SKAPA EXTERN TABELL (Transact-SQL)
Skapar en extern tabell.
Den här artikeln innehåller syntax, argument, kommentarer, behörigheter och exempel för vilken SQL-produkt du väljer.
Mer information om syntaxkonventionerna finns i Transact-SQL syntaxkonventioner.
Välj en produkt
På följande rad väljer du det produktnamn som du är intresserad av och endast den produktinformationen visas.
* SQL Server *
Översikt: SQL Server
Det här kommandot skapar en extern tabell för PolyBase för åtkomst till data som lagras i ett Hadoop-kluster eller en extern Azure Blob Storage PolyBase-tabell som refererar till data som lagras i ett Hadoop-kluster eller Azure Blob Storage.
gäller för: SQL Server 2016 (eller senare)
Använd en extern tabell med en extern datakälla för PolyBase-frågor. Externa datakällor används för att upprätta anslutningar och stöder dessa primära användningsfall:
- Datavirtualisering och datainläsning med hjälp av PolyBase
- Massinläsningsåtgärder med SQL Server eller SQL Database med hjälp av
BULK INSERTellerOPENROWSET
Se även CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Syntax
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argument
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Tabellens namn i en till tre delar som ska skapas. För en extern tabell lagrar SQL endast tabellmetadata tillsammans med grundläggande statistik om filen eller mappen som refereras till i Hadoop eller Azure Blob Storage. Inga faktiska data flyttas eller lagras i SQL Server.
Viktig
Om drivrutinen för den externa datakällan har stöd för ett namn i tre delar rekommenderar vi starkt att du anger namnet i tre delar.
<column_definition> [ ,...n ]
SKAPA EXTERN TABELL har stöd för möjligheten att konfigurera kolumnnamn, datatyp, nullbarhet och sortering. Du kan inte använda STANDARDVILLKORet för externa tabeller.
Kolumndefinitionerna, inklusive datatyperna och antalet kolumner, måste matcha data i de externa filerna. Om det uppstår ett matchningsfel avvisas filraderna när du frågar efter faktiska data.
LOCATION = 'folder_or_filepath'
Anger mappen eller filsökvägen och filnamnet för faktiska data i Hadoop eller Azure Blob Storage. Dessutom stöds S3-kompatibel objektlagring från och med SQL Server 2022 (16.x)). Platsen börjar från rotmappen. Rotmappen är den dataplats som anges i den externa datakällan.
I SQL Server skapar CREATE EXTERNAL TABLE-instruktionen sökvägen och mappen om den inte redan finns. Du kan sedan använda INSERT INTO för att exportera data från en lokal SQL Server-tabell till den externa datakällan. Mer information finns i PolyBase-frågor.
Om du anger PLATS som en mapp hämtar en PolyBase-fråga som väljer från den externa tabellen filer från mappen och alla dess undermappar. Precis som Hadoop returnerar PolyBase inte dolda mappar. Det returnerar inte heller filer som filnamnet börjar med en understrykning (_) eller en punkt (.).
I följande bildexempel returnerar en PolyBase-fråga rader från LOCATION='/webdata/' och mydata.txtom mydata2.txt. Den returnerar inte mydata3.txt eftersom det är en fil i en dold undermapp. Och den returnerar inte _hidden.txt eftersom det är en dold fil.
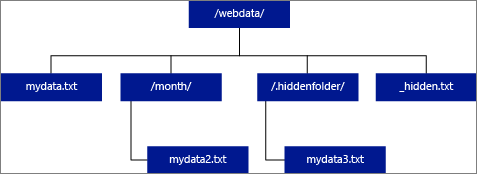
Om du vill ändra standardvärdet och bara läsa från rotmappen anger du attributet <polybase.recursive.traversal> till "false" i core-site.xml konfigurationsfilen. Den här filen finns under <SqlBinRoot>\PolyBase\Hadoop\Conf under bin-roten för SQL Server. Till exempel C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Anger namnet på den externa datakälla som innehåller platsen för externa data. Den här platsen är ett Hadoop-filsystem (HDFS), en Azure Blob Storage-container eller Azure Data Lake Store. Om du vill skapa en extern datakälla använder du CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Anger namnet på det externa filformatobjektet som lagrar filtypen och komprimeringsmetoden för externa data. Om du vill skapa ett externt filformat använder du CREATE EXTERNAL FILE FORMAT.
Externa filformat kan återanvändas av flera liknande externa filer.
Avvisa alternativ
Det här alternativet kan endast användas med externa datakällor där TYPE = HADOOP.
