dessutom kan skalning ge bättre tillförlitlighet i systemet genom att resursanvändningen hindras från att nå kritiska nivåer.
Molnet gör det enkelt att etablera nya eller bättre resurser, men det är också viktigt att tänka på hur kostnaderna förändras. Så även om det ger fördelar att skala upp eller ut är det också viktigt att inse när resurserna ska skalas ned eller in för att spara pengar.
Horisontell skalning (skala in och ut)
Horisontell skalning är en strategi där fler resurser läggs till i systemet eller när onödiga resurser tas bort från systemet. Den här typen av skalning är fördelaktig på servernivå när belastningen på systemet varierar på ett oförutsägbart sätt. Eftersom belastningen varierar är det viktigt att etablera rätt mängd resurser för att alltid kunna hantera den.
Här är några överväganden som gör det här till en svår uppgift
- starttiden för en instans (till exempel en virtuell dator)
- molntjänstleverantörens prissättningsmodell
- potentiella intäktsförluster via försämrad tjänstkvalitet (QoS) om utskalningen tar för lång tid.
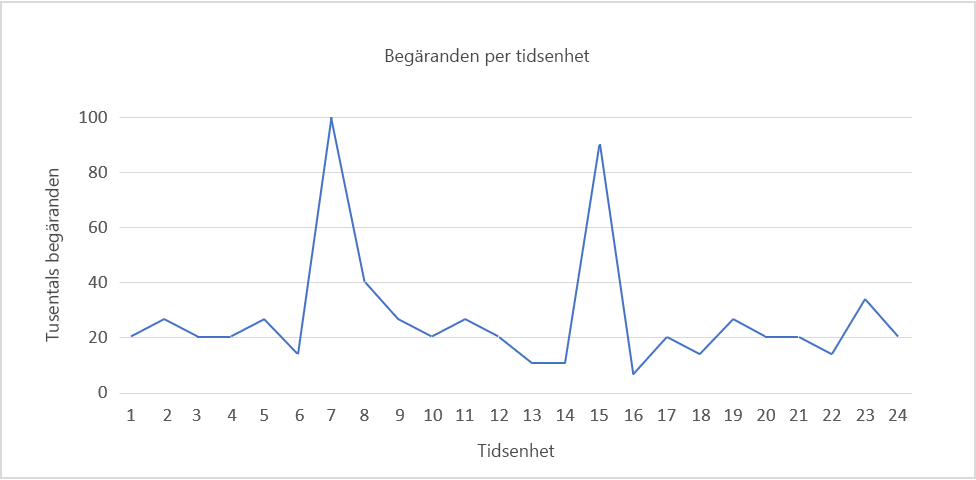
Bild 5: Exempel på belastningsmönster.
Tänk dig till exempel belastningsmönstret i bild 5 ovan.
Anta att vi använder Amazon Web Services, att varje tidsenhet motsvarar 1 faktisk timme och att en server måste kunna bearbeta 5 000 förfrågningar. Efterfrågan är som störst mellan tidsenhet 6 och 8 samt 14 och 16. Vi tar det senare intervallet som exempel. Vi kan se ett fall i efterfrågan kring tidsenhet 16 och börja minska antalet allokerade resurser. Eftersom vi går från ungefär 90 000 förfrågningar till 10 000 på 3 timmar så kan vi matematiskt sett spara in kostnaden för ett dussin eller fler ytterligare instanser som skulle ha varit online vid tiden 15.
I bild 6 ser du ett skalningsmönster som justerar antalet instanser i realtid för att matcha belastningsmönstret, där antalet instanser visas i rött. Under perioder med hög belastning skalas antalet instanser ut till 20 respektive 18 så att det finns tillräckligt med resurser för att hantera trafiken. Under andra perioder minskas antalet instanser (de skalas in) så att resursutnyttjandet hålls relativt konstant. Om vi antar att varje instans kostar 20 cent per timme så är kostnaden för att köra 20 instanser i 24 timmar 96 dollar. Genom att skala om antalet instanser enligt bilden sänker du kostnaden till cirka 42 dollar, vilket ger en besparing på över 15 000 dollar per år. Det är mycket pengar nästan oavsett vilken IT-budget du har.
