Så här hanterar du avslutande svarstid
Vi har redan diskuterat flera optimeringstekniker som används i molnet för att minska svarstiden. Några av de åtgärder som vi har granskat inkluderar skalningsresurser vågrätt eller lodrätt och använder en lastbalanserare för att dirigera begäranden till närmaste tillgängliga resurser. På den här sidan fördjupar vi oss i varför det i ett stort datacenter eller molnprogram är viktigt att minimera svarstiden för alla begäranden och inte bara optimera i allmänhet. Vi kommer att undersöka hur även ett fåtal extremvärden med långa svarstider avsevärt kan försämra den observerade prestandan i ett stort system. På sidan visas också olika metoder för att skapa tjänster som ger förutsägbara svar med kort svarstid, även om de enskilda komponenterna inte garanterar detta. Detta är ett problem som är särskilt viktigt i interaktiva program där den önskade svarstiden för en interaktion är under 100 ms.
Vad är en avslutande svarstid?
De flesta molnprogram är stora distribuerade system som ofta förlitar sig på parallellisering för att minska svarstiden. En vanlig metod är att förgrena en begäran som mottagits på en rotnod (till exempel en webbserver i klientdelen) till många lövnoder (beräkningsservrar i serverdelen). Prestandaförbättringen styrs av parallelliteten i den distribuerade beräkningen och även av det faktum att man undviker höga kostnader för en dataflytt. Vi flyttar bara beräkningen till den plats där data lagras. Lövnoderna kan naturligtvis användas samtidigt i hundratals eller till och med tusentals parallella begäranden.
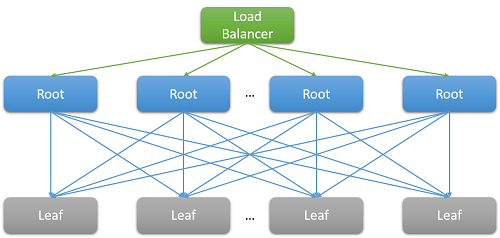
Bild 7: Svarstid på grund av utskalning
Titta på exemplet att söka efter en film på Netflix. När användaren börjar skriva i sökrutan, skapas flera parallella händelser från rotwebbservern. Dessa händelser innehåller minst följande begäranden:
- Till motorn för automatisk komplettering, för att förutsäga sökningen som görs baserat på tidigare trender och användarens profil.
- Till korrektionsmotorn, som hittar fel i den skrivna frågan baserat på en ständig anpassning av språkmodellen.
- Enskilda sökresultat för de olika komponentorden i en fråga med flera ord, som måste kombineras baserat på filmernas rangordning och relevans.
- Ytterligare efterbearbetning och filtrering av resultat för att uppfylla användarens inställningar för ”säker sökning”.
Sådana exempel är mycket vanliga. Vi vet att en enda Facebook-begäran kontaktar tusentals memcached-servrar, medan en enda Bing-sökning ofta kontaktar tiotusentals indexservrar.
Det är tydligt att behovet av skalning har lett till en stor förgrening på serversidan för varje enskild begäran som hanteras av klientdelen. För tjänster som förväntas vara ”dynamiska” för att ha kvar sin användarbas, visar heuristiken att svaren förväntas inom 100 ms. När antalet servrar som krävs för att lösa en fråga ökar, beror den övergripande tiden ofta på det sämsta svaret från en lövnod till en rotnod. Förutsatt att alla lövnoder måste slutföras innan ett resultat kan returneras, måste den övergripande svarstiden alltid vara längre än svarstiden för den långsammaste komponenten.
Precis som i de flesta stokastiska processer kan svarstiden för en enskild lövnod uttryckas som en distribution. Årtionden av erfarenhet har visat att i det allmänna fallet kommer de flesta (>99 %) förfrågningar från ett väl konfigurerat molnsystem att köras extremt snabbt. Men ofta finns det några få extremvärden i ett system som körs mycket långsamt.
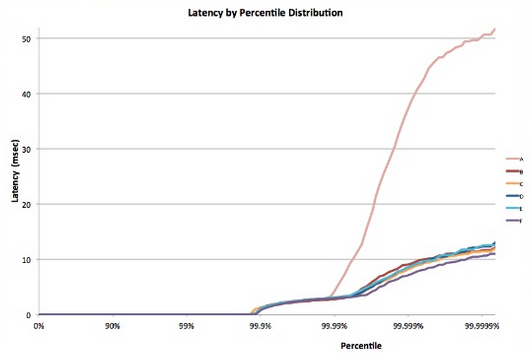
Bild 8: Exempel på svarstidför tail 5
Fundera på ett system där alla lövnoder har en genomsnittlig svarstid på 1 ms, men det finns en sannolikhet på 1 % att svarstiden är längre än 1 000 ms (en sekund). Om varje fråga hanteras av en enda lövnod, är sannolikheten att frågan tar längre tid än en sekund också 1 %. Men när vi ökar antalet noder till 100 blir sannolikheten att frågan avslutas inom en sekund 36,6 %, vilket innebär att det finns en sannolikhet på 63,4 % att frågans varaktighet bestäms av avslutet (lägst 1 %) för svarstidsfördelningen.
