Övning – Skapa en programhälsomodell
Contoso Shoes behöver ett sätt att identifiera, diagnostisera och förutsäga problem i den här arkitekturen. Du vill skapa en hälsomodell som kan mätas genom en hälsostatus som tillämpas på användar- och systemflöden. Målet är att identifiera potentiella felpunkter innan de kan orsaka ett avbrott.
Aktuellt tillstånd och problem
Hittills har du lagt till ett API för hälsokontroll och skapat funktioner för flera regioner i din arkitektur. Det finns dock inget sätt att få insikt i den komplexa topologi som innehåller användar- och systemflöden. Det här tomrummet måste fyllas i så att SRE-teamet snabbt kan identifiera och lösa problem.
I en incident nyligen kunde teamet inte se den sammanhängande effekten av ett problem som beror på en API-komponent som påverkar dess plattformsberoenden. Det gick mycket tid att felsöka eftersom komponenten med feltillstånd inte kunde upptäckas direkt. I slutändan ledde denna ineffektivitet till längre stilleståndstider, vilket orsakade ekonomisk förlust för företaget.
Specifikation
Utforma en hälsomodell som visar relationen mellan alla komponenter i arkitekturen, inklusive programkomponenterna och plattformsberoendena. Räkna in objekt som finns i begärandeflödet, inklusive gateway, beräkning, databaser, lagring, cacheminnen och så vidare. Inkludera även komponenter som vanligtvis finns utanför begärandeflödet. Till exempel OCI-artefakter (Open Container Initiative), hemliga arkiv, konfigurationstjänster och andra. Alla Azure-tjänster måste konfigureras för att skicka diagnostikdata.
Lägg till en enhetlig datamottagare i arkitekturen för insamling av data från olika källor.
Definiera en övergripande hälsostatus baserat på aggregerade historiska loggar och mått. Representera statusen i något av tre hälsotillstånd: inte felfri, degraderad och felfri.
Visualisera hälsostatusen för alla komponenter i en hierarki som representerar alla flöden.
Rekommenderad metod
För att komma igång med din design rekommenderar vi att du följer dessa steg:
Viktigt!
Hälsomodellering är en omfattande övning. Metoden i det här avsnittet är avsedd att hjälpa dig att komma igång. Var omfattande när det gäller att tillämpa modellen på alla funktionella och icke-funktionella flöden i din verksamhetskritiska design för att få en helhetssyn på systemet.
1 – Starta hälsomodellering
Den här övningen är teoretisk. Hälsomodellering i en designaktivitet uppifrån och ned där du behöver en omfattande lista över komponenter som används i arkitekturen. Den här listan bör innehålla alla programkomponenter och Azure-tjänsterna.
Placera komponenterna i ett beroendediagram som visar en hierarkisk vy över lösningen. Det översta lagret har användarflöden som spårar begäran från slutanvändaren till webbplatsen och flödar på program-API-nivå. Det nedre lagret innehåller systemflödena från Azure-tjänsterna. Mappa även beroenden mellan Azure-resurserna.
Diagrammet bör se ut ungefär så här:
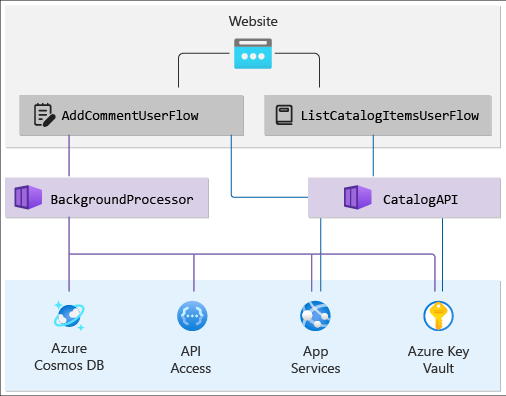
Kontrollera förloppet: Hälsotillstånd för lagerbaserade program
2 – Definiera hälsopoängen
Samla in mått och måtttrösklar för varje komponent och bestäm sedan det värde som komponenten ska betraktas som felfri, degraderad och inte felfri. Det beslutet bör påverkas av förväntade prestanda och icke-funktionella affärskrav. Kategorisera dina mått som:
Programmått: Datapunkter från programkod, till exempel antalet undantag.
Tjänstmått: Datapunkter från Azure-tjänster, till exempel databastransaktionsenheter (DTU:er) som används.
Lösningsmått: Datapunkter på lösningsnivå, till exempel bearbetningstid från slutpunkt till slutpunkt för en begäran.
Här är ett exempel för Azure App Services:
| App Services | Hälsostatus |
|---|---|
| Svarstid < 200 ms HTTP Server-fel < 2 |

