Skapa feltoleranta molntjänster
En stor del av datacenter- och molntjänsthanteringen innefattar att utforma och underhålla en tillförlitlig tjänst som baseras på opålitliga delar. Följande bild visar en del av en utbildning för nyanställda som bör ge en uppfattning om de stora antalen (och typerna) av problem som ofta uppstår i ett stort datacenter.

Bild 2: Tillförlitlighetsproblem som visas i en träningspresentation
Ett systemfel inträffar som ett resultat av ett ogiltigt tillstånd i systemet som har orsakats av ett fel. System utvecklar vanligtvis fel som tillhör någon av följande typer:
- Tillfälliga fel: Tillfälliga fel i systemet som korrigerar sig själva med tiden.
- Permanenta fel: Fel som inte kan återställas från och som vanligtvis kräver att resurser ersätts.
- Tillfälliga fel: Fel som inträffar regelbundet i ett system.
Fel kan påverka systemets tillgänglighet genom att tjänsterna avbryts eller prestandan för systemfunktionerna försämras. Ett feltolerant system kan utföra sin funktion även om det förekommer fel i systemet. I molnet förväntas ofta ett feltolerant system tillhandahålla tjänster på ett konsekvent sätt med färre driftstopp än serviceavtalet anger.
Varför är feltolerans viktigt?
Haverier i stora verksamhetskritiska system kan leda till betydande ekonomiska förluster för alla berörda parter. Grunden i systemen för molnbaserad databehandling är att de har en lagerarkitektur. Därför kan ett fel i ett lager av molnresurserna utlösa ett fel i andra lager ovanför, eller förhindra åtkomst till lagren nedanför.
Ett fel i en maskinvarukomponent i systemet kan till exempel påverka normal körning av ett SaaS-program (programvara som en tjänst) som körs på en virtuell dator med hjälp av felresurserna. Fel i ett system på något av lagren har en direkt koppling till serviceavtalen mellan leverantörerna på varje nivå.
Proaktiva mått
Tjänsteleverantörer vidtar flera åtgärder för att utforma systemet på ett visst sätt för att undvika kända problem eller förutsägbara fel.
Profilering och testning
Belastnings- och påfrestningstestning av molnresurser för att förstå möjliga orsaker till fel är viktiga för att säkerställa tjänsternas tillgänglighet. Med dessa mått kan man utforma ett system som klarar av den förväntade belastningen utan något oförutsägbart beteende.
Överetablering
Överetablering är en metod för att distribuera resurser i volymer som är större än den allmänna planerade användningen av resurserna vid en specifik tidpunkt. I situationer där de exakta behoven i systemet inte går att förutsäga, kan en överbelastning av resurserna vara en acceptabel strategi för att hantera oväntade toppar i belastningen.
Fundera som ett exempel på en näthandelsplattform som har en genomsnittlig konsekvent belastning på sina servrar året runt, men där man förväntar sig att belastningsmönstret ökar drastiskt inför julen. Vid topparna är det lämpligt att etablera extra resurser baserat på historiska data för användningen. En snabb ökning av trafiken är vanligtvis svår att hantera under en kort tidsperiod. Som beskrivs i senare avsnitt finns en tidskostnad för dynamisk skalning, vilket innebär tidskrävande steg för att upptäcka en ändring i belastningsmönstret och för att etablera extra resurser för den nya belastningen. Båda stegen kräver tid. Tidsfördröjningen för justeringen kan vara tillräckligt stor för att skapa en överbelastning av (och i värsta fall krascha) systemet eller åtminstone försämra tjänstkvaliteten.
Överetablering är också en taktik som används för att skydda mot överbelastningsattacker (DoS eller DDoS), vilket är när angripare genererar förfrågningar som har utformats för att överbelasta ett system med stora trafikvolymer. Vid alla angrepp tar det alltid lite tid för systemet att identifiera och vidta lämpliga åtgärder. Samtidigt som en sådan analys av begärandemönster görs, är systemet redan utsatt för ett angrepp och behöver kunna hantera den ökade trafiken tills en strategi för riskreducering kan implementeras.