$(.99^{100})$
Om vi simulerar detta i olika fall ser vi att antalet servrar ökar och att effekten av en enskild långsam fråga är mer uttalad (observera att grafen nedan är monotont ökande). Eftersom sannolikheten för dessa extremvärden minskar från 1 % till 0,01 % blir systemet också betydligt långsammare.
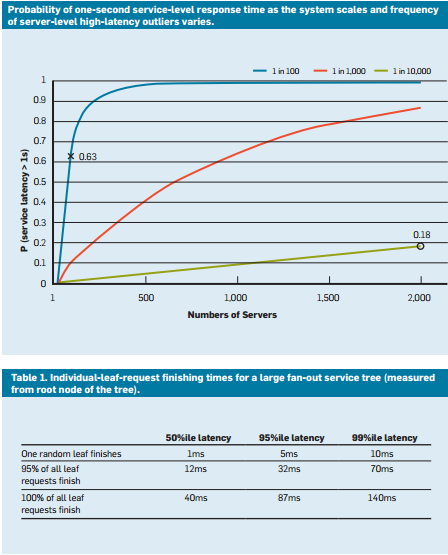
Bild 9: Nyligen genomförd studie av svarstidssannolikhet som visar den 50:e, 95:e och 99:e percentilen för svarstid för begäranden4
Precis som vi har utformat våra program för att vara feltoleranta för att hantera problem med resurstillförlitlighet bör det nu vara tydligt varför det är viktigt att program är "tail toleranta". För att kunna göra detta måste vi förstå källorna till dessa långa prestandaavvikelser och identifiera åtgärder där det är möjligt och lösningar där inte.
Variabilitet i molnet: Källor och åtgärder
För att hantera variationen i svarstider som kan leda till problemet med avslutande svarstid, måste vi förstå källorna till prestandavariation.1
- Användning av delade resurser: Många olika virtuella datorer (och program inom dessa virtuella datorer) kämpar för en delad pool med beräkningsresurser. I sällsynta fall är det möjligt att denna konkurrens leder till lång svarstid för vissa begäranden. För kritiska uppgifter kan det vara bra att använda dedikerade instanser och köra prestandamått med jämna mellanrum vid inaktivitet, för att säkerställa att det fungerar.
- Bakgrundsdaemoner och underhåll: Vi har redan talat om behovet av bakgrundsprocesser för att skapa kontrollpunkter, skapa säkerhetskopior, uppdatera loggar, samla in skräp och hantera resursrensning. Detta kan dock försämra systemets prestanda vid körning. För att åtgärda detta är det viktigt att synkronisera avbrott på grund av underhållstrådar för att minimera påverkan på trafikflödet. Detta innebär att all variation sker i ett kort, välkänt fönster i stället för slumpmässigt under programmets livslängd.
- Köning: En annan vanlig källa till variabilitet är burstiness för trafik ankomstmönster.1 Den här variabiliteten förvärras om operativsystemet använder en annan schemaläggningsalgoritm än FIFO. Linux-system schemalägger ofta trådar på ett oordnat sätt för att optimera det totala dataflödet och maximera användningen av servern. Studier har visat att med FIFO-schemaläggning i operativsystemet, minskas den avslutande svarstiden på bekostnad av att systemets totala dataflöde sänks.
- Allt-till-alla-incast: Mönstret som visas i bild 8 ovan kallas för all-to-all-kommunikation. Eftersom merparten av nätverkskommunikationen sker över TCP, leder detta till tusentals samtidiga begäranden och svar mellan klientdelens webbserver och alla bearbetningsnoder på serverdelen. Det här är ett mycket explosionsartat mönster vid kommunikation som ofta leder till en speciell typ av överbelastningsfel som kallas för TCP Incast-kollaps.12 Det intensiva plötsliga svaret från tusentals servrar leder till att många paket tas bort och skickas på nytt, vilket i slutänden medför en nätverkslavin av trafik med datapaket som är mycket små. Stora datacenter och molnprogram behöver ofta använda anpassade nätverksdrivrutiner för att dynamiskt justera TCP-mottagningsfönstret och återöverföringstimern. Routrar kan också konfigureras för att ta bort trafik som överskrider en angiven hastighet och minska storleken på sändningen.
- Energi- och temperaturhantering: Slutligen är variabilitet en biprodukt av andra tekniker för kostnadsminskning som att använda inaktiva tillstånd eller nedskalning av CPU-frekvens. En processor kan ofta ägna avsevärd tid åt att skala upp från ett inaktivt tillstånd. Att stänga av sådana kostnadsoptimeringar leder till högre strömförbrukning och kostnader, men en lägre variabilitet. Detta är inte ett så stort problem i det offentliga molnet, eftersom prissättningsmodellerna sällan bedömer interna användningsmått för kundens resurser.