Du kan ange avvisa parametrar som avgör hur PolyBase ska hantera smutsiga poster som den hämtar från den externa datakällan. En datapost anses vara "smutsig" om den faktiska datatypen eller antalet kolumner inte matchar kolumndefinitionerna för den externa tabellen.
När du inte anger eller ändrar avvisande värden använder PolyBase standardvärden. Den här informationen om parametrarna för avvisande lagras som ytterligare metadata när du skapar en extern tabell med INSTRUKTIONEN SKAPA EXTERN TABELL. När en framtida SELECT-instruktion eller SELECT INTO SELECT-instruktion väljer data från den externa tabellen använder PolyBase alternativen för att avvisa för att fastställa antalet eller procentandelen rader som kan avvisas innan den faktiska frågan misslyckas. Frågan returnerar (partiella) resultat tills tröskelvärdet för avvisande överskrids. Det misslyckas sedan med lämpligt felmeddelande.
REJECT_TYPE = värde | procent
Klargör om alternativet REJECT_VALUE anges som ett literalvärde eller en procentandel.
värde
REJECT_VALUE är ett literalvärde, inte en procentandel. Frågan misslyckas när antalet avvisade rader överskrider reject_value.
Om till exempel REJECT_VALUE = 5 och REJECT_TYPE = valuemisslyckas SELECT-frågan efter att fem rader har avvisats.
procentsats
REJECT_VALUE är en procentandel, inte ett literalvärde. En fråga misslyckas när den procentsatsen av misslyckade rader överskrider reject_value. Procentandelen misslyckade rader beräknas med intervall.
REJECT_VALUE = reject_value
Anger värdet eller procentandelen rader som kan avvisas innan frågan misslyckas.
För REJECT_TYPE = värde måste reject_value vara ett heltal mellan 0 och 2 147 483 647.
För REJECT_TYPE = procent måste reject_value vara en flyttal mellan 0 och 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Det här attributet krävs när du anger REJECT_TYPE = procent. Den avgör hur många rader som ska hämtas innan PolyBase beräknar om procentandelen avvisade rader.
Parametern reject_sample_value måste vara ett heltal mellan 0 och 2 147 483 647.
Om till exempel REJECT_SAMPLE_VALUE = 1 000 beräknar PolyBase procentandelen misslyckade rader när den har försökt importera 1 000 rader från den externa datafilen. Om procentandelen misslyckade rader är mindre än reject_valueförsöker PolyBase hämta ytterligare 1 000 rader. Den fortsätter att beräkna om procentandelen misslyckade rader när den försöker importera ytterligare 1 000 rader.
Not
Eftersom PolyBase beräknar procentandelen misslyckade rader med intervall kan den faktiska procentandelen misslyckade rader överskrida reject_value.
Exempel:
Det här exemplet visar hur de tre REJECT-alternativen interagerar med varandra. Om till exempel REJECT_TYPE = procent, REJECT_VALUE = 30 och REJECT_SAMPLE_VALUE = 100 kan följande scenario inträffa:
- PolyBase försöker hämta de första 100 raderna. 25 misslyckas och 75 lyckas.
- Procent av misslyckade rader beräknas som 25%, vilket är mindre än värdet för avvisande av 30%. Därför fortsätter PolyBase att hämta data från den externa datakällan.
- PolyBase försöker läsa in de kommande 100 raderna. den här gången lyckas 25 rader och 75 rader misslyckas.
- Procent av misslyckade rader beräknas om till 50%. Procentandelen misslyckade rader har överskridit värdet 30% avvisa.
- PolyBase-frågan misslyckas med 50% avvisade rader efter försök att returnera de första 200 raderna. Observera att matchande rader har returnerats innan PolyBase-frågan upptäcker att tröskelvärdet för avvisande har överskridits.
REJECTED_ROW_LOCATION = katalogplats
gäller för: SQL Server 2019 CU6 och senare versioner, Azure Synapse Analytics.
Anger den katalog i den externa datakällan som de avvisade raderna och motsvarande felfil ska skrivas.
Om den angivna sökvägen inte finns skapar PolyBase en för din räkning. En underordnad katalog skapas med namnet _rejectedrows. Tecknet _ säkerställer att katalogen är undantagen för annan databehandling om den inte uttryckligen namnges i platsparametern. I den här katalogen skapas en mapp baserat på tidpunkten för inläsningen i formatet YearMonthDay -HourMinuteSecond (till exempel 20230330-173205). I den här mappen skrivs två typer av filer, _reason-filen och datafilen. Det här alternativet kan endast användas med externa datakällor där TYPE = HADOOP och för externa tabeller med hjälp av DELIMITEDTEXTFORMAT_TYPE. Mer information finns i CREATE EXTERNAL DATA SOURCE and CREATE EXTERNAL FILE FORMAT.