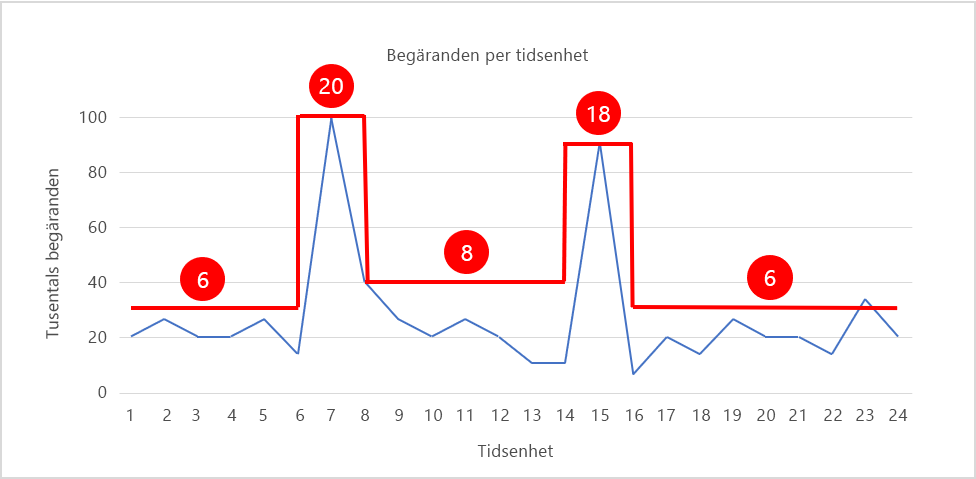
Bild 6: Skala in och ut med efterfrågan.
Skalning är beroende av trafikegenskaperna och belastningen den genererar på en webbtjänst. Om trafiken följer ett förutsägbart mönster, till exempel baserat på mänskligt beteende som när filmer strömmas från en webbtjänst på kvällen, kan skalningen vara prediktiv för att bibehålla en viss tjänstkvalitet. I många fall går det dock inte att förutsäga trafiken och skalningssystemet måste då vara reactive baserat på olika villkor.
Notera gärna att skalning in och ut kan utföras med både containerinstanser och VM-instanser. Tidigare har arbetsbelastningar i molnet generellt körts i virtuella datorer, men det blir allt vanligare att köra dem i containrar. Skalning för VM-baserade arbetsbelastningar görs genom att öka och minska antalet virtuella datorer. På samma sätt kan containerbaserade arbetsbelastningar skalas genom att variera antalet containrar. Eftersom containerinstanser kan startas snabbare än instanser av virtuella datorer är elasticiteten något större.
Vertikal skalning (skala upp och ned)
Vertikal skalning är ett sätt att uppnå elasticitet, men det är inte det enda sättet. Anta att trafiken till din webbplats sällan överskrider 15 000 förfrågningar per tidsenhet och att du etablerar en enda stor instans som kan hantera 20 000, tillräckligt för att hantera den normala trafiken ganska bra och även för att hantera mindre belastningstoppar. Om belastningen på webbplatsen växer kan du rimligen hantera trafikökningen genom att ersätta serverinstansen med en som har dubbelt så många processorkärnor och dubbelt så mycket RAM-minne. Det här kallas för att skala upp.
Den största utmaningen vid vertikal skalning är att växlingen normalt tar lite tid, och den här tiden kan ses som nedtid. Det här beror på att tjänstkvaliteten minskar när alla åtgärder flyttas från den mindre instansen till den större, även växlingen bara tar några minuter.
En annan begränsning med vertikal skalning är den minskade granulariteten. Om du har 10 serverinstanser online och behöver öka kapaciteten tillfälligt med 10 % kan du skala ut från 10 instanser till 11 och uppnå önskat resultat. Med vertikal skalning har dock den närmast större instansen vanligtvis ungefär två gånger den ursprungliga kapaciteten, vilket skulle motsvara att skala ut horisontellt från 10 instanser till 20 bara för att hantera en trafikökning på 10 %. Det här är mindre kostnadseffektivt än att skala horisontellt.
