Skala resurser
En av de viktigaste fördelarna med molnet är att du kan skala resurser i ett system på begäran. Genom att skala upp (etablera större resurser) eller skala ut (etablera fler resurser) kan du minska belastningen på enstaka resurser genom att användningsgraden minskar när kapaciteten ökar eller arbetsbelastningen fördelas bredare.
Skalning kan hjälpa till att förbättra prestandan genom att öka dataflödet, eftersom ett stort antal begäranden nu kan hanteras. Det här kan även ge kortare svarstider under belastningstoppar, eftersom färre förfrågningar placeras i kö hos varje resurs under toppen. Dessutom kan detta hjälpa till att förbättra systemets tillförlitlighet genom att minska resursanvändningen, så att det hamnar längre bort från resursens brytpunkt.
Molnet gör det enkelt att etablera nya eller bättre resurser, men det är också viktigt att tänka på hur kostnaderna förändras. Så även om det ger fördelar att skala upp eller ut, är det också viktigt att inse när resurserna ska skalas ned eller in för att minska kostnaderna. I program på N-nivå är det också viktigt att kunna lokalisera exakt var flaskhalsarna är och vilka nivåer som ska skalas, oavsett om det är datanivån eller servernivån.
Skalningsresurser underlättas av belastningsutjämning (vi diskuterade detta tidigare), vilket hjälper till att maskera skalningsaspekten i ett system genom att dölja den bakom en konsekvent slutpunkt.
Skalningsstrategier
Horisontell skalning (skala ut och in)
Horisontell skalning är en strategi där fler resurser kan läggas till i systemet eller där onödiga resurser kan tas bort från systemet. Den här typen av skalning är fördelaktig på servernivå när belastningen på systemet varierar på ett oförutsägbart sätt. Eftersom belastningen varierar är det viktigt att på ett effektivt sätt etablera rätt mängd resurser för att alltid kunna hantera den.
Några överväganden som kan göra detta till en utmanande uppgift är starttiden för en instans, prissättningsmodellen hos molntjänstleverantören och en eventuell förlust i intäkter på grund av en försämrad tjänstkvalitet (QoS) genom att inte skala ut i tid. Vi kan till exempel titta på följande belastningsmönster:
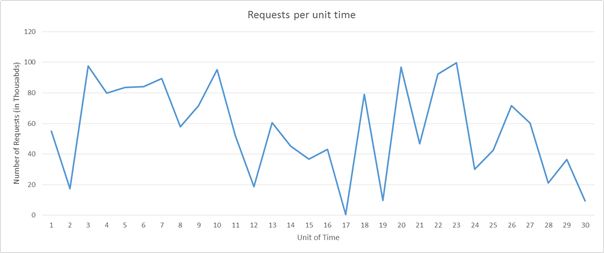
Bild 6: Exempel på mönster för inläsning av begäranden
Låt oss anta att vi använder Amazon Web Services. Vi antar att varje tidsenhet motsvarar 3 timmar och att vi måste ha en server som kan bearbeta 5 000 förfrågningar. Om du tittar på belastningen under tidsenheterna 16 till 22 finns det enorma variationer där. Vi kan se en minskad efterfrågan till höger kring tidsenhet 16 och börja minska antalet allokerade resurser. Eftersom vi går från ungefär 50 000 begäranden till nästan 0 under 3 timmar, kan vi teoretiskt sett spara kostnaden för 10 instanser som skulle ha varit uppe vid tidsenhet 16.
Nu ska vi i stället tänka oss att varje tidsenhet är lika med 20 minuter. I det här fallet kommer en sänkning av resurserna i tidsenhet 16, följt av nya resurser efter 20 minuter faktiskt öka kostnaderna i stället för att spara dem, eftersom AWS fakturerar varje beräkningsinstans per timme.
Förutom de två ovanstående övervägandena måste en tjänstleverantör också utvärdera de förluster som uppstår vid en försämrad QoS under tidsenhet 20, om den endast har kapacitet för 90 000 begäranden i stället för 100 000.
Skalningen är beroende av trafikegenskaperna och belastningen den genererar på en webbtjänst. Om trafiken följer ett förutsägbart mönster (till exempel baserat på mänskligt beteende som när filmer strömmas från en webbtjänst på kvällen), kan skalningen vara prediktiv för att bibehålla en viss tjänstkvalitet. I många fall går det dock inte att förutsäga trafiken och skalningssystemen måste då vara reaktiva baserat på olika villkor, vilket visas i exemplen ovan.
Vertikal skalning (skala upp och ned)
Det finns vissa typer av belastningar för tjänstleverantörer som är mer förutsägbara än andra. Om du till exempel vet från historiska mönster att antalet förfrågningar alltid kommer att vara 10 000–15 000, kan du anta att en server som kan hantera 20 000 begäranden är tillräcklig för tjänstleverantörens syften. Belastningarna kan öka i framtiden, men så länge de ökar på ett konsekvent sätt kan tjänsten flyttas till en större instans som kan hantera fler förfrågningar. Detta är lämpligt för små program med en låg mängd trafik.
Utmaningen vid vertikal skalning är att växlingstiden kan anses vara ett driftstopp. Det här beror på att tjänstkvaliteten minskar när alla åtgärder flyttas från den mindre instansen till den större, även om växlingen bara tar några minuter.
Dessutom erbjuder de flesta molnleverantörer beräkningsresurser med mer beräkningskraft genom att fördubbla beräkningskraften hos en resurs. Därför är kornigheten vid skalning inte lika bra som i horisontell skalning. Så även om belastningen är förutsägbar och ökar stadigt när tjänsten blir mer populär, väljer många tjänstleverantörer att skala horisontellt i stället för vertikalt.