Orsaksfilerna och datafilerna har båda queryID associerade med CTAS-instruktionen. Eftersom data och orsaken finns i separata filer har motsvarande filer ett matchande suffix.
Behörigheter
Kräver följande användarbehörigheter:
- CREATE TABLE
- ÄNDRA SCHEMA
- ÄNDRA ALLA EXTERNA DATAKÄLLOR
- ÄNDRA ALLA EXTERNA FILFORMAT (gäller endast externa datakällor för Hadoop och Azure Storage)
- CONTROL DATABASE (gäller endast externa datakällor för Hadoop och Azure Storage)
Observera att fjärrinloggningen som anges i DATABASE SCOPED CREDENTIAL som används i kommandot CREATE EXTERNAL TABLE måste ha Läs behörighet för sökvägen/tabellen/samlingen på den externa datakällan som anges i parametern LOCATION. Om du planerar att använda den här EXTERNA TABELLEN för att exportera data till en extern Datakälla för Hadoop eller Azure Storage måste den angivna inloggningen ha skrivbehörighet på sökvägen som anges i PLATS. Observera att Hadoop inte stöds i SQL Server 2022 (16.x).
När du konfigurerar åtkomstnycklarna och signaturen för delad åtkomst i Azure-portalen, Azure Blob Storage- eller ADLS Gen2-lagringskontona för Azure Blob Storage konfigurerar du Tillåtna behörigheter att bevilja minst Läs- och Skriv behörigheter. List behörighet kan också krävas när du söker i mappar. Du måste också välja både Container och Object som tillåtna resurstyper.
Viktig
Behörigheten ALTER ANY EXTERNAL DATA SOURCE ger alla huvudnamn möjlighet att skapa och ändra alla externa datakällans objekt, och därför ger det också möjlighet att komma åt alla databasomfattningsautentiseringsuppgifter i databasen. Den här behörigheten måste betraktas som högprivilegierad och måste därför endast beviljas betrodda huvudnamn i systemet.
Felhantering
När du kör CREATE EXTERNAL TABLE-instruktionen försöker PolyBase ansluta till den externa datakällan. Om anslutningsförsöket misslyckas misslyckas instruktionen och den externa tabellen skapas inte. Det kan ta en minut eller mer innan kommandot misslyckas eftersom PolyBase försöker ansluta igen innan frågan slutligen misslyckas.
Anmärkningar
I ad hoc-frågescenarier, till exempel SELECT FROM EXTERNAL TABLE, lagrar PolyBase de rader som hämtas från den externa datakällan i en tillfällig tabell. När frågan är klar tar PolyBase bort och tar bort den tillfälliga tabellen. Inga permanenta data lagras i SQL-tabeller.
I importscenariot, till exempel SELECT INTO FROM EXTERNAL TABLE, lagrar PolyBase däremot de rader som hämtas från den externa datakällan som permanenta data i SQL-tabellen. Den nya tabellen skapas under frågekörningen när PolyBase hämtar externa data.
PolyBase kan skicka en del av frågeberäkningen till Hadoop för att förbättra frågeprestandan. Den här åtgärden kallas predikat-pushdown. Om du vill aktivera det anger du alternativet Hadoop resource manager location i CREATE EXTERNAL DATA SOURCE.
Du kan skapa många externa tabeller som refererar till samma eller olika externa datakällor.
Begränsningar och begränsningar
Eftersom data för en extern tabell inte kontrolleras direkt av SQL Server kan de ändras eller tas bort när som helst av en extern process. Därför är frågeresultaten mot en extern tabell inte garanterade att de är deterministiska. Samma fråga kan returnera olika resultat varje gång den körs mot en extern tabell. På samma sätt kan en fråga misslyckas om externa data flyttas eller tas bort.
Du kan skapa flera externa tabeller som varje referens till olika externa datakällor. Om du samtidigt kör frågor mot olika Hadoop-datakällor måste varje Hadoop-källa använda samma serverkonfigurationsinställning för hadoop-anslutning. Du kan till exempel inte köra en fråga samtidigt mot ett Cloudera Hadoop-kluster och ett Hortonworks Hadoop-kluster eftersom dessa använder olika konfigurationsinställningar. Konfigurationsinställningar och kombinationer som stöds finns i PolyBase-anslutningskonfiguration.
När den externa tabellen använder DELIMITEDTEXT, CSV, PARQUETeller DELTA som datatyper stöder externa tabeller endast statistik för en kolumn per CREATE STATISTICS kommando.
