Maskininlärning för visuellt innehåll
Möjligheten att använda filter för att tillämpa effekter på bilder är användbar i bildbearbetningsuppgifter, till exempel du kan utföra med bildredigeringsprogram. Målet med visuellt innehåll är dock ofta att extrahera betydelse, eller åtminstone användbara insikter, från bilder; som kräver att maskininlärningsmodeller skapas som tränas att identifiera funktioner baserat på stora mängder befintliga bilder.
Dricks
Den här lektionen förutsätter att du är bekant med de grundläggande principerna för maskininlärning och att du har konceptuell kunskap om djupinlärning med neurala nätverk. Om du är nybörjare på maskininlärning kan du överväga att slutföra modulen Grunderna för maskininlärning på Microsoft Learn.
Convolutional neurala nätverk (CNN)
En av de vanligaste maskininlärningsmodellarkitekturerna för visuellt innehåll är ett convolutional neuralt nätverk (CNN), en typ av djupinlärningsarkitektur. CNN använder filter för att extrahera numeriska funktionskartor från bilder och matar sedan in funktionsvärdena i en djupinlärningsmodell för att generera en etikettförutsägelse. I ett bildklassificeringsscenario representerar etiketten till exempel bildens huvudämne (med andra ord vad är det här en bild av?). Du kan träna en CNN-modell med bilder av olika typer av frukt (till exempel äpple, banan och apelsin) så att etiketten som förutsägs är typen av frukt i en viss bild.
Under träningsprocessen för en CNN definieras filterkärnor ursprungligen med hjälp av slumpmässigt genererade viktvärden. När träningsprocessen fortskrider utvärderas sedan modellernas förutsägelser mot kända etikettvärden och filtervikterna justeras för att förbättra noggrannheten. Så småningom använder den tränade klassificeringsmodellen för fruktbilder de filtervikter som bäst extraherar funktioner som hjälper till att identifiera olika typer av frukt.
Följande diagram visar hur en CNN för en bildklassificeringsmodell fungerar:
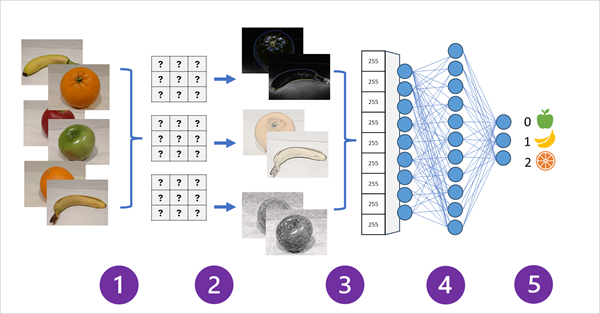
- Bilder med kända etiketter (till exempel 0: äpple, 1: banan eller 2: orange) matas in i nätverket för att träna modellen.
- Ett eller flera filterlager används för att extrahera funktioner från varje bild när de matas via nätverket. Filterkärnorna börjar med slumpmässigt tilldelade vikter och genererar matriser med numeriska värden som kallas funktionskartor.
- Funktionskartarna plattas ut till en endimensionell matris med funktionsvärden.
- Funktionsvärdena matas in i ett fullständigt anslutet neuralt nätverk.
- Utdataskiktet i det neurala nätverket använder en softmax - eller liknande funktion för att skapa ett resultat som innehåller ett sannolikhetsvärde för varje möjlig klass, till exempel [0.2, 0.5, 0.3].
Under träningen jämförs sannolikheterna för utdata med den faktiska klassetiketten – till exempel ska en bild av en banan (klass 1) ha värdet [0,0, 1,0, 0,0]. Skillnaden mellan de förutsagda och faktiska klasspoängen används för att beräkna förlusten i modellen, och vikterna i det fullständigt anslutna neurala nätverket och filterkärnorna i funktionsextraheringsskikten ändras för att minska förlusten.
Träningsprocessen upprepas över flera epoker tills en optimal uppsättning vikter har lärts. Sedan sparas vikterna och modellen kan användas för att förutsäga etiketter för nya bilder som etiketten är okänd för.
Kommentar
CNN-arkitekturer innehåller vanligtvis flera convolutional filterlager och ytterligare lager för att minska storleken på funktionskartor, begränsa de extraherade värdena och på annat sätt ändra funktionsvärdena. Dessa lager har utelämnats i det här förenklade exemplet för att fokusera på nyckelbegreppet, vilket är att filter används för att extrahera numeriska funktioner från bilder, som sedan används i ett neuralt nätverk för att förutsäga bildetiketter.
Transformatorer och multimodala modeller
CNN har varit kärnan i lösningar för visuellt innehåll i många år. De används ofta för att lösa problem med bildklassificering enligt beskrivningen tidigare, men de är också grunden för mer komplexa modeller för visuellt innehåll. Objektidentifieringsmodeller kombinerar till exempel CNN-funktionsextraheringslager med identifiering av regioner av intresse för bilder för att hitta flera objektklasser i samma bild.
