Övning – Skapa och träna ett neuralt nätverk
I den här enheten använder du Keras för att skapa och träna ett neuralt nätverk som analyserar text baserat på attityd. För att kunna träna ett neuralt nätverk behöver du ha data att träna det med. I stället för att ladda ned en extern datamängd använder du datamängden IMDB movie reviews sentiment classification (Attitydklassificering med filmrecensioner från IMDB), som ingår i Keras. IMDB-datamängden innehåller 50 000 filmrecensioner som poängsatts enskilt som positiv (1) eller negativ (0). Datamängden är uppdelad i 25 000 recensioner för träning och 25 000 recensioner för testning. Attityd som uttrycks i de här recensionerna utgör grunden för det neurala nätverkets analys av text och poängsättning baserat på attityd.
IMDB-datamängden är en av flera användbara datamängder som ingår i Keras. En fullständig lista över inbyggda datamängder finns på https://keras.io/datasets/.
Skriv eller klistra in följande kod i notebook-filens första cell och klicka på knappen Kör (eller tryck på Skift + Retur) för att köra den, och lägg till en ny cell under den:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)Den här koden läser in den IMDB-datamängd som ingår Keras och skapar en ordboksmappning av orden i alla 50 000 recensioner till heltal som anger ordens relativa förekomstfrekvenser. Varje ord tilldelas ett unikt heltal. Det vanligaste ordet tilldelas siffran 1, det näst vanligaste ordet tilldelas siffran 2 och så vidare.
load_datareturnerar även ett par med tupplar som innehåller filmrecensionerna (i det här exempletx_trainochx_test) samt 1:or och 0:or som klassificerar de recensionerna som positiva respektive negativa (y_trainochy_test).Kontrollera att du ser meddelandet ”Using TensorFlow backend” (Använder TensorFlow-serverdel), som anger att Keras använder TensorFlow som serverdel.
Läsa in IMDB-datamängden
Om du vill att Keras ska använda Microsoft Cognitive Toolkit, även kallat CNTK, som serverdel kan du göra det genom att lägga till några rader med kod i början av notebook-filen. Ett exempel finns på sidan om CNTK och Keras i Azure Notebooks.
Vad exakt läste funktionen
load_datain? Variabeln med namnetx_trainär en lista över 25 000 listor som var och en representerar en filmrecension. (x_testär också en lista över 25 000 listor som representerar 25 000 recensioner.x_trainkommer att användas för träning, medanx_testkommer att användas för testning.) Men de inre listorna – de som representerar filmrecensioner – innehåller inte ord; de innehåller heltal. Så här beskrivs det i dokumentationen för Keras:
Anledningen att de inre listorna innehåller siffror i stället för text är att neurala nätverk inte tränas med text, utan med siffror. Närmare bestämt tränas de med tensorer. I det här fallet är varje recension en 1-dimensionell tensor (betrakta den som en 1-dimensionell matris) som innehåller heltal som identifierar orden i recensionen. Demonstrera det här genom att skriva in följande Python-instruktion i en tom cell och köra den. Då visas heltal som representerar den första recensionen i utbildningsdatamängden:
x_train[0]
Heltal som representerar den första recensionen i IMDB-datamängden
Den första siffran i listan är 1, och den representerar inte något ord. Den indikerar början på recensionen och är samma för alla recensioner i datamängden. Även siffrorna 0 och 2 är reserverade, och du subtraherar 3 från de andra siffrorna för att mappa ett heltal i en recension till motsvarande heltal i ordboken. Den andra siffran är 14 och refererar till det ord som motsvarar siffran 11 i ordboken, den tredje siffran motsvarar det ord som tilldelats siffran 19 i ordboken och så vidare.
Vill du veta hur ordboken ser ut? Kör följande instruktion i en ny cell i notebook-filen:
imdb.get_word_index()Endast en delmängd av ordboksposterna visas, men totalt innehåller ordboken fler än 88 000 ord och heltal som motsvarar dem. De utdata som visas matchar förmodligen inte utdata på skärmbilden eftersom ordboken genereras på nytt varje gång
load_dataanropas.