Endast dessa DDL-instruktioner (Data Definition Language) tillåts i externa tabeller:
- SKAPA TABELL OCH TA BORT TABELL
- SKAPA STATISTIK OCH TA BORT STATISTIK
- SKAPA VY OCH SLÄPP VY
Konstruktioner och åtgärder stöds inte:
- Standardvillkoret för externa tabellkolumner
- DML-åtgärder (Data Manipulation Language) för borttagning, infogning och uppdatering
Frågebegränsningar
PolyBase kan använda högst 33 000 filer per mapp när 32 samtidiga PolyBase-frågor körs. Det här maximala antalet inkluderar både filer och undermappar i varje HDFS-mapp. Om graden av samtidighet är mindre än 32 kan en användare köra PolyBase-frågor mot mappar i HDFS som innehåller mer än 33 000 filer. Vi rekommenderar att du håller externa filsökvägar korta och inte använder fler än 30 000 filer per HDFS-mapp. När för många filer refereras kan ett JVM-undantag (Java Virtual Machine) uppstå.
Begränsningar för tabellbredd
PolyBase i SQL Server 2016 har en radbreddsgräns på 32 KB baserat på den maximala storleken på en enda giltig rad per tabelldefinition. Om summan av kolumnschemat är större än 32 KB kan PolyBase inte köra frågor mot data.
Begränsningar för datatyp
Följande datatyper kan inte användas i externa PolyBase-tabeller:
- geografi
- geometri
- hierarchyid
- bild
- text
- ntext
- XML-
- Alla användardefinierade typer
Specifika begränsningar för datakälla
Orakel
Oracle-synonymer stöds inte för användning med PolyBase.
Externa tabeller till MongoDB-samlingar som innehåller matriser
Om du vill skapa externa tabeller till MongoDB-samlingar som innehåller matriser bör du använda tillägget Data Virtualization för Azure Data Studio för att skapa en CREATE EXTERNAL TABLE-instruktion baserat på det schema som identifierats av PolyBase ODBC-drivrutinen för MongoDB. Utplattande åtgärder utförs automatiskt av drivrutinen. Du kan också använda sp_data_source_objects (Transact-SQL) för att identifiera samlingsschemat (kolumner) och manuellt skapa den externa tabellen. Den sp_data_source_table_columns lagrade proceduren utför också automatiskt utplattande via PolyBase ODBC-drivrutinen för MongoDB-drivrutinen. Datavirtualiseringstillägget för Azure Data Studio och sp_data_source_table_columns använda samma interna lagrade procedurer för att köra frågor mot det externa schemat.
Låsning
Delat lås på OBJEKTET SCHEMARESOLUTION.
Säkerhet
Datafilerna för en extern tabell lagras i Hadoop eller Azure Blob Storage. Dessa datafiler skapas och hanteras av dina egna processer. Det är ditt ansvar att hantera säkerheten för externa data.
Exempel
A. Skapa en extern tabell med data i textavgränsat format
Det här exemplet visar alla steg som krävs för att skapa en extern tabell med data som är formaterade i textavgränsade filer. Den definierar en extern datakälla mydatasource och ett externt filformat myfileformat. Dessa objekt på databasnivå refereras sedan till i instruktionen CREATE EXTERNAL TABLE. Mer information finns i CREATE EXTERNAL DATA SOURCE and CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. Skapa en extern tabell med data i RCFile-format
I det här exemplet visas alla steg som krävs för att skapa en extern tabell som har data formaterade som RCFiles. Den definierar en extern datakälla mydatasource_rc och ett externt filformat myfileformat_rc. Dessa objekt på databasnivå refereras sedan till i instruktionen CREATE EXTERNAL TABLE. Mer information finns i CREATE EXTERNAL DATA SOURCE and CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. Skapa en extern tabell med data i ORC-format
I det här exemplet visas alla steg som krävs för att skapa en extern tabell med data som är formaterade som ORC-filer. Den definierar en extern datakälla mydatasource_orc och ett externt filformat myfileformat_orc. Dessa objekt på databasnivå refereras sedan till i instruktionen CREATE EXTERNAL TABLE. Mer information finns i CREATE EXTERNAL DATA SOURCE and CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Fråga Hadoop-data
ClickStream är en extern tabell som ansluter till den employee.tbl avgränsade textfilen i ett Hadoop-kluster. Följande fråga ser ut precis som en fråga mot en standardtabell. Den här frågan hämtar dock data från Hadoop och beräknar sedan resultatet.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Ansluta Hadoop-data till SQL-data
Den här frågan ser ut precis som en standardkoppling i två SQL-tabeller. Skillnaden är att PolyBase hämtar klickströmsdata från Hadoop och sedan ansluter dem till tabellen UrlDescription. En tabell är en extern tabell och den andra är en sql-standardtabell.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Importera data från Hadoop till en SQL-tabell