Replikering
Kritiska systemkomponenter kan dupliceras med hjälp av ytterligare maskin- och programvarukomponenter som i bakgrunden hanterar problem i delar av systemet utan att hela systemet utsätts för ett driftstopp. Replikeringen har två grundläggande strategier:
- Aktiv replikering, där alla replikerade resurser är igång samtidigt och svarar på samt bearbetar alla begäranden. Det innebär att alla resurser får samma begäran för alla klienter, alla resurser svarar på samma begäran och ordningen på begärandena behålls över alla resurser.
- Passiv replikering, där endast den primära enheten bearbetar begäranden och sekundära enheter bara upprätthåller tillståndet och tar över om den primära enheten misslyckas. Klienten är bara i kontakt med den primära resursen, som sänder tillståndsändringen till alla sekundära resurser. Nackdelen med passiv replikering är att det kan uppstå antingen borttagna begäranden eller försämrad tjänstkvalitet i växlingen från den primära till den sekundära instansen.
Det finns också en hybridstrategi som kallas halvaktiv, vilket liknar den aktiva strategin. Skillnaden är att bara den primära resursens utdata exponeras för klienten. Utdata från de sekundära resurserna ignoreras och loggas, och kan användas om ett fel uppstår i den primära resursen. Följande bild visar skillnaderna mellan strategierna för replikering.
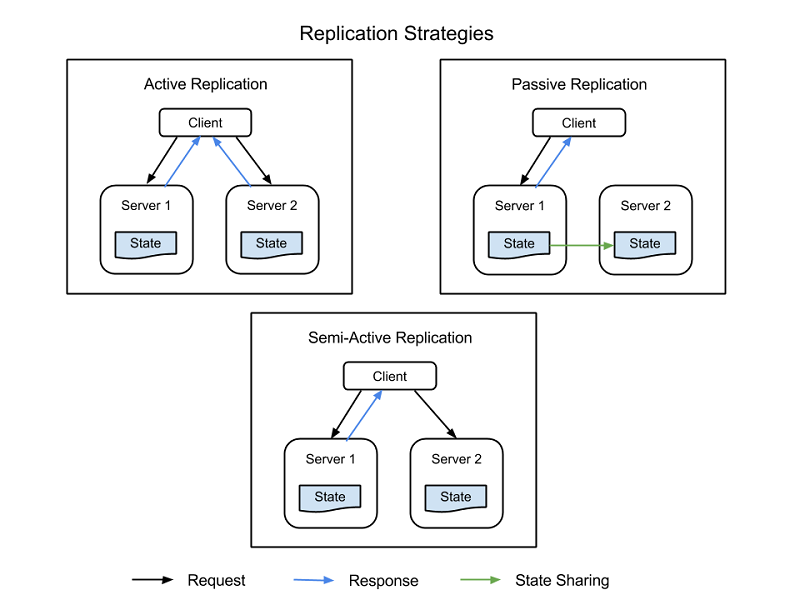
Bild 3: Replikeringsstrategier
En viktig faktor att överväga vid replikering är antalet sekundära resurser som ska användas. Även om detta skiljer sig från program till program baserat på systemets allvarlighetsgrad, finns det 3 formella nivåer för replikeringen:
- N+1: Detta innebär i princip att för ett program som behöver N-noder för att fungera korrekt etableras en extra resurs som ett felsäkert.
- 2N: På den här nivån etableras en extra nod för varje nod som krävs för normal funktion som en felsäker.
- 2N+1: På den här nivån etableras en extra nod för varje nod som krävs för normal funktion och en ytterligare nod överlag som ett felsäkert.
Reaktiva åtgärder
Förutom förebyggande åtgärder kan systemen vidta reaktiva åtgärder och hantera problem om och när de inträffar:
Kontroller och övervakning
Alla resurser övervakas ständigt i syfte att kontrollera om det finns oförutsägbara beteenden eller förlust av resurser. Utifrån övervakningsinformationen utformas återställnings- eller omkonfigurationsstrategier som startar om resurser eller startar nya resurser. Övervakningen kan hjälpa till att identifiera fel i systemen. Fel som gör att en tjänst inte är tillgänglig kallas kraschfel och de som medför ett oregelbundet eller felaktigt beteende i systemet kallas för bysantinska fel.
Det finns flera övervakningsmetoder som används för att kontrollera kraschfel i ett system. Två av dessa taktiker är:
- Ping-echo: Övervakningstjänsten ber varje resurs om dess tillstånd och får ett tidsfönster för att svara.
