Koncept – Distribuering av program
Innan du distribuerar programmet till Kubernetes ska vi gå igenom Kubernetes-distributioner och diskutera deras begränsningar i vårt scenario.
Vad är Kubernetes-distributioner?
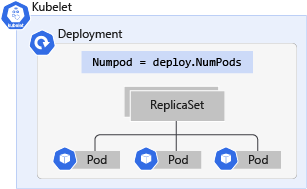
En Kubernetes-distribution är en utveckling av poddar. Distributioner omsluter poddar till ett intelligent objekt som gör att de kan skala ut. Du kan enkelt duplicera och skala ditt program för att stödja mer belastning utan att behöva konfigurera komplexa nätverksregler.
Med distributioner kan du uppdatera dina program utan avbrott bara genom att ändra avbildningstaggen. När du uppdaterar en distribution inaktiveras onlineapparna en i taget och ersätter dem med den senaste versionen i stället för att ta bort alla appar och skapa nya, vilket innebär att Distribution kan uppdatera poddarna i den utan någon synlig effekt på tillgängligheten.
Det finns många fördelar med att använda distributioner via poddar, men de kan inte hantera vårt scenario på ett tillfredsställande sätt.
Det här scenariot omfattar ett händelsedrivet program som tar emot ett stort antal händelser vid olika tidpunkter. Utan ett KEDA Scaler-objekt eller HPA skulle du behöva justera antalet repliker manuellt för att bearbeta antalet händelser och skala ned distributionen när belastningen återgår till det normala.
Exempel på distributionsmanifest
Här är ett exempelfragment i vårt distributionsmanifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: contoso-microservice
spec:
replicas: 10 # Tells K8S the number of pods needed to process the Redis list items
selector: # Define the wrapping strategy
matchLabels: # Match all pods with the defined labels
app: contoso-microservice # Labels follow the `name: value` template
template: # Template of the pod inside the deployment
metadata:
labels:
app: contoso-microservice
spec:
containers:
- image: mcr.microsoft.com/mslearn/samples/redis-client:latest
name: contoso-microservice
I exempelmanifestet är replicas inställt på 10, vilket är det högsta antal vi kan ange för nödvändiga repliker som behövs för att bearbeta det maximala antalet händelser. Detta gör dock att programmet förbrukar för många resurser under lågbelastade tider, vilket kan beröva andra distribueringar på resurser inom klustret.
En lösning är att använda en fristående HPA för att övervaka processoranvändningen för poddarna, vilket är ett bättre alternativ än att skala manuellt i båda riktningarna. HPA fokuserar dock inte på antalet händelser som tas emot till Redis-listan.
Den bästa lösningen är att använda KEDA och en Redis-skalnings för att fråga listan och avgöra om fler eller färre poddar behövs för att bearbeta händelserna.