Klassificera dina data
Det kan finnas olika typer av data i en onlinebutik. Varje typ av data kan dra nytta av en annan lagringslösning.
Programdata kan klassificeras på ett av följande tre sätt: strukturerade, halvstrukturerade och ostrukturerade. Här får du lära dig hur du klassificerar dina data så att du kan välja lämplig lagringslösning för typen av data.
Metoder för att lagra data i molnet
I följande video presenteras dina alternativ för att lagra data i molnet:
Strukturerade data
I strukturerade data, som ibland kallas relationsdata, har alla data samma fält eller egenskaper. Alla data har samma organisation och form eller schema. Det delade schemat gör att den här typen av data enkelt kan sökas igenom med hjälp av frågespråk som Structured Query Language (SQL). Den här funktionen gör den här datastilen perfekt för program som CRM-system, reservationer och lagerhantering.
Strukturerade data lagras ofta i databastabeller med rader och kolumner. I tabellen anger en nyckelkolumn hur en rad i en tabell relaterar till data i en annan rad i en annan tabell. I följande bild hämtar en tabell med data om betyg data från en tabell med elevnamn och en tabell med klassdata med hjälp av nyckelkolumner.
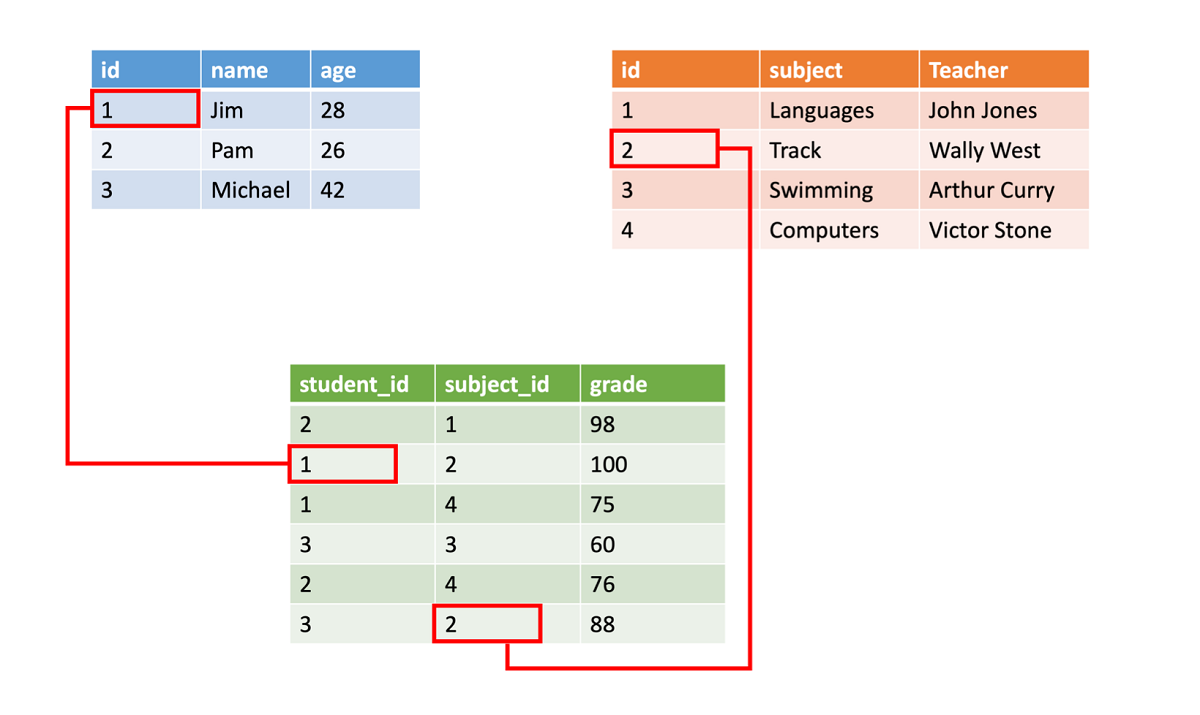
Det är enkelt att använda strukturerade data eftersom de är enkla att ange, köra frågor mot och analysera. Alla data har samma format. Men att tvinga fram en konsekvent struktur innebär också att datautvecklingen är svårare. Om du lägger till eller tar bort datafält måste du uppdatera varje post så att den överensstämmer med den nya strukturen.
Halvstrukturerade data
Halvstrukturerade data är mindre ordnade än strukturerade data. Halvstrukturerade data lagras inte i relationsformat eftersom fälten inte passar bra i tabeller, rader och kolumner. Halvstrukturerade data innehåller taggar som gör att du kan organisera och ordna data hierarkiskt. Ett exempel är nyckel/värde-par. Halvstrukturerade data kallas även för icke-relationella eller inte bara SQL-data (NoSQL).
Ett dataserialiseringsspråk definierar halvstrukturerade data. I dataklassificering är serialisering processen att konvertera data till ett format som kan överföras eller lagras.
Programvaruutvecklare använder dataserialiseringsspråk för att skriva data som lagras i minnet till en fil, som sedan kan skickas till ett annat system, parsas och läsas. Avsändaren och mottagaren behöver inte känna till information om det andra systemet. Båda systemen kan förstå data om de använder samma serialiseringsspråk.
Vanliga serialiseringsspråk
Tre vanliga serialiseringsspråk är XML, JSON och YAML.
XML
Utökningsbart Markup Language (XML) var ett av de första dataspråken som användes i stor utsträckning. XML är textbaserat, vilket gör det enkelt att läsa av människor och maskinläsbart. XML-parsare är tillgängliga för nästan alla populära utvecklingsplattformar.
Du kan använda XML för att uttrycka relationer. XML har standarder för schema, transformering och till och med visning på webben.
