Skalning med KEDA
Kubernetes Händelsedriven autoskalning
Kubernetes Händelsedriven autoskalning (KEDA) är en enkel och lätt komponent som förenklar automatisk skalning av program. Du kan lägga till KEDA i alla Kubernetes-kluster och använda det tillsammans med Kubernetes-standardkomponenter, till exempel HPA (Horizontal Pod Autoscaler) eller Cluster Autoscaler, för att utöka deras funktioner. Med KEDA kan du rikta in dig på specifika appar som du vill utnyttja händelsedriven skalning och låta andra appar använda olika skalningsmetoder. KEDA är ett flexibelt och säkert alternativ att köra tillsammans med valfritt antal Kubernetes-program eller ramverk.
Viktiga funktioner
- Skapa hållbara och kostnadseffektiva program med skalbara till noll-funktioner
- Skala programarbetsbelastningar för att möta efterfrågan med hjälp av KEDA-skalor
- Autoskalning av program med
ScaledObjects - Autoskalningsjobb med
ScaledJobs - Använda säkerhet i produktionsklass genom att koppla bort automatisk skalning och autentisering från arbetsbelastningar
- Bring-your-own extern skalning för att använda skräddarsydda autoskalningskonfigurationer
Arkitektur
KEDA innehåller två huvudkomponenter:
-
KEDA-operator: Tillåter slutanvändare att skala in eller ut arbetsbelastningar från noll till N-instanser med stöd för Kubernetes-distributioner, jobb, statefulSets eller alla kundresurser som definierar en
/scaleunderresurs. - Måttserver: Exponerar externa mått för HPA, till exempel meddelanden i ett Kafka-ämne eller händelser i Azure Event Hubs, för att köra autoskalningsåtgärder. På grund av tidigare begränsningar måste KEDA-måttservern vara det enda installerade måttkortet i klustret.
Följande diagram visar hur KEDA integreras med Kubernetes HPA, externa händelsekällor och Kubernetes API Server för att tillhandahålla funktioner för automatisk skalning:
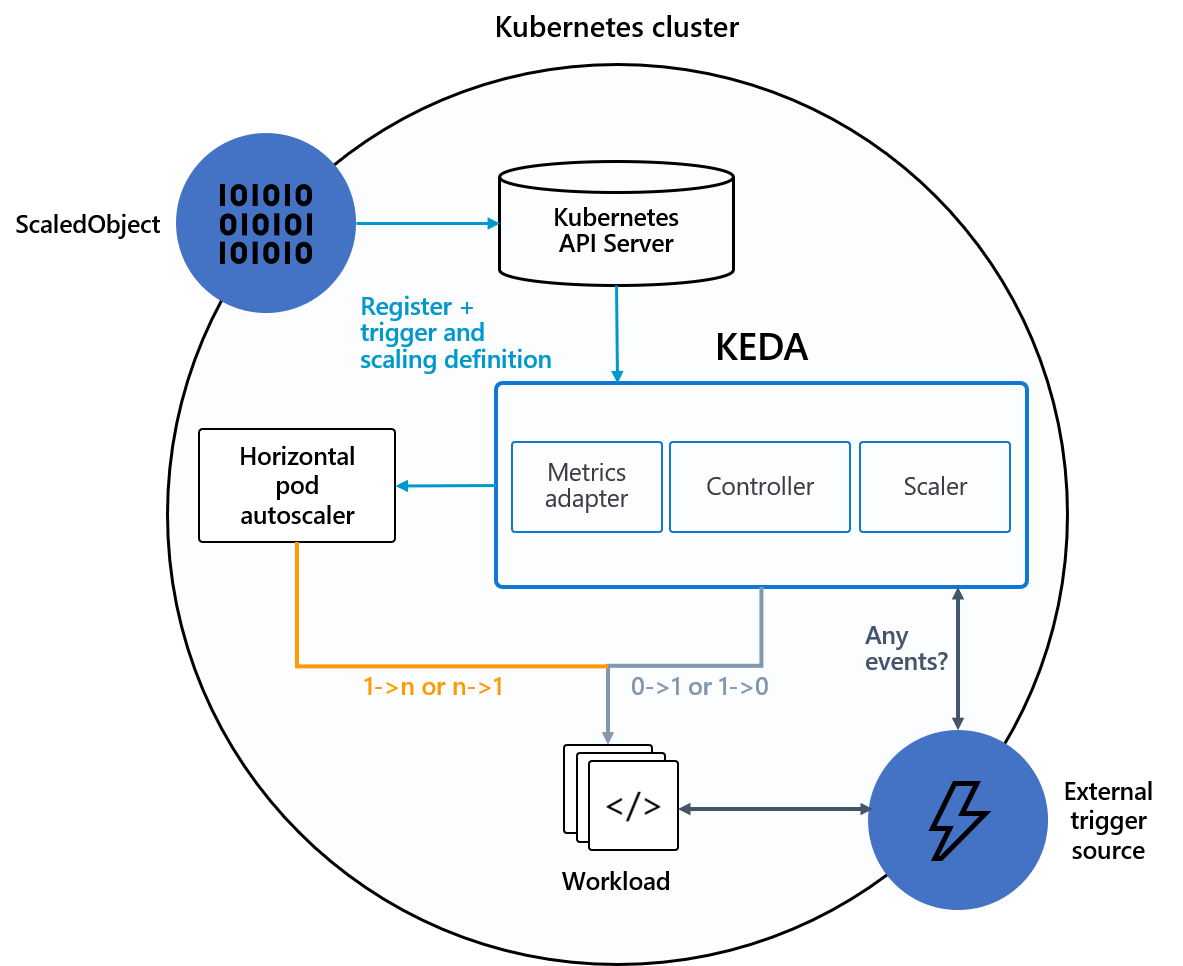
Händelsekällor och skalare
KEDA-skalare kan identifiera om en distribution ska aktiveras eller inaktiveras och mata in anpassade mått för en specifik händelsekälla. Distributioner och StatefulSets är det vanligaste sättet att skala arbetsbelastningar med KEDA. Du kan också skala anpassade resurser som implementerar underresursen /scale . Du kan definiera Kubernetes Deployment eller StatefulSet som du vill att KEDA ska skala baserat på en skalningsutlösare. KEDA övervakar dessa tjänster och skalar dem automatiskt in eller ut baserat på de händelser som inträffar.
I bakgrunden övervakar KEDA händelsekällan och matar dessa data till Kubernetes och HPA för att driva snabb resursskalning. Varje replik av en resurs hämtar aktivt objekt från händelsekällan. Med KEDA och Deployments/StatefulSetskan du skala baserat på händelser samtidigt som du bevarar omfattande anslutning och bearbetning av semantik med händelsekällan (till exempel bearbetning i ordning, återförsök, deadletter eller kontrollpunkter).
Skalningsobjektspecifikation
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Skalningsuppgiftsspecifikation
Som ett alternativ till att skala händelsedriven kod som Distributioner kan du också köra och skala koden som ett Kubernetes-jobb. Den främsta anledningen att överväga det här alternativet är om du behöver bearbeta långvariga körningar. I stället för att bearbeta flera händelser i en distribution schemalägger varje identifierad händelse sitt eget Kubernetes-jobb. Med den här metoden kan du bearbeta varje händelse isolerat och skala antalet samtidiga körningar baserat på antalet händelser i kön.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}