Överväganden för skalning
Övervakning
Övervakning är ett av de viktigaste elementen för att effektivt skala resurser, eftersom du kan använda mätvärden till att tolka vilka delar av systemet som behöver skalas och när de behöver skalas. Via övervakning kan du analysera trafikmönster och resursutnyttjande så att du kan bedöma när och hur mycket du behöver skala resurserna för att maximera tjänstkvaliteten och få en vinst.
Du kan övervaka flera aspekter hos dina resurser och använda dem till att utlösa skalning. Det vanligaste måttet är resursutnyttjande. En övervakningstjänst kan till exempel spåra processoranvändningen för varje resursnod och skala om resurserna om användningen är för hög eller för låg. Om användningen för varje resurs till exempel är högre än 95 % är det förmodligen bra att lägga till fler resurser, eftersom systemet är hårt belastat. Tjänsteleverantörer fastställer vanligtvis dessa utlösare genom att analysera resursnodernas brytpunkt, när de börjar haverera, och kartlägga deras beteende vid olika belastningsnivåer. Även om det är viktigt att maximera användningsgraden för varje resurs av kostnadsskäl, bör du lämna lite utrymme så att operativsystemet kan hantera extraaktiviteter. Om användningen å andra sidan avsevärt understiger till exempel 50 %, kanske inte alla resursnoder behövs och vissa kan avetableras.
I praktiken övervakar tjänstleverantörer oftast en kombination av flera olika mått för en resursnod så att de kan utvärdera när resurser bör skalas om. Några sådana mått är processoranvändning, minnesförbrukning, dataflöde och svarstider. Azure erbjuder Azure Monitor som en extra tjänst som kan övervaka Azure-resurser och visa sådana mått.
Tillståndslöshet
En tillståndslös tjänstdesign passar bra för en skalbar arkitektur. Att en tjänst är tillståndslös innebär i princip att klientförfrågningarna innehåller all information som behövs för att bearbeta en förfrågan på servern. Servern lagrar ingen klientrelaterad information på instansen och lagrar all sessionsinformation på serverinstansen.
Med en tillståndslös tjänst blir det enklare att växla resurser på begäran, utan att det behövs någon konfiguration för att upprätthålla klientanslutningens kontext (tillstånd) för efterföljande förfrågningar. Om tjänsten är tillståndskänslig behövs det en strategi för resursskalningen så att kontexten överförs från den befintliga nodkonfigurationen till den nya. Observera att det finns tekniker för att implementera tillståndskänsliga tjänster, som att underhålla en nätverkscache med Memcached så att kontexten kan delas mellan olika servrar.
Bestämma vad som ska skalas
Beroende på tjänstens beskaffenhet måste olika resurser skalas beroende på krav. När arbetsbelastningarna ökar på servernivån kan, beroende på typ av program, resurskonkurrensen öka för antingen processor, minne, nätverksbandbredd eller alla ovanstående. Med övervakningen av trafiken kan vi identifiera vilken resurs som begränsas och korrekt skala den aktuella resursen. Molntjänstleverantörer tillhandahåller inte nödvändigtvis skalbarhetskornighet för att bara skala beräkning eller minne, men de tillhandahåller olika typer av beräkningsinstanser som specifikt hanterar beräknings- eller minnesintensiv belastning. För ett program som har minnesintensiva arbetsbelastningar skulle det exempelvis vara mer lämpligt att skala upp resurserna till minnesoptimerade instanser. För program som behöver hantera ett stort antal begäranden som inte nödvändigtvis är beräknings- eller minnesintensiva, kan det vara en bättre strategi att skala ut flera standardberäkningsinstanser.
Att utöka maskinvaruresurserna är inte alltid den bästa lösningen när du vill förbättra en tjänsts prestanda. Du kan även minska resurskonkurrensen och förbättra användningsgraden genom att förbättra effektiviteten i de algoritmer som tjänsten använder. Detta kan innebära att du inte behöver skala om de fysiska resurserna.
Skalning på datanivå
I dataorienterade program med ett stort antal läsningar och skrivningar till en databas eller ett lagringssystem, begränsas ofta svarstiden för varje förfrågan av hårddiskens läs- och skrivtider. Större instanser ger bättre I/O-prestanda för läsningar och skrivningar, vilket kan förbättra söktiden på hårddisken och i sin tur ge en stor förbättring av tjänstens svarstid. Att ha flera datainstanser på datanivån kan förbättra programmets tillförlitlighet och tillgänglighet genom att ge redundans. Att replikera data över flera instanser har ytterligare fördelar i att minska nätverkssvarstiden, om klienten hanteras av ett datacenter som ligger fysiskt närmare. Horisontell partitionering, eller partitionering av data mellan flera resurser, är en annan horisontell skalningsstrategi där data partitioneras i flera partitioner och lagras på flera dataservrar, snarare än att de replikeras mellan flera instanser.
En annan utmaning när det gäller skalning på datanivå är att upprätthålla konsekvens (en läsåtgärd är identisk på alla repliker), tillgänglighet (läsningar och skrivningar lyckas alltid) och partitionstolerans (garanterade egenskaper i systemet bibehålls när fel hindrar kommunikation mellan noderna). Det här kallas ofta för CAP-satsen, som anger att det i ett distribuerat databassystem är mycket svårt att uppnå alla tre egenskaperna. Därför kan systemet som mest visa en kombination av två av egenskaperna. Du får lära dig mer om strategier för databasskalning och CAP-satsen i senare moduler.