Här är ett exempel på en persons namn, ålder och hobbyer som uttrycks i XML:
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML uttrycker formen på data med hjälp av taggar som definieras inuti vinkelparenteser. Taggarna finns i två former: element som <FirstName> och attribut som kan uttryckas i text som Age="23". Element kan ha underordnade element för att uttrycka relationer. Taggen <Hobbies> uttrycker till exempel en samling Hobby element.
XML är flexibelt och kan enkelt uttrycka komplexa data. Det tenderar dock att vara mer utförligt, vilket gör det större att lagra, bearbeta och skicka över ett nätverk. Därför har andra format blivit mer populära.
JSON
JavaScript Object Notation (JSON) har en enkel specifikation och använder klammerparenteser för att ange datastruktur. Jämfört med XML är JSON mindre utförligt och det är lättare för människor att läsa. JSON används ofta av webbtjänster för att returnera data.
Här är samma persons namn, ålder och hobbyer som uttrycks i JSON:
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
JSON-formatet är inte lika formellt som XML. Den är närmare en nyckel/värde-parmodell än ett formellt datauttryck. Som du kan gissa från namnet har Programmeringsspråket JavaScript inbyggt stöd för det här formatet, så det är populärt för webbutveckling. Precis som XML har andra språk parsers som du kan använda när du arbetar med det här dataformatet. Nackdelen med JSON är att det tenderar att vara mer programmerorienterat, så det är svårare för icke-tekniska personer att läsa och ändra.
YAML
YAML Ain't Markup Language (YAML) är ett nyligen utvecklat dataserialiseringsspråk. En av fördelarna med att använda YAML är att det är lättare för människor att läsa än vissa andra språk. Radseparation och indrag definierar datastrukturen. YAML-formatet minskar beroendet av strukturella tecken som parenteser, kommatecken och hakparenteser.
Här är samma data som uttrycks i YAML:
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
Det här formatet är mer läsbart än JSON. Konfigurationsfiler som personer skriver men program parsa är en vanlig användning för det. YAML är det senaste av dessa dataformat.
Det används ofta för konfigurationsfiler skrivna av personer men tolkas av program.
Vad är halvstrukturerade data eller NoSQL-data?
I följande video beskrivs alternativ för halvstrukturerade data och NoSQL-datalagring:
Ostrukturerade data
Organisationen av ostrukturerade data är odefinierad. Ostrukturerade data levereras ofta i filformat, till exempel i foto- eller videofiler. Själva videofilen kan ha en övergripande struktur och levereras med halvstrukturerade metadata, men de data som utgör själva videon är ostrukturerade. Därför klassificeras foton, videor och andra liknande filer som ostrukturerade data.
Här är några exempel på ostrukturerade data:
- Mediefiler, till exempel foton, videor och ljudfiler.
- Microsoft 365-filer, till exempel Word-dokument.
- Textfiler.
- Loggfiler.
Dataklassificering: Utvärdera dina datatyper
Du kan klassificera data på något av tre sätt: strukturerade, halvstrukturerade och ostrukturerade. Att förstå skillnaderna så att du kan klassificera dina data hjälper dig att välja rätt lagringslösning.
Strukturerade data är ordnade data som passar bra i tabeller eller datakolumner. Halvstrukturerade data visserligen organiserade och har tydliga egenskaper och värden, men det kan finnas skillnader mellan datapunkterna. Ostrukturerade data passar inte snyggt i tabeller eller kolumner, och de har inget enhetligt schema.
Nu ska vi titta på de datauppsättningar som används i en onlinebutik och klassificera dem.
Data i produktkatalogen
Produktkatalogdata för en onlinebutik är delvis strukturerade. Varje produkt har en produkt-SKU, en beskrivning, en kvantitet, ett pris, storleksalternativ, färgalternativ, ett foto och eventuellt en video. Dessa data verkar relationella till att börja med eftersom alla har samma struktur. Men när du introducerar nya produkter eller olika typer av produkter kanske du vill lägga till datafält. Till exempel är nya tennisskor som du bär Bluetooth-aktiverade för att vidarebefordra sensordata från skon till en fitnessapp på användarens telefon. Den här funktionen verkar vara en växande trend och du vill ge kunderna möjlighet att filtrera på "Bluetooth-aktiverade" skor. Du vill inte uppdatera alla befintliga skodata med en Bluetooth-aktiverad egenskap. Du vill bara lägga till den här nya egenskapen i nya skor.
Med tillägget av den Bluetooth-aktiverade egenskapen är dina skodata inte längre homogena. Du har infört skillnader i schemat. Om den här ändringen är det enda undantag som du förväntar dig att stöta på kan du normalisera befintliga data så att alla produkter innehåller ett "Bluetooth-aktiverat" fält för att upprätthålla en strukturerad relationsorganisation. Men om det bara är ett av många specialfält som du tänker dig att stödja i framtiden är klassificeringen av data halvstrukturerad. Taggar organiserar data, men varje produkt i katalogen kan innehålla unika fält.
Klassificeringen för produktkatalogdata är halvstrukturerad.
Foton och videor
Foton och videor som visas på produktsidor är ostrukturerade data. Även om mediefilen kan innehålla metadata är mediefilens brödtext ostrukturerad.
Dataklassificeringen för foton och videor är ostrukturerad.
Affärsdata
Affärsanalytiker vill använda business intelligence till att utvärdera lagerflöden och granska säljdata. För att utföra dessa åtgärder måste data från flera månader aggregeras och sedan frågas. På grund av behovet av att aggregera liknande data måste dessa data vara strukturerade, så att en månad kan jämföras med nästa.
Klassificeringen för affärsdata är strukturerad.