I det här exemplet skapas en ny SQL-tabell ms_user som permanent lagrar resultatet av en koppling mellan sql-standardtabellen user och den externa tabellen ClickStream.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Skapa en extern tabell för SQL Server
Innan du skapar en databasomfattande autentiseringsuppgift måste användardatabasen ha en huvudnyckel för att skydda autentiseringsuppgifterna. Mer information finns i CREATE MASTER KEY and CREATE DATABASE SCOPED CREDENTIAL.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
Skapa en ny extern datakälla med namnet SQLServerInstanceoch en extern tabell med namnet sqlserver.customer:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
Jag. Skapa en extern tabell för Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Skapa en extern tabell för Teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Skapa en extern tabell för MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. Fråga S3-kompatibelt objektlagring via extern tabell
gäller för: SQL Server 2022 (16.x) och senare
I följande exempel visas hur du använder T-SQL för att köra frågor mot en parquet-fil som lagras i S3-kompatibel objektlagring via frågor mot den externa tabellen. Exemplet använder en relativ sökväg i den externa datakällan.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
Nästa steg
Läs mer om relaterade begrepp i följande artiklar:
* Azure SQL Database *
Översikt: Azure SQL Database
I Azure SQL Database skapar du en extern tabell för elastiska frågor (i förhandsversion).
Se även SKAPA EXTERN DATAKÄLLA.
Syntax
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
Argument
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Tabellens namn i en till tre delar som ska skapas. För en extern tabell lagrar SQL endast tabellmetadata tillsammans med grundläggande statistik om filen eller mappen som refereras till i Azure SQL Database. Inga faktiska data flyttas eller lagras i Azure SQL Database.
Viktig
Om drivrutinen för den externa datakällan har stöd för ett namn i tre delar rekommenderar vi starkt att du anger namnet i tre delar.
<column_definition> [ ,...n ]
SKAPA EXTERN TABELL har stöd för möjligheten att konfigurera kolumnnamn, datatyp, nullbarhet och sortering. Du kan inte använda STANDARDVILLKORet för externa tabeller.
Not
Den texten, ntext, xmloch json datatyper stöds inte för kolumner i externa tabeller för Azure SQL Database.
Kolumndefinitionerna, inklusive datatyperna och antalet kolumner, måste matcha data i de externa filerna. Om det uppstår ett matchningsfel avvisas filraderna när du frågar efter faktiska data.
Alternativ för horisontell extern tabell
Anger den externa datakällan (en datakälla som inte är SQL Server) och en distributionsmetod för Elastic-frågan.
DATA_SOURCE
Satsen DATA_SOURCE definierar den externa datakällan (en fragmentkarta) som används för den externa tabellen. Ett exempel finns i Skapa externa tabeller.
Viktig
Azure SQL Database har stöd för att skapa externa tabeller till EXTERNA DATAKÄLLANs typer RDMS och SHARD_MAP_MANAGER. Azure SQL Database har inte stöd för att skapa externa tabeller till Azure Blob Storage.
SCHEMA_NAME och OBJECT_NAME
Satserna SCHEMA_NAME och OBJECT_NAME mappar den externa tabelldefinitionen till en tabell i ett annat schema. Om det utelämnas antas schemat för fjärrobjektet vara "dbo" och namnet antas vara identiskt med det externa tabellnamn som definieras. Detta är användbart om namnet på fjärrtabellen redan finns i databasen där du vill skapa den externa tabellen. Du vill till exempel definiera en extern tabell för att få en sammanställd vy över katalogvyer eller DMV:er på den utskalade datanivån. Eftersom katalogvyer och DMV:er redan finns lokalt kan du inte använda deras namn för den externa tabelldefinitionen. Använd i stället ett annat namn och använd katalogvyns eller DMV:ets namn i satserna SCHEMA_NAME och/eller OBJECT_NAME. Ett exempel finns i Skapa externa tabeller.
FÖRDELNING
Valfri. Det här argumentet krävs bara för databaser av typen SHARD_MAP_MANAGER. Det här argumentet styr om en tabell behandlas som en fragmenterad tabell eller en replikerad tabell. Med tabellerna SHARDED (kolumnnamn) överlappar inte data från olika tabeller. REPLIKERADE anger att tabeller har samma data på varje shard. ROUND_ROBIN anger att en programspecifik metod används för att distribuera data.
