Konfigurera flera noder och aktivera skalning till noll med hjälp av AKS
Med Azure Kubernetes Service kan du skapa olika nodpooler för att matcha specifika arbetsbelastningar med noderna som körs i varje nodpool. Med processen för att matcha arbetsbelastningar med noder kan du planera för att beräkna förbrukning och optimera kostnaden.
Ditt företags lösning för drönarspårning distribueras på Azure Kubernetes Service (AKS) som många containerbaserade applikationer och tjänster. Ditt team har utvecklat en ny tjänst för förutsägelsemodellering som bearbetar flygvägsinformation under extrema väderförhållanden och skapar optimala flygvägar. Den här tjänsten kräver stöd för GPU-baserad virtuell dator (VM) och körs endast på specifika dagar under veckan.
Du vill konfigurera en klusternodpool som är dedikerad för bearbetning av flygvägsinformation. Processen körs bara ett par timmar om dagen och du vill använda en GPU-baserad nodpool. Du vill dock bara betala för noderna när du använder dem.
Nu ska vi titta på hur nodpooler och hur AKS använder noder och sedan hur du skalar antalet noder i en nodpool.
Vad är en nodpool?
En nodpool beskriver en grupp noder med samma konfiguration i ett AKS-kluster. Dessa noder innehåller de underliggande virtuella datorer som kör dina program. Du kan skapa två typer av nodpooler i ett AKS-hanterat Kubernetes-kluster:
Systemnodpooler
Användarnodpooler
Systemnodpooler
Systemnodpooler är värd för kritiska systempoddar som utgör klustrets kontrollplan. En systemnodpool tillåter endast användning av Linux som nodoperativsystem och kör endast Linux-baserade arbetsbelastningar. Noder i en systemnodpool är reserverade för systemarbetsbelastningar och används normalt inte för att köra anpassade arbetsbelastningar. Varje AKS-kluster måste innehålla minst en systemnodpool med minst en nod och du måste definiera de underliggande VM-storlekarna för noder.
Användarnodpooler
Användarnodpooler stöder dina arbetsbelastningar och du kan ange Windows eller Linux som nodoperativsystem. Du kan också definiera de underliggande VM-storlekarna för noder och köra specifika arbetsbelastningar. Din lösning för drönarspårning har till exempel en batchbearbetningstjänst som du distribuerar till en nodpool med en konfiguration för allmänna virtuella datorer. Den nya tjänsten predictive-modeling kräver GPU-baserade virtuella datorer med högre kapacitet. Du bestämmer dig för att konfigurera en separat nodpool och konfigurera den så att den använder GPU-aktiverade noder.
Antal noder i en nodpool
Du kan konfigurera upp till 100 noder i en nodpool. Hur många noder du väljer att konfigurera beror dock på antalet poddar som körs per nod.
I en systemnodpool är det till exempel viktigt att ange det maximala antalet poddar som körs på en enskild nod till 30. Det här värdet garanterar att det finns tillräckligt med utrymme för att köra systempoddar som är kritiska för klustrets hälsa. När antalet poddar överskrider det här minimivärdet krävs nya noder i poolen för att schemalägga extra arbetsbelastningar. Därför behöver en systemnodpool minst en nod i poolen. För produktionsmiljöer är det rekommenderade antalet noder för en systemnodpool minst tre noder.
Användarnodpooler är utformade för att köra anpassade arbetsuppgifter och har inte kravet på 30 poddar. Med användarnodpooler kan du ange antalet noder för en pool till noll.
Hantera programefterfrågan i ett AKS-kluster
När du i AKS ökar eller minskar mängden beräkningsresurser i ett Kubernetes-kluster du skala. Du kan skala antingen antalet arbetsbelastningsinstanser som behöver köras eller antalet noder som dessa arbetsbelastningar körs på. Du kan skala arbetsbelastningar i ett AKS-hanterat kluster på ett av två sätt. Det första alternativet är att anpassa antalet poddar eller noder manuellt efter behov. Det andra alternativet är genom automatisering, där du kan använda den horisontella poddautoskalningen för att skala poddar och klusterautoskalningen för att skala noder.
