Hantera Storage Spaces Direct i VMM
Den här artikeln innehåller en översikt över Storage Spaces Direct (S2D) och hur det distribueras i fabric i System Center Virtual Machine Manager (VMM).
Lagringsutrymmen Direct (S2D) introducerades med Windows Server 2016. Den grupperar fysiska lagringsenheter i virtuella lagringspooler för att tillhandahålla virtualiserad lagring. Med virtualiserad lagring kan du:
- Hantera flera fysiska lagringskällor som en enda virtuell entitet.
- Få billig lagring, med och utan externa lagringsenheter.
- Samla in olika typer av lagring i en enda virtuell lagringspool.
- Etablera enkelt lagring och expandera virtualiserad lagring på begäran genom att lägga till nya enheter.
Anteckning
VMM 2019 UR3 och senare stöder Azure Stack Hyper Converged Infrastructure (HCI, version 20H2).
Notera
VMM 2025 stöder Azure Local (version 23H2 och 22H2).
Hur fungerar det?
S2D skapar lagringspooler från lagring som är anslutna till specifika noder i ett Windows Server-kluster. Lagringen kan vara intern på noden eller diskenheterna som är direkt anslutna till en enskild nod. Lagringsenheter som stöds är NVMe, SSD som är anslutna via SATA eller SAS och HDD. Läs mer.
- När du aktiverar S2D i ett Windows Server-kluster identifierar S2D automatiskt berättigad lagring och lägger till den i en lagringspool för klustret.
- S2D skapar också en inbyggd lagringscache på serversidan för att maximera prestanda. De snabbaste enheterna används för cachelagring och återstående enheter för kapacitet. Läs mer om cacheminnet.
- Du skapar volymer från en lagringspool. När du skapar en volym skapas den virtuella disken (lagringsutrymme), partitioner och formaterar den, lägger till den i klustret och konverterar den till en klusterdelad volym (CSV).