En sista sak att tänka på med vertikal skalning är tillgängligheten. Om du har en enda stor instans som hanterar alla kunder på en webbplats och den instansen kraschar så slutar också webbplatsen att fungera. Om du däremot etablerar 10 små instanser för att hantera samma belastning och en av dem kraschar så kanske användarna upplever något sämre prestanda, men de kan fortfarande använda webbplatsen. Så även om belastningen är förutsägbar och ökar stadigt när tjänsten blir mer populär så väljer många molnadministratörer att skala horisontellt i stället för vertikalt.
Skala om servernivån
Skalbarhet är ibland mer nyanserad än att helt enkelt etablera fler resurser (skala ut) eller större resurser (skala upp). På servernivå kan ökad efterfrågan öka konkurrensen om vissa typer av resurser som processor, minne och bandbredd i nätverket. Molntjänstleverantörer erbjuder normalt virtuella datorer som är optimerade för antingen beräkningsintensiva, minnesintensiva eller nätverksintensiva arbetsbelastningar. Det är lika viktigt att du kan din arbetsbelastning och väljer rätt typ av virtuell dator som att starta fler eller större virtuella datorer. Det är bättre att ha fem virtuella datorer som hanterar beräkningsintensiva arbetsbelastningar än 10, även om virtuella datorer som är optimerade för beräkningsintensiva arbetsbelastningar kostar 20 % mer än mer allmänna virtuella datorer.
Att utöka maskinvaruresurserna är inte alltid den bästa lösningen när du vill förbättra en tjänsts prestanda. Du kan även minska resurskonkurrensen och förbättra användningsgraden genom att förbättra effektiviteten i de algoritmer som tjänsten använder, och då behöver du kanske inte skala om de fysiska resurserna.
Ett viktigt övervägande när det gäller skalning är tillståndskänsligheten. En tillståndslös tjänstdesign passar bra för en skalbar arkitektur. Att en tjänst är tillståndslös innebär i princip att klientförfrågningarna innehåller all information som behövs för att bearbeta en förfrågan på servern. Servern lagrar ingen klientrelaterad information i instansen och lagrar all sessionsinformation i serverinstansen.
Med en tillståndslös tjänst blir det enklare att växla resurser på begäran, utan att det behövs någon konfiguration för att upprätthålla klientanslutningens kontext (tillstånd) för efterföljande förfrågningar. Om tjänsten är tillståndskänslig behövs det en strategi för resursskalningen så att kontexten överförs från den befintliga konfigurationen till den nya. Observera att det finns tekniker för att implementera tillståndskänsliga tjänster, som att underhålla en nätverkscache så att kontexten kan delas mellan olika servrar.
Skalning på datanivå
I dataorienterade program med ett stort antal läsningar och skrivningar till en databas eller ett lagringssystem begränsas ofta svarstiden för varje förfrågan av hårddiskens läs- och skrivtider. Större instanser ger bättre I/O-prestanda, vilket kan förbättra söktiden på hårddisken och i sin tur minska svarstiderna i tjänsten. Även om flera datainstanser på datanivån kan förbättra tillförlitligheten och tillgängligheten för programmet genom det finns bättre haveriberedskap, så kan replikering av data mellan flera instanser förbättra svarstiderna i nätverket om klienten betjänas av ett datacenter som ligger närmare rent fysiskt. Horisontell partitionering, eller partitionering av data mellan flera resurser, är en annan horisontell skalningsstrategi där data partitioneras i segment och lagras på flera dataservrar, snarare än att de replikeras mellan flera instanser.
En annan utmaning när det gäller skalning på datanivå är att upprätthålla konsekvens (en läsåtgärd är identisk på alla repliker), tillgänglighet (läsningar och skrivningar lyckas alltid) och partitionstolerans (garanterade egenskaper i systemet bibehålls när fel hindrar kommunikation mellan noderna). Det här kallas ofta för CAP-satsen, som säger att det är svårt att få alla de här egenskaperna i ett distribuerat databassystem, och att du som mest får välja två av dem1.
Referenser
- Wikipedia. CAP-sats. https://en.wikipedia.org/wiki/CAP_theorem.