Ordboksmappning av ord till heltal
Som det framgår kodas varje recension i datamängden som en samling med heltal i stället för ord. Går det att omvänt koda en recension så att du kan se den originaltext som recensionen bestod av? Ange följande instruktioner i en ny cell och kör dem för att visa den första recensionen i
x_traini textformat:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))I utdata markerar ">" början av granskningen, medan "?" markerar ord som inte är bland de vanligaste 10 000 orden i datauppsättningen. De här ”okända” orden representeras av 2:or i listan över heltal som representerar en recension. Minns du parametern
num_words, som du skickade tillload_data? Det här är den kommer till pass. Den minskar inte storleken på ordlistan, utan begränsar det intervall med heltal som används för att koda recensionerna.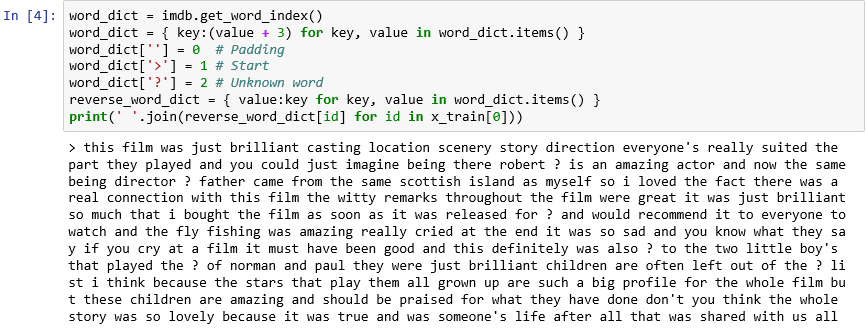
Den första recensionen i textformat
Recensionerna är ”rena” i den mening att bokstäver har konverterats till gemener och skiljetecken har tagits bort. De är dock inte redo att träna ett neuralt nätverk för analys av text baserat på attityd. När du tränar ett neuralt nätverk med en samling tensorer måste varje tensor ha samma längd. För närvarande har de listor som representerar recensioner i
x_trainochx_testolika längder.Som tur är har Keras en funktion som tar en lista med listor som indata och konverterar de inre listorna till en angiven längd genom att trunkera dem vid behov eller fylla ut dem med 0:or. Ange följande kod i notebook-filen och kör den för att framtvinga en längd på högst 500 heltal för alla listor som representerar filmrecensioner i
x_trainochx_test:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)Nu när data för träning och testning är förberedda är det dags att bygga modellen! Kör följande kod i notebook-filen för att skapa ett neuralt nätverk som utför attitydanalys:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())Bekräfta att utdata ser ut så här:
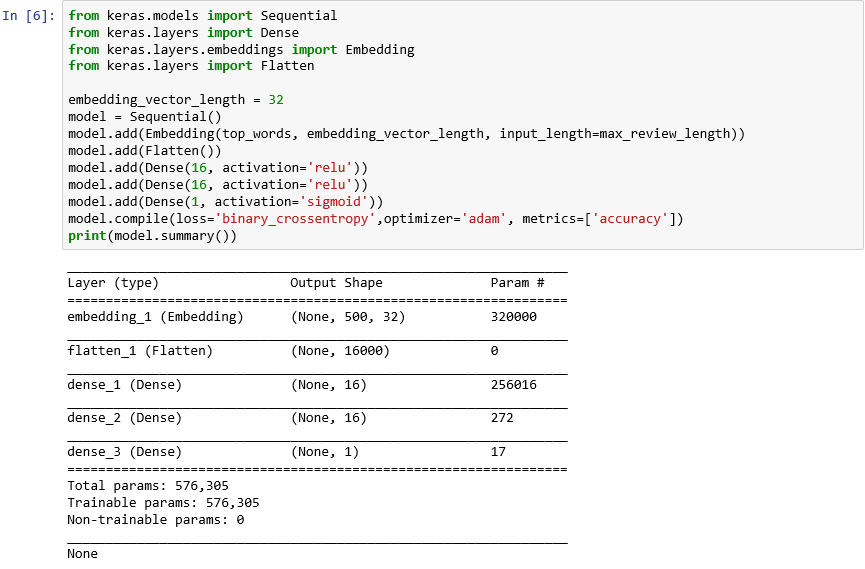
Skapa ett neuralt nätverk med Keras
Den här koden är grunden i hur du skapar ett neuralt nätverk med Keras. Först instansierar den ett
Sequential-objekt som representerar en ”sekventiell” modell – en modell som består av en slutpunkt till slutpunkt-stack med lager där utdata från ett lager ger indata till nästa.Följande instruktioner lägger till lager i modellen. Först kommer ett inbäddningslager som är avgörande för neurala nätverk som bearbetar ord. Inbäddningslagret mappar i princip matriser med många dimensioner som innehåller ordindex med heltal till flyttalsmatriser som innehåller färre dimensioner. Det gör även att ord med liknande innebörd kan behandlas på samma sätt. En fullständig genomgång av ordinbäddningar ligger utanför syftet med den här övningen, men du kan lära dig mer genom att läsa Why You Need to Start Using Embedding Layers (Därför bör du börja använda inbäddningslager). Om du föredrar en mer akademisk förklaring kan du läsa Efficient Estimation of Word Representations in Vector Space (Effektiv uppskattning av ordrepresentationer i vektorutrymme). Anropet till Flatten (Platta ut) efter tillägget av inbäddningslagret omformar utdata för indata till nästa lager.