DISTRIBUTION-satsen anger den datadistribution som används för den här tabellen. Frågeprocessorn använder informationen i DISTRIBUTION-satsen för att skapa de mest effektiva frågeplanerna.
- SHARDED innebär att data partitioneras vågrätt mellan databaserna. Partitioneringsnyckeln för datadistributionen är parametern
sharding_column_name. - REPLIKERAD innebär att identiska kopior av tabellen finns i varje databas. Det är ditt ansvar att se till att replikerna är identiska mellan databaserna.
- ROUND_ROBIN innebär att tabellen partitioneras vågrätt med hjälp av en programberoende distributionsmetod.
Behörigheter
Användare med åtkomst till den externa tabellen får automatiskt åtkomst till de underliggande fjärrtabellerna under de autentiseringsuppgifter som anges i definitionen för den externa datakällan. Undvik oönskade utökade privilegier via autentiseringsuppgifterna för den externa datakällan. Använd GRANT eller REVOKE för en extern tabell precis som om det vore en vanlig tabell. När du har definierat din externa datakälla och dina externa tabeller kan du nu använda fullständig T-SQL över dina externa tabeller.
Felhantering
När du kör CREATE EXTERNAL TABLE-instruktionen misslyckas instruktionen och den externa tabellen inte skapas om anslutningsförsöket misslyckas. Det kan ta en minut eller mer innan kommandot misslyckas eftersom SQL Database försöker ansluta igen innan frågan slutligen misslyckas.
Anmärkningar
I ad hoc-frågescenarier, till exempel SELECT FROM EXTERNAL TABLE, lagrar SQL Database de rader som hämtas från den externa datakällan i en tillfällig tabell. När frågan är klar tar SQL Database bort och tar bort den tillfälliga tabellen. Inga permanenta data lagras i SQL-tabeller.
I importscenariot, till exempel SELECT INTO FROM EXTERNAL TABLE, lagrar SQL Database däremot de rader som hämtas från den externa datakällan som permanenta data i SQL-tabellen. Den nya tabellen skapas under frågekörningen när SQL Database hämtar externa data.
Du kan skapa många externa tabeller som refererar till samma eller olika externa datakällor.
Du kan skapa flera externa tabeller som varje referens till olika externa datakällor.
Begränsningar
Isoleringssemantik: Åtkomst till data via en extern tabell följer inte isoleringssemantiken i SQL Server. Det innebär att frågor mot en extern tabell inte medför någon isolering av låsning eller ögonblicksbilder. Därför kan datareturen ändras om data i den externa datakällan ändras. Samma fråga kan returnera olika resultat varje gång den körs mot en extern tabell. På samma sätt kan en fråga misslyckas om externa data flyttas eller tas bort.
konstruktioner och åtgärder som inte stöds:
- Standardvillkoret för externa tabellkolumner.
- DML-åtgärder (Data Manipulation Language) för borttagning, infogning och uppdatering.
- Dynamisk datamaskering på externa tabellkolumner.
- Markörer stöds inte för externa tabeller i Azure SQL Database.
Endast literalpredikat: Endast literalpredikat som definierats i en fråga kan skickas ned till den externa datakällan. Det här är till skillnad från länkade servrar och åtkomst där predikater som fastställs under frågekörningen kan användas, det vill s.v.s. när de används med en kapslad loop i en frågeplan. Detta leder ofta till att hela den externa tabellen kopieras lokalt och sedan ansluts.
I följande exempel, om
External.Ordersär en extern tabell ochCustomerär en lokal tabell, kopierar frågan hela den externa tabellen lokalt eftersom predikatet som behövs inte är känt vid kompileringstiden.SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );Ingen parallellitet: Användning av externa tabeller förhindrar användning av parallellitet i frågeplanen.
Körs som fjärrfråga: Externa tabeller implementeras som fjärrfråga, så det uppskattade antalet rader som returneras är i allmänhet 1 000. Det finns andra regler baserat på vilken typ av predikat som används för att filtrera den externa tabellen. De är regelbaserade uppskattningar snarare än uppskattningar baserade på faktiska data i den externa tabellen. Optimeraren har inte åtkomst till fjärrdatakällan för att få en mer exakt uppskattning.
Stöds inte för privat slutpunkt: Externa tabellfrågor stöds inte när anslutningen till fjärrtabellen är en privat slutpunkt.
Begränsningar för datatyp
Följande datatyper kan inte användas i externa PolyBase-tabeller:
- geografi
- geometri
- hierarchyid
- bild
- text
- ntext
- XML-
- Alla användardefinierade typer
Låsning
Delat lås på OBJEKTET SCHEMARESOLUTION.