- Du konfigurerar olika nivåer av feltolerans för en volym för att ange hur virtuella diskar sprids över fysiska diskar i poolen med hjälp av SMB 3.0. Du kan konfigurera en volym utan resiliens eller med speglings- eller paritetsresiliens. Läs mer.
Konvergerad och icke-konvergerad distribution
Ett kluster som kör S2D kan distribueras på ett par sätt:
- Hyperkonvergerad distribution: Hyper-V beräkning och S2D-lagring körs i samma kluster, utan någon separation mellan dem. Detta ger samtidig skalning av beräknings- och lagringsresurser.
- Disaggregerad distribution: Beräkningsresurser körs på ett Hyper-V kluster. S2D-lagring körs på ett annat kluster. Du skalar klustren separat för finjusterad hantering.
Hyperkonvergerad distribution
Här är en bild för hyperkonvergerad distribution
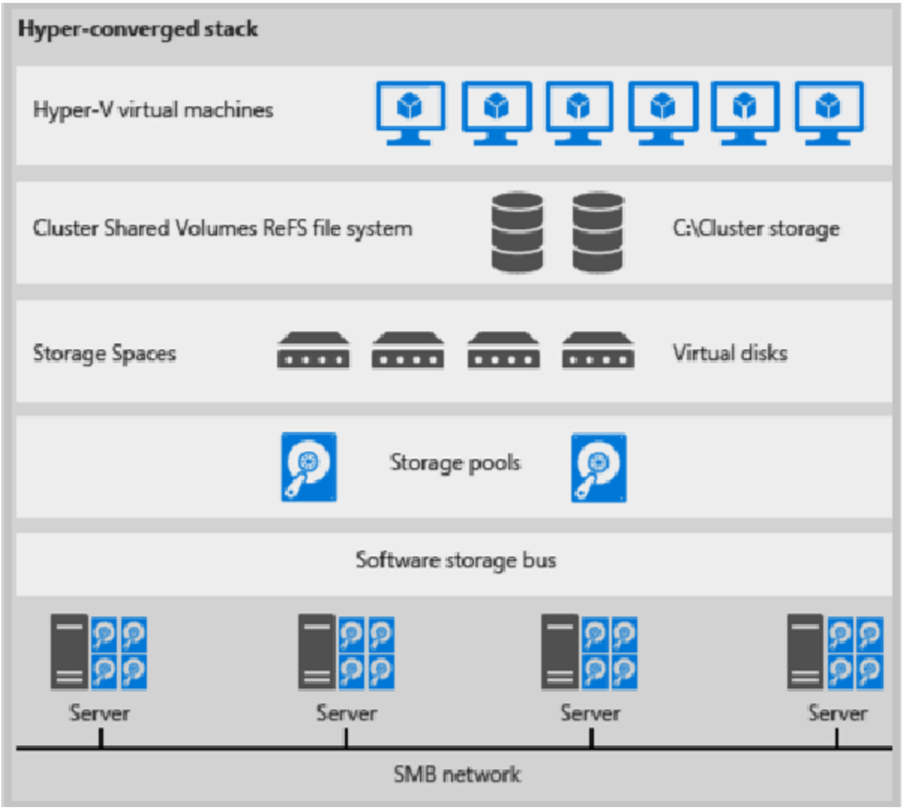
bild 1: Hyperkonvergerad distribution
- VM-filer lagras på lokala CSV:er.
- Filresurser och SMB används inte.
- När S2D CSV-volymer är tillgängliga etablerar du dem på samma sätt som andra Hyper-V-distributioner.
- Du skalar Hyper-V beräkningsklustret tillsammans med dess S2D-lagring.
Disaggregerad distribution
Här är en illustration för disaggregerad distribution
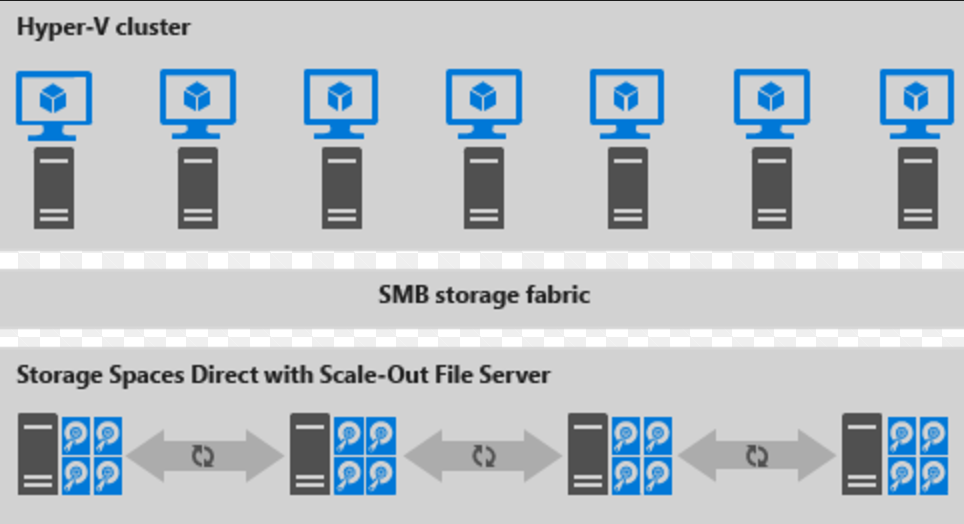
bild 2: Disaggregerad distribution
- Filresurser skapas på S2D CSV:er.
- Hyper-V virtuella datorer har konfigurerats för att lagra sina filer på den utskalade filservern (SOFS) och nås med hjälp av SMB 3.0.
- Du skalar Hyper-V- och SOFS-kluster separat för finjusteringshantering. Till exempel kan beräkningsnoder vara nästan full kapacitet för många virtuella datorer, men lagringsnoder kan ha överskott av disk och IOPS-kapacitet. så du lägger bara till ytterligare beräkningsnoder.