Följande tre lager som lagts till i modellen är kompakta lager, som även kallas fullständigt anslutna lager. Det här är de traditionella lager som är vanliga i neurala nätverk. Varje lager innehåller n noder eller neuroner, och varje neuron tar emot indata från varje neuron i föregående lager, därav termen "helt ansluten". Det är dessa lager som gör det möjligt för ett neuralt nätverk att "lära sig" från indata genom att iterativt gissa utdata, kontrollera resultaten och finjustera anslutningarna för att ge bättre resultat. De två första kompakta lagren i det här nätverket innehåller 16 neuron vardera. Det här antalet valdes godtyckligt – du kan kanske förbättra modellens precision genom att experimentera med olika storlekar. Det sista kompakta lagret innehåller bara ett neuron eftersom slutmålet med nätverket är att förutsäga en typ av utdata – en attitydpoäng mellan 0,0 och 1,0.
Resultatet är det neurala nätverk som visas på bilden nedan. Nätverket innehåller ett indatalager, ett utdatalager samt två dolda lager (de kompakta lagren, som innehåller 16 neuron vardera). Som jämförelse har en del av dagens mer sofistikerade neurala nätverk fler än 100 lager. Ett exempel är ResNet-152 från Microsoft Research, vars precision för att identifiera objekt på fotografier ibland överträffar människans förmåga. Du skulle kunna skapa ResNet-152 med Keras, men du skulle då behöva ett kluster med GPU-utrustade datorer för att träna det från grunden.
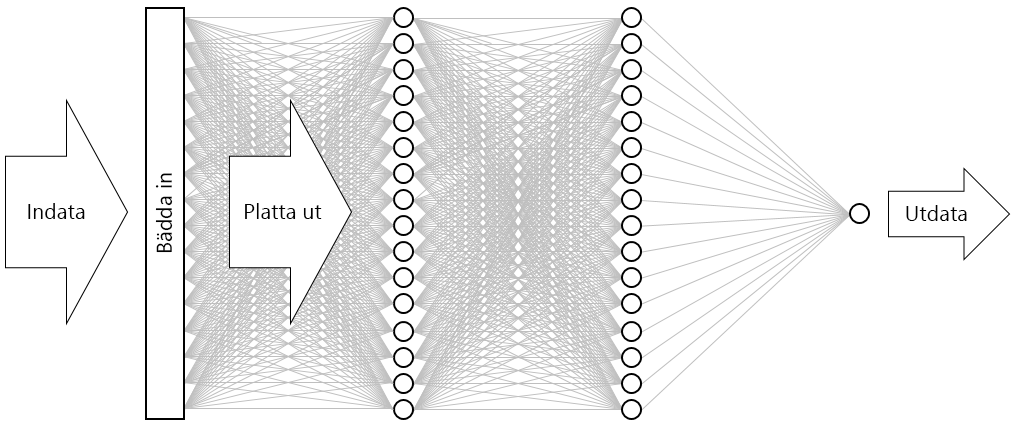
Visualisera det neurala nätverket
Anropet till funktionen compile ”kompilerar” modellen genom att ange viktiga parametrar, till exempel vilken optimerare och vilka mått som ska användas för att bedöma modellens precision i varje träningssteg. Träningen börjar inte förrän du anropar modellens
fit-funktion, så anropet tillcompilekörs vanligen snabbt.Anropa nu funktionen fit för att träna det neurala nätverket:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)Träningen bör ta ungefär 6 minuter eller lite mer än 1 minut per epok.