- Pulsslag: Varje instans skickar status till övervakningstjänsten med jämna mellanrum, utan någon utlösare.
Övervakningen av bysantinska fel beror vanligtvis på egenskaperna för den tjänst som tillhandahålls. Övervakningssystem kan kontrollera grundläggande mått som svarstid, processoranvändning och minnesförbrukning, samt jämföra med de förväntade värdena om tjänstkvaliteten har försämrats. Dessutom lagras programspecifika övervakningsloggar vanligtvis vid varje viktig tjänstkörningspunkt och analyseras regelbundet för att se att tjänsten fungerar korrekt (eller om det finns inmatade fel i systemet).
Kontrollpunkt och omstart
Flera programmeringsmodeller i molnet använder kontrollpunktsstrategier, där tillstånd sparas i flera körningssteg för att man ska kunna återställa till den senaste sparade kontrollpunkten. I dataanalysprogram finns det ofta tidskrävande parallella distribuerade uppgifter som körs i datauppsättningar på flera terabyte för att extrahera information. Eftersom dessa uppgifter körs i flera små körningssegment, kan varje steg i körningen av programmet spara det övergripande körningstillståndet som en kontrollpunkt. Om fel uppstår och enskilda noder inte kan slutföra sitt arbete, kan körningen startas om från föregående kontrollpunkt. Den största utmaningen vid identifiering av giltiga kontrollpunkter att återställa till, är när parallella processer delar information. Ett fel i en av processerna kan orsaka en sammanhängande återställning i en annan process, eftersom kontrollpunkterna i processen kan bero på ett fel i de data som har delats av den felaktiga processen. Du lär dig mer om feltolerans för programmeringsmodeller i senare moduler.
Fallstudier för återhämtningstestning
Molntjänster måste skapas med redundans och feltolerans i åtanke, eftersom ingen enskild komponent i ett stort distribuerat system kan garantera 100 % tillgänglighet eller drifttid.
Alla fel (inklusive beroendefel i samma nod, rack, datacenter eller regionalt redundanta distributioner) måste hanteras utan att hela systemet påverkas. Att testa systemets förmåga att hantera oåterkalleliga fel är viktigt, eftersom även några sekunders driftstopp eller tjänstförsämring kan orsaka en förlust på hundratusentals, och kanske t.o.m. miljontals, kronor.
Feltestning med verklig trafik måste utföras regelbundet så att systemet skärps och kan hantera ett oplanerat avbrott. Det finns olika system som är skapade för att testa återhämtning. Ett sådant testpaket är Simian Army som har skapats av Netflix.
Simian Army består av tjänster (kallas apor) i molnet som skapar olika typer av fel, upptäcker onormala villkor och testar systemets förmåga att klara av dem. Målet är att hålla molnet säkert, skyddat och med hög tillgänglighet. Några av de apor som finns i Simian Army är:
- Chaos Monkey: Ett verktyg som slumpmässigt väljer en produktionsinstans och inaktiverar den för att se till att molnet överlever vanliga typer av fel utan någon kundpåverkan. Netflix beskriver Chaos Monkey som "Tanken på att släppa lös en vild apa med ett vapen i ditt datacenter (eller molnregion) för att slumpmässigt skjuta ner instanser och tugga genom kablar - samtidigt som vi fortsätter att betjäna våra kunder utan avbrott." Den här typen av testning med detaljerad övervakning kan exponera olika former av svagheter i systemet, och automatiska återställningsstrategier kan byggas baserat på resultaten.
- Svarstidsapa: En tjänst som orsakar fördröjningar mellan RESTful-kommunikation mellan olika klienter och servrar, vilket simulerar tjänstförsämring och stilleståndstid.
- Doctor monkey: En tjänst som hittar instanser som uppvisar feltillstånd (till exempel CPU-belastning) och tar bort dem från tjänsten. Det ger tjänstägarna lite tid att ta reda på orsaken till problemet och kanske avsluta instansen.
- Chaos Gorilla: En tjänst som kan simulera förlusten av en hel AWS-tillgänglighetszon. Den används för att testa att tjänsterna automatiskt ombalanserar funktionerna i kvarvarande zoner utan att användaren märker det eller behöver vidta några manuella åtgärder.