Så här skalar du en nodpool manuellt
Om du kör arbetsbelastningar som körs under en viss tid med specifika kända intervall är manuellt skalning av nodpoolens storlek ett bra sätt att kontrollera nodkostnaderna.
Anta att tjänsten predictive-modeling kräver en GPU-baserad nodpool och körs i en timme varje dag kl. 12.00. Du kan konfigurera nodpoolen med specifika GPU-baserade noder och skala nodpoolen till noll noder när du inte använder klustret.
Här är ett exempel på kommandot az aks node pool add som du kan använda för att skapa nodpoolen. Observera parametern --node-vm-size, som anger den Standard_NC6 GPU-baserade VM-storleken för noderna i poolen.
az aks nodepool add \
--resource-group resourceGroup \
--cluster-name aksCluster \
--name gpunodepool \
--node-count 1 \
--node-vm-size Standard_NC6 \
--no-wait
När poolen är klar kan du använda kommandot az aks nodepool scale för att skala nodpoolen till noll noder. Observera att parametern --node-count är inställd på noll. Här är ett exempel på kommandot:
az aks nodepool scale \
--resource-group resourceGroup \
--cluster-name aksCluster \
--name gpunodepool \
--node-count 0
Så här skalar du ett kluster automatiskt
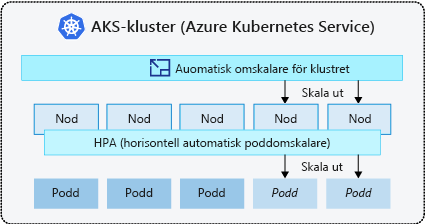
AKS använder autoskalning av Kubernetes-kluster för att automatiskt skala arbetsbelastningar. Klustret kan skalas med hjälp av två alternativ:
Den horisontella autoskalaren för poddar
Kluster-autoskalare
Nu ska vi titta på varje alternativ och börja med den horisontella podautoskalaren.
Horisontell pod-autoscaler
Använd Kubernetes horisontella podd-autoskalaren för att övervaka resursefterfrågan i ett kluster och automatiskt skala antalet arbetslastkopior.
Kubernetes Metrics Server samlar in minnes- och processormått från styrenheter, noder och containrar som körs i AKS-klustret. Ett sätt att komma åt den här informationen är att använda mått-API:et. Den horisontella pod-tillväxtskalaren kontrollerar Metrics API:t var 30:e sekund för att avgöra om applikationen behöver fler instanser för att möta den efterfrågade belastningen.
Anta att ditt företag också har en batchbearbetningstjänst som schemalägger drönarflygningsvägar. Du märker att tjänsten översvämmas av begäranden och bygger upp en leveransbacklog, vilket leder till förseningar och frustration för kunderna. Om du ökar antalet tjänstrepliker för batchbearbetning kan du göra det möjligt att bearbeta beställningar i rätt tid.
För att lösa problemet konfigurerar du den horisontella autoskalaren för poddar för att öka antalet servicereplikor vid behov. När antalet batchbegäranden minskar minskar antalet tjänstrepliker.
Den horisontella poddens autoskalering skalar dock endast på de noder som är tillgängliga i klustrets konfigurerade nodpooler.
Autoskalning av kluster
En resursbegränsning aktiveras när den horisontella podautoskalaren inte kan schemalägga en annan podd på befintliga noder i en nodpool. Du måste använda autoskalning av kluster för att skala antalet noder i ett klusters nodpooler i tider av begränsningar. Autoskalning av kluster kontrollerar de definierade måtten och skalar upp eller ned antalet noder baserat på de beräkningsresurser som krävs.
Kluster-autoskalaren används tillsammans med den vågräta podd-autoskalaren.
Autoskalning av kluster övervakar både uppskalnings- och nedskalningshändelser och gör att Kubernetes-klustret kan ändra antalet noder i en nodpool när resursbehoven ändras.
Du konfigurerar varje nodpool med olika skalningsregler. Du kanske till exempel bara vill konfigurera en nodpool för att tillåta automatisk skalning, eller så kan du konfigurera en nodpool så att den endast skalas till ett visst antal noder.
Viktig
Du förlorar möjligheten att skala antalet noder till noll när du aktiverar autoskalning av klustret i en nodpool. I stället kan du ange minsta antal till noll för att spara på klusterresurser.