epochs=5instruerar Keras att göra 5 körningar framåt och bakåt genom modellen. För varje körning lär sig modellen från träningsdata och mäter (”validerar”) hur bra den har lärt sig med hjälp av testdata. Därefter gör den justeringar och går tillbaka för nästa körning eller epok. Detta återges i utdata från funktionenfit, som visar träningsprecision (acc) och valideringsprecision (val_acc) för varje epok.batch_size=128instruerar Keras att använda 128 träningsexempel åt gången för att träna nätverket. Större batchstorlekar gör träningstiden kortare (färre körningar krävs i varje epok för att förbruka alla träningsdata), men mindre batchstorlekar ökar ibland precisionen. När du har slutfört den här övningen kan det vara bra att gå tillbaka och träna modellen med en batchstorlek på 32 för att se om och i så fall hur det påverkar modellens precision. Det gör att träningstiden blir ungefär dubbelt så lång.
Träna modellen
Den här modellen är ovanlig eftersom den lär sig bra med bara några få epoker. Träningsprecisionen zoomar snabbt till nära 100 %, medan valideringsprecisionen ökar för en epok eller två och sedan planar ut. Du vill vanligtvis inte träna en modell längre än vad som krävs för att dessa noggrannheter ska stabiliseras. Risken är överanpassning, vilket innebär att modellen presterar bra mot testdata men inte lika bra med verkliga data. En indikation på att en modell överanpassas är en växande avvikelse mellan träningsprecisionen och valideringsprecisionen. En bra introduktion till överanpassning finns i Overfitting in Machine Learning: What It Is and How to Prevent It (Överanpassning i Machine Learning: What It Is and How to Prevent It).
För att visualisera ändringarna i tränings- och valideringsprecision allt eftersom träningen pågår kör du följande instruktioner i en ny cell i notebook-filen:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()Precisionsdata kommer från det
history-objekt som returneras av modellensfit-funktion. Skulle du, baserat på det diagram som visas, rekommendera att öka antalet träningsepoker, minska det eller låta det vara som det är?Ett annat sätt att kontrollera om det förekommer överanpassning är att jämföra träningsförlust med valideringsförlust allt eftersom träningen pågår. Optimeringsproblem som det här försöker att minimera en förlustfunktion. Mer information finns här. För en given epok kan en träningsförlust som vida överstiger valideringsförlusten utgöra tecken på överanpassning. I föregående steg använde du egenskaperna
accochval_accförhistory-objektets egenskaphistoryför att plotta tränings- och valideringsprecision. Samma egenskapen innehåller även värden med namnenlossochval_losssom representerar tränings- respektive valideringsförlust. Hur skulle du ändra ovanstående kod om du ville plotta de här värdena för att framställa ett diagram likt det som visas nedan?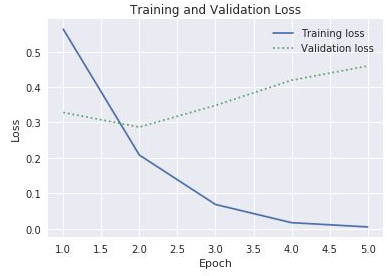
Tränings- och valideringsförlust
Med tanke på att klyftan mellan tränings- och valideringsförlust börjar öka i den tredje epoken, vad skulle du säga om någon föreslog att du ökar antalet epoker till 10 eller 20?
Avsluta med att anropa modellens
evaluate-metod för att bestämma hur precist modellen kan kvantifiera den attityd som uttrycks i text baserat på testdata ix_test(recensioner) ochy_test(0:or och 1:or, eller ”etiketter”, som anger vilka recensioner som är positiva och vilka som är negativa):scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))Vad är den beräknade precisionen i din modell?
Du uppnådde förmodligen en precision på omkring 85–90 %. Det är acceptabelt med tanke på att du skapade modellen från början (i stället för att använda ett förhandstränat neuralt nätverk) och att träningstiden var kort även utan en GPU. Den är möjligt att uppnå en precision på 95 % eller högre med alternativa arkitekturer för neurala nätverk, särskilt återkommande neurala nätverk (RNN, Recurrent Neural Network) som använder LSTM-lager (Long Short-Term Memory). Keras gör det enkelt att skapa sådana nätverk, men träningstiden kan öka exponentiellt. Den modell som du har skapat har en rimlig balans mellan precision och träningstid. Men om du vill veta mer om att skapa RNN med Keras kan du läsa Understanding LSTM and its Quick Implementation in Keras for Sentiment Analysis (Förstå LSTM och dess snabba implementering i Keras för attitydanalys).