Exempel
A. Skapa en extern tabell för Azure SQL Database
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. Skapa en extern tabell för en fragmenterad datakälla
I det här exemplet mappas en fjärr-DMV till en extern tabell med hjälp av satserna SCHEMA_NAME och OBJECT_NAME.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
Nästa steg
Läs mer om externa tabeller i Azure SQL Database i följande artiklar:
* Azure Synapse
Analys *
Översikt: Azure Synapse Analytics
Använd en extern tabell för att:
- Dedikerade SQL-pooler kan fråga, importera och lagra data från Hadoop, Azure Blob Storage och Azure Data Lake Storage Gen1 och Gen2.
- Serverlösa SQL-pooler kan fråga, importera och lagra data från Azure Blob Storage, Azure Data Lake Storage Gen1 och Gen2. Serverlös stöder inte
TYPE=Hadoop.
Se även CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Mer vägledning och exempel på hur du använder externa tabeller med Azure Synapse finns i Använda externa tabeller med Synapse SQL.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Argument
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Tabellens namn i en till tre delar som ska skapas. För en extern tabell är det bara tabellmetadata tillsammans med grundläggande statistik om filen eller mappen som refereras till i Azure Data Lake, Hadoop eller Azure Blob Storage. Inga faktiska data flyttas eller lagras när externa tabeller skapas.
Viktig
Om drivrutinen för den externa datakällan har stöd för ett namn i tre delar rekommenderar vi starkt att du anger namnet i tre delar.
<column_definition> [ ,...n ]
SKAPA EXTERN TABELL har stöd för möjligheten att konfigurera kolumnnamn, datatyp, nullbarhet och sortering. Du kan inte använda STANDARDVILLKORet för externa tabeller.
Not
Datatyperna text, ntextoch XML- stöds inte för kolumner i externa tabeller för Synapse Analytics.
- När du läser avgränsade filer måste kolumndefinitionerna, inklusive datatyperna och antalet kolumner, matcha data i de externa filerna. Om det uppstår ett matchningsfel avvisas filraderna när du frågar efter faktiska data.
- När du läser från Parquet-filer kan du bara ange de kolumner som du vill läsa och hoppa över resten.
LOCATION = 'folder_or_filepath'
Anger mappen eller filsökvägen och filnamnet för faktiska data i Azure Data Lake, Hadoop eller Azure Blob Storage. Platsen börjar från rotmappen. Rotmappen är den dataplats som anges i den externa datakällan.
CREATE EXTERNAL TABLE AS SELECT-instruktionen skapar sökvägen och mappen om den inte finns.
CREATE EXTERNAL TABLE skapar inte sökvägen och mappen.
Om du anger PLATS som en mapp hämtar en PolyBase-fråga som väljer från den externa tabellen filer från mappen och alla dess undermappar. Precis som Hadoop returnerar PolyBase inte dolda mappar. Det returnerar inte heller filer som filnamnet börjar med en understrykning (_) eller en punkt (.).
I följande bildexempel returnerar en PolyBase-fråga rader från LOCATION='/webdata/' och mydata.txtom mydata2.txt. Den returnerar inte mydata3.txt eftersom den finns i en undermapp i en dold mapp. Och den returnerar inte _hidden.txt eftersom det är en dold fil.
Till skillnad från externa Hadoop-tabeller returnerar interna externa tabeller inte undermappar om du inte anger /** i slutet av sökvägen. Om LOCATION='/webdata/'i det här exemplet returnerar en serverlös SQL-poolfråga rader från mydata.txt. Den returnerar inte mydata2.txt och mydata3.txt eftersom de finns i en undermapp. Hadoop-tabeller returnerar alla filer i alla undermappar.
Både Hadoop och interna externa tabeller hoppar över filerna med namnen som börjar med en understrykning (_) eller en punkt (.).
DATA_SOURCE = external_data_source_name
Anger namnet på den externa datakälla som innehåller platsen för externa data. Den här platsen finns i Azure Data Lake. Om du vill skapa en extern datakälla använder du CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Anger namnet på det externa filformatobjektet som lagrar filtypen och komprimeringsmetoden för externa data. Om du vill skapa ett externt filformat använder du CREATE EXTERNAL FILE FORMAT.
TABLE_OPTIONS
Anger den uppsättning alternativ som beskriver hur du läser de underliggande filerna. För närvarande är det enda alternativet som är tillgängligt {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]} som instruerar den externa tabellen att ignorera uppdateringarna som görs på de underliggande filerna, även om detta kan orsaka inkonsekventa läsåtgärder. Använd endast det här alternativet i särskilda fall där du ofta har bifogade filer. Det här alternativet är tillgängligt i serverlös SQL-pool för CSV-format.