Omvandlare
De flesta framsteg inom visuellt innehåll under årtiondena har drivits av förbättringar i CNN-baserade modeller. Men i ett annat AI-område – bearbetning av naturligt språk (NLP), har en annan typ av neural nätverksarkitektur, kallad transformerare, möjliggjort utveckling av avancerade språkmodeller. Transformatorer fungerar genom att bearbeta stora mängder data och koda språktoken (som representerar enskilda ord eller fraser) som vektorbaserade inbäddningar (matriser med numeriska värden). Du kan tänka dig en inbäddning som representerar en uppsättning dimensioner som var och en representerar ett semantiskt attribut för token. Inbäddningarna skapas så att token som ofta används i samma kontext är närmare varandra dimensionellt än orelaterade ord.
Som ett enkelt exempel visar följande diagram några ord kodade som tredimensionella vektorer och ritade i ett 3D-blanksteg:
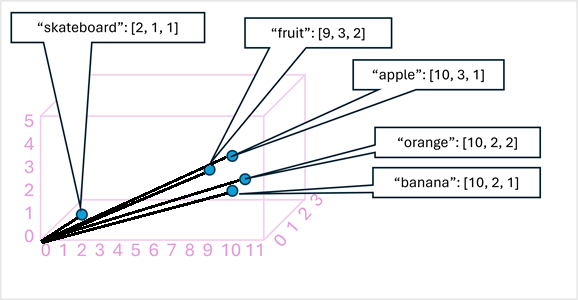
Token som är semantiskt lika kodas i liknande positioner och skapar en semantisk språkmodell som gör det möjligt att skapa avancerade NLP-lösningar för textanalys, översättning, språkgenerering och andra uppgifter.
Kommentar
Vi har bara använt tre dimensioner eftersom det är enkelt att visualisera. I verkligheten skapar kodare i transformatornätverk vektorer med många fler dimensioner, vilket definierar komplexa semantiska relationer mellan token baserat på linjära algebraiska beräkningar. Matematiken är komplex, liksom arkitekturen i en transformeringsmodell. Vårt mål här är bara att ge en konceptuell förståelse för hur kodning skapar en modell som kapslar in relationer mellan entiteter.
Multimodala modeller
Transformatorernas framgång som ett sätt att skapa språkmodeller har fått AI-forskare att överväga om samma metod skulle vara effektiv för bilddata. Resultatet är utvecklingen av multimodala modeller, där modellen tränas med hjälp av en stor mängd bildtextade bilder, utan fasta etiketter. En bildkodare extraherar funktioner från bilder baserat på pixelvärden och kombinerar dem med textinbäddningar som skapats av en språkkodare. Den övergripande modellen kapslar in relationer mellan inbäddningar av token för naturligt språk och bildfunktioner, som du ser här:
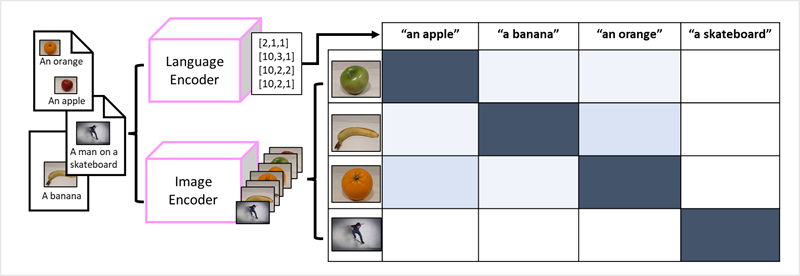
Microsoft Florence-modellen är bara en sådan modell. Den tränas med stora mängder textade bilder från Internet och innehåller både en språkkodare och en bildkodare. Florens är ett exempel på en grundmodell . Med andra ord en förtränad allmän modell där du kan skapa flera anpassningsbara modeller för specialistuppgifter. Du kan till exempel använda Florens som grundmodell för anpassningsbara modeller som utför:
- Bildklassificering: Identifiera vilken kategori en bild tillhör.
- Objektidentifiering: Hitta enskilda objekt i en bild.
- Bildtext: Generera lämpliga beskrivningar av bilder.
- Taggning: Kompilera en lista över relevanta texttaggar för en bild.
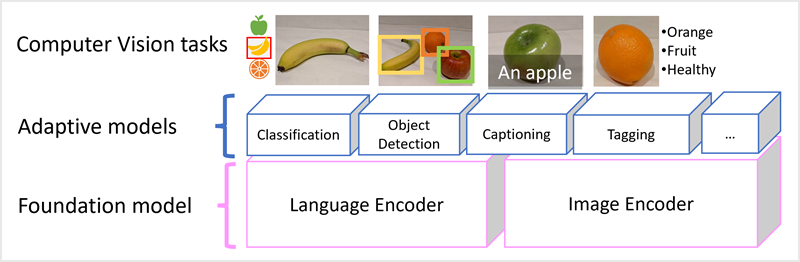
Multimodala modeller som Florens ligger i framkant när det gäller visuellt innehåll och AI i allmänhet och förväntas driva framsteg i de typer av lösningar som AI möjliggör.