|
| Svarstid < 500 ms HTTP Server-fel < 2 |

|
| Svarstid > 500 ms HTTP Server-fel > 2 |

|
3 – Definiera en övergripande hälsostatus
Definiera en övergripande status för varje användare och systemflöde. Du måste aggregera hälsostatusen för enskilda komponenter som deltar i flödet.
Anta att ett systemflöde består av en programkomponent, Azure App Service-plan och App Services.
| API | App Service-plan | App Services | Hälsostatus |
|---|---|---|---|
| Maximal svarstid < på 30 ms | CPU % < 70 % HTTP-kölängd < 5 |
Svarstid < 200 ms HTTP Server-fel < 2 |
|
| Maximal svarstid < på 30 ms | CPU % < 90 % HTTP-kölängd < 5 |
Svarstid < 500 ms HTTP Server-fel < 2 |
|
| Maximal svarstid > på 30 ms | CPU % > 90 % HTTP-kölängd > 5 |
Svarstid > 500 ms HTTP Server-fel > 2 |
|
Hälsopoängen för ett användarflöde bör representeras av den lägsta poängen för alla mappade komponenter. För systemflöden använder du lämpliga vikter baserat på affärskritiskhet. Mellan de två flödena bör ekonomiskt betydande eller kundinriktade användarflöden prioriteras.
Kontrollera förloppet: Exempel – Hälsomodell i lager
4 – Samla in övervakningsdata
Du behöver en enhetlig datamottagare i varje region som samlar in loggar och mått för alla program- och plattformstjänster som distribueras som en del av den regionala stämpeln. Du behöver en annan mottagare för att lagra mått som genereras från globala resurser, till exempel Azure Front Door och Cosmos DB.
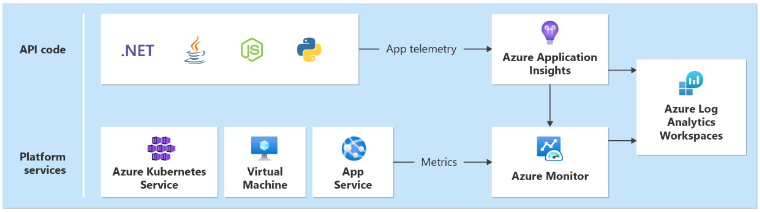
Teknikval
- Azure Application Insights: Används för att samla in all programtelemetri.
- Azure Monitor-loggar: Samlar in data som skickas av Application Insights och plattformsmått för Azure-tjänster.
- Azure Log Analytics: Används som det centrala verktyget för att analysera loggar och mått från alla program- och infrastrukturkomponenter.
Kontrollera förloppet: Enhetlig datamottagare för korrelerad analys
5 – Konfigurera frågor för övervakning av data
Kusto-frågespråk (KQL) är väl integrerat med Log Analytics. Implementera anpassade KQL-frågor som funktioner för att hämta data från Azure Monitor.
Lagra anpassade frågor på kodlagringsplatsen så att de importeras och tillämpas automatiskt som en del av dina CI/CD-pipelines (Continuous Integration/Continuous Delivery).
6 – Visualisera hälsostatusen
Du kan visualisera beroendediagrammet med hälsopoäng med en trafikljusrepresentation. Använd verktyg som Azure-instrumentpaneler, Övervaka arbetsböcker eller Grafana. Här är ett exempel:
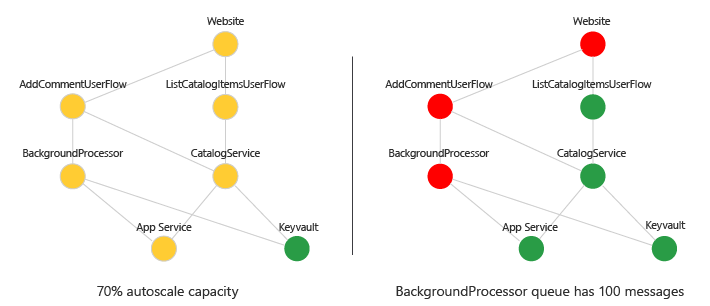
Kontrollera förloppet: Visualisering
7 – Konfigurera aviseringar om statusändringar
Du bör använda instrumentpaneler med aviseringar för att åtgärda problem omedelbart.
Om hälsotillståndet för en komponent ändras till Degraderad eller Inte felfri bör operatorn omedelbart meddelas. Ställ in aviseringar på rotnoden eftersom alla ändringar i den här noden indikerar feltillstånd i de underliggande användarflödena eller resurserna.
Kontrollera förloppet: Aviseringar
Kontrollera ditt arbete
Titta på den här demonstrationen om övervakning och hälsomodellering. Tog du upp alla aspekter i din design?
- Har du en enhetlig datamottagare för korrelerad analys?
- Har du inkluderat programloggar, plattformsmått och lösningsdatapunkter?
- Har du konfigurerat instrumentpaneler för att visualisera hälsostatusen för alla komponenter?
- Övervägde du felpunkter för varje tjänst (eller en del av den tjänsten) som kan orsaka ett avbrott eller hindra dig från att skala, distribuera, övervaka?
- Har du funderat på frågepaket för att samla in viktiga frågor som skulle hjälpa dig att sortera problem snabbare?
- Var api:et för hälsokontroll användbart i den här modellen? Behövde du ändra API:et för att bättre passa hälsomodellen?