Vissa experiment har funnit att variabiliteten i sådana system är mycket sämre i det offentliga molnet,3 vanligtvis på grund av en bristfällig prestandaisolering av virtuella resurser och den delade processorn. Detta förvärras om många svarstidskänsliga jobb körs på samma fysiska nod som processorintensiva jobb.
Leva med variabilitet: Tekniska lösningar
Många av variationskällorna ovan saknar en idiotsäker lösning. I stället för att försöka hantera alla källor som driver upp den avslutande svarstiden, måste molnprogrammen vara utformade att vara avslutstoleranta. Detta liknar naturligtvis hur vi utformar program till att vara feltoleranta, eftersom vi omöjligt kan tänka på att åtgärda alla eventuella fel. Några av de vanliga metoderna för att hantera variationen på är:
- "Tillräckligt bra"-resultat: Ofta, när systemet väntar på att få resultat från tusentals noder, kan vikten av ett enskilt resultat antas vara ganska låg. Därför kan många program välja att bara svara användarna med resultat som kommer inom ett visst, kort svarstidsfönster och ignorera resten.
- Kanariefåglar: Ett annat alternativ som ofta används för sällsynta kodsökvägar är att testa en begäran på en liten delmängd lövnoder för att testa om det orsakar en krasch eller ett fel som kan påverka hela systemet. Den fullständiga förgreningsfrågan genereras endast om kontrollvärdet inte orsakar något fel. Detta liknar hur man förr i världen skickade ner en kanariefågel i kolgruvan för att se om den var säker för människor.
- Svarstidsinducerad skyddstillsyn och hälsokontroller: Naturligtvis är en stor del av förfrågningarna till ett system för vanliga för att testa med hjälp av en kanariefågel. Sådana begäranden är mer sannolika att ha ett långt avslut om någon av lövnoderna presterar dåligt. För att motverka detta måste systemet regelbundet övervaka hälsotillståndet och svarstiden för varje lövnod och inte dirigera begäranden till noder som uppvisar låg prestanda (på grund av underhåll eller fel).
- Differentiell QoS: Separata tjänstklasser kan skapas för interaktiva begäranden så att de kan prioriteras i valfri kö. Svarstidsokänsliga program kan tolerera längre väntetider för sina åtgärder.
- Säkring av begäran: Det här är en enkel lösning för att minska variabilitetens inverkan genom att vidarebefordra samma begäran till flera repliker och använda svaret som kommer först. Naturligtvis kan detta dubblera eller tredubbla den mängd resurser som krävs. För att minska antalet garanterade begäranden kan man välja att endast skicka det andra begärandet om det första svaret har dröjt längre tid än den 95:e percentilen av förväntad svarstid för begäran. Detta gör att den extra belastningen bara blir cirka 5 %, men det minskar avslutande svarstid avsevärt (ett vanligt fall visas i bild 9, där svarstiden för den 95:e percentilen är mycket lägre än för den 99:e percentilen).
- Spekulativ körning och selektiv replikering: Uppgifter på noder som är särskilt upptagna kan startas spekulativt på andra underutnytttagna lövnoder. Detta är särskilt användbart om ett fel på en viss nod gör att den blir överbelastad.
- UX-baserade lösningar: Slutligen kan fördröjningen vara intelligent dold för användaren via ett väldesignat användargränssnitt som minskar den fördröjning som en mänsklig användare upplever. Metoder för att göra detta kan vara att använda animeringar, visa tidiga resultat eller engagera användaren genom att skicka relevanta meddelanden.
Med hjälp av dessa tekniker är det möjligt att avsevärt förbättra upplevelsen för slutanvändare av ett molnprogram och lösa problemet med ett långt avslut.
Referenser
- Li, J., Sharma, N. K., Ports, D. R., & Gribble, S. D. (2014). Tales of the Tail: Hardware, OS, and Application-Level Sources of Tail Latency from the Proceedings of the ACM Symposium on Cloud Computing, ACM
- Haitao Wu, Zhenqian Feng, Chuanxiong Guo och Yongguang Zhang (2013). ICTCP: Incast-överbelastningskontroll för TCP i datacenternätverk, IEEE/ACM-transaktioner på nätverk (TON), IEEE Press
- Yunjing Xu, Zachary Musgrave, Brian Noble och Michael Bailey (2013). Bobtail: Undvika långa svansar i molnet, 10:e USENIX-konferensen om design och implementering av nätverkssystem, USENIX Association
- Jeffrey Dean och Luiz André Barroso (2013). Svansen i stor skala, Kommunikation av ACM, ACM
- Gil Tene (2014). [Förstå svarstid – vissa viktiga lektioner och verktyg] (https://www.infoq.com/presentations/latency-lessons-tools/, QCon London