Förstå Textanalys
Innan vi utforskar textanalysfunktionerna i Azure AI Language-tjänsten ska vi undersöka några allmänna principer och vanliga tekniker som används för att utföra textanalyser och andra nlp-uppgifter (natural language processing).
Några av de tidigaste teknikerna som används för att analysera text med datorer omfattar statistisk analys av en texttext (en corpus) för att härleda någon form av semantisk betydelse. Enkelt uttryckt, om du kan fastställa de vanligaste orden i ett visst dokument kan du ofta få en bra uppfattning om vad dokumentet handlar om.
Tokenisering
Det första steget i att analysera en corpus är att dela upp den i token. För enkelhetens skull kan du tänka på varje distinkt ord i träningstexten som en token, men i verkligheten kan token genereras för partiella ord eller kombinationer av ord och skiljetecken.
Tänk till exempel på den här frasen från ett berömt amerikanskt presidenttal: "vi väljer att gå till månen". Frasen kan delas upp i följande token, med numeriska identifierare:
- Vi
- Välja
- to
- go
- Det
- Månen
Observera att "till" (tokennummer 3) används två gånger i corpus. Frasen "vi väljer att gå till månen" kan representeras av token [1,2,3,4,3,5,6].
Kommentar
Vi har använt ett enkelt exempel där token identifieras för varje distinkt ord i texten. Tänk dock på följande begrepp som kan gälla för tokenisering beroende på vilken typ av NLP-problem du försöker lösa:
- Textnormalisering: Innan du genererar token kan du välja att normalisera texten genom att ta bort skiljetecken och ändra alla ord till gemener. För analys som enbart bygger på ordfrekvens förbättrar den här metoden övergripande prestanda. En viss semantisk betydelse kan dock gå förlorad - till exempel överväga meningen "Mr Banks har arbetat i många banker.". Ni kanske vill att er analys ska skilja mellan den person som Banks och de banker där han har arbetat. Du kanske också vill betrakta "banker"som en separat token till "banker" eftersom inkluderingen av en period ger den information som ordet kommer i slutet av en mening
- Stoppa ordborttagning. Stoppord är ord som ska undantas från analysen. Till exempel gör "the", "a" eller "it" text lättare för personer att läsa men lägger till lite semantisk betydelse. Genom att utesluta dessa ord kan en textanalyslösning vara bättre på att identifiera de viktiga orden.
- n-gram är flertermsfraser som "jag har" eller "han gick". En ordfras är ett unigram, en tvåordsfras är ett bi-gram, en treordsfras är ett tri-gram och så vidare. Genom att betrakta ord som grupper kan en maskininlärningsmodell göra texten bättre.
- Härstamning är en teknik där algoritmer används för att konsolidera ord innan de räknas, så att ord med samma rot, som "power", "powered" och "powerful", tolkas som samma token.
Frekvensanalys
När du har tokeniserat orden kan du utföra en analys för att räkna antalet förekomster av varje token. De vanligaste orden (förutom stoppord som "a", "the" och så vidare) kan ofta ge en ledtråd om huvudämnet i en text corpus. De vanligaste orden i hela texten i talet "go to the moon" som vi övervägde tidigare är till exempel "new", "go", "space" och "moon". Om vi skulle tokenisera texten som bi-gram (ordpar) är det vanligaste bi-gram i talet "månen". Utifrån denna information kan vi enkelt anta att texten främst handlar om rymdresor och att gå till månen.
Dricks
Enkel frekvensanalys där du helt enkelt räknar antalet förekomster av varje token kan vara ett effektivt sätt att analysera ett enskilt dokument, men när du behöver skilja mellan flera dokument inom samma corpus behöver du ett sätt att avgöra vilka token som är mest relevanta i varje dokument. Termfrekvens – inverterad dokumentfrekvens (TF-IDF) är en vanlig teknik där en poäng beräknas baserat på hur ofta ett ord eller en term visas i ett dokument jämfört med dess mer allmänna frekvens i hela dokumentsamlingen. Med den här tekniken antas en hög grad av relevans för ord som ofta förekommer i ett visst dokument, men relativt sällan i en mängd andra dokument.
Maskininlärning för textklassificering
En annan användbar textanalysteknik är att använda en klassificeringsalgoritm, till exempel logistisk regression, för att träna en maskininlärningsmodell som klassificerar text baserat på en känd uppsättning kategoriseringar. En vanlig tillämpning av den här tekniken är att träna en modell som klassificerar text som positiv eller negativ för att utföra attitydanalys eller åsiktsutvinning.
Tänk dig till exempel följande restaurangrecensioner, som redan är märkta som 0 (negativa) eller 1 (positiva):
- Maten och servicen var båda bra: 1
- En riktigt hemsk upplevelse: 0
- Mmm! god mat och en rolig atmosfär1:
- Långsam service och undermålig mat: 0
Med tillräckligt med etiketterade recensioner kan du träna en klassificeringsmodell med den tokeniserade texten som funktioner och sentimentet (0 eller 1) en etikett. Modellen kapslar in en relation mellan token och sentiment – till exempel recensioner med token för ord som "bra", "välsmakande" eller "kul" är mer benägna att returnera en attityd på 1 (positiv), medan recensioner med ord som "fruktansvärd", "långsam" och "undermålig" är mer benägna att returnera 0 (negativ).
Semantiska språkmodeller
Eftersom den senaste tekniken för NLP har avancerat har möjligheten att träna modeller som kapslar in det semantiska förhållandet mellan token lett till framväxten av kraftfulla språkmodeller. Kärnan i dessa modeller är kodningen av språktoken som vektorer (flervärdesmatriser med tal) som kallas inbäddningar.
Det kan vara användbart att tänka på elementen i en tokenbäddningsvektor som koordinater i flerdimensionellt utrymme, så att varje token upptar en specifik "plats". De närmare token är till varandra längs en viss dimension, desto mer semantiskt relaterade är de. Med andra ord grupperas relaterade ord närmare varandra. Som ett enkelt exempel antar vi att inbäddningarna för våra token består av vektorer med tre element, till exempel:
- 4 ("hund"): [10.3.2]
- 5 ("bark"): [10,2,2]
- 8 ("katt"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("skateboard"): [3,3,1]
Vi kan rita upp platsen för token baserat på dessa vektorer i tredimensionellt utrymme, så här:
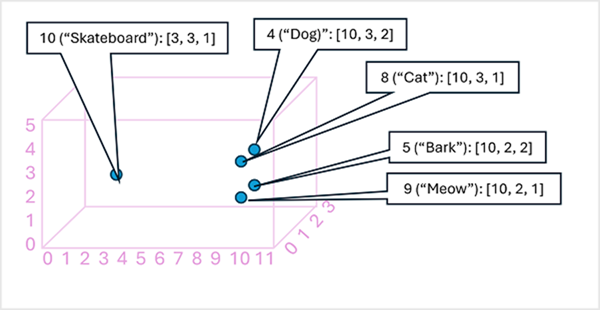
Platserna för token i inbäddningsutrymmet innehåller viss information om hur nära token är relaterade till varandra. Till exempel är token för "hund" nära "katt" och även "bark". Tokens för "katt" och "bark" är nära "mjau". Token för "skateboard" är längre bort från de andra tokens.
De språkmodeller som vi använder i branschen baseras på dessa principer men har större komplexitet. Till exempel har de vektorer som används i allmänhet många fler dimensioner. Det finns också flera sätt att beräkna lämpliga inbäddningar för en viss uppsättning token. Olika metoder resulterar i olika förutsägelser från bearbetningsmodeller för naturligt språk.
En generaliserad vy över de flesta moderna lösningar för bearbetning av naturligt språk visas i följande diagram. En stor mängd råtext tokeniseras och används för att träna språkmodeller, som kan stödja många olika typer av bearbetningsuppgift för naturligt språk.
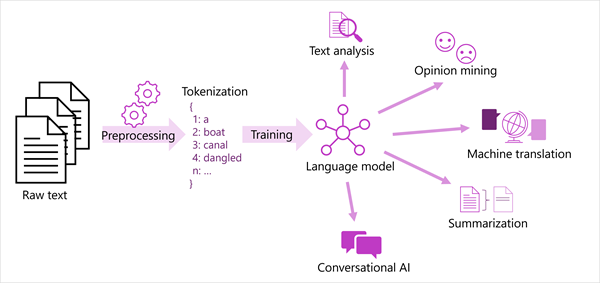
Vanliga NLP-uppgifter som stöds av språkmodeller är:
- Textanalys, till exempel att extrahera nyckeltermer eller identifiera namngivna entiteter i text.
- Attitydanalys och åsiktsutvinning för att kategorisera text som positiv eller negativ.
- Maskinöversättning, där text automatiskt översätts från ett språk till ett annat.
- Sammanfattning, där huvudpunkterna i en stor texttext sammanfattas.
- Konversations-AI-lösningar som robotar eller digitala assistenter där språkmodellen kan tolka indata från naturligt språk och returnera ett lämpligt svar.
Dessa funktioner och mer stöds av modellerna i Azure AI Language-tjänsten, som vi kommer att utforska härnäst.