ALTERNATIV FÖR AVVISA
Avvisa alternativ finns i förhandsversion för serverlösa SQL-pooler i Azure Synapse Analytics.
Det här alternativet kan endast användas med externa datakällor där TYPE = HADOOP.
Du kan ange avvisa parametrar som avgör hur PolyBase ska hantera smutsiga poster som den hämtar från den externa datakällan. En datapost anses vara "smutsig" om den faktiska datatypen eller antalet kolumner inte matchar kolumndefinitionerna för den externa tabellen.
När du inte anger eller ändrar avvisande värden använder PolyBase standardvärden. Den här informationen om parametrarna för avvisande lagras som ytterligare metadata när du skapar en extern tabell med INSTRUKTIONEN SKAPA EXTERN TABELL. När en framtida SELECT-instruktion eller SELECT INTO SELECT-instruktion väljer data från den externa tabellen använder PolyBase alternativen för att avvisa för att fastställa antalet eller procentandelen rader som kan avvisas innan den faktiska frågan misslyckas. Frågan returnerar (partiella) resultat tills tröskelvärdet för avvisande överskrids. Det misslyckas sedan med lämpligt felmeddelande.
Alternativet PARSER_VERSION format stöds endast i serverlösa SQL-pooler.
REJECT_TYPE = värde | procent
Klargör om alternativet REJECT_VALUE anges som ett literalvärde eller en procentandel.
värde
REJECT_VALUE är ett literalvärde, inte en procentandel. PolyBase-frågan misslyckas när antalet avvisade rader överskrider reject_value.
Om till exempel REJECT_VALUE = 5 och REJECT_TYPE = värde misslyckas PolyBase SELECT-frågan efter att fem rader har avvisats.
procentsats
REJECT_VALUE är en procentandel, inte ett literalvärde. En PolyBase-fråga misslyckas när procent av misslyckade rader överskrider reject_value. Procentandelen misslyckade rader beräknas med intervall.
REJECT_VALUE = reject_value
Anger värdet eller procentandelen rader som kan avvisas innan frågan misslyckas.
- För REJECT_TYPE = värde måste reject_value vara ett heltal mellan 0 och 2 147 483 647.
- För REJECT_TYPE = procent måste reject_value vara en flyttal mellan 0 och 100. Procentandelen är endast giltig för dedikerade SQL-pooler där
TYPE=HADOOP.
Frågan misslyckas när antalet avvisade rader överskrider reject_value. Om till exempel REJECT_VALUE = 5 och REJECT_TYPE = värde misslyckas SELECT-frågan efter att fem rader har avvisats.
REJECT_SAMPLE_VALUE = reject_sample_value
Det här attributet krävs när du anger REJECT_TYPE = procent. Den avgör hur många rader som ska hämtas innan PolyBase beräknar om procentandelen avvisade rader.
Parametern reject_sample_value måste vara ett heltal mellan 0 och 2 147 483 647.
Om till exempel REJECT_SAMPLE_VALUE = 1 000 beräknar PolyBase procentandelen misslyckade rader när den har försökt importera 1 000 rader från den externa datafilen. Om procentandelen misslyckade rader är mindre än reject_valueförsöker PolyBase hämta ytterligare 1 000 rader. Den fortsätter att beräkna om procentandelen misslyckade rader när den försöker importera ytterligare 1 000 rader.
Not
Eftersom PolyBase beräknar procentandelen misslyckade rader med intervall kan den faktiska procentandelen misslyckade rader överskrida reject_value.
Exempel:
Det här exemplet visar hur de tre REJECT-alternativen interagerar med varandra. Om till exempel REJECT_TYPE = procent, REJECT_VALUE = 30 och REJECT_SAMPLE_VALUE = 100 kan följande scenario inträffa:
- PolyBase försöker hämta de första 100 raderna. 25 misslyckas och 75 lyckas.
- Procent av misslyckade rader beräknas som 25%, vilket är mindre än värdet för avvisande av 30%. Därför fortsätter PolyBase att hämta data från den externa datakällan.
- PolyBase försöker läsa in de kommande 100 raderna. den här gången lyckas 25 rader och 75 rader misslyckas.
- Procent av misslyckade rader beräknas om till 50%. Procentandelen misslyckade rader har överskridit värdet 30% avvisa.
- PolyBase-frågan misslyckas med 50% avvisade rader efter försök att returnera de första 200 raderna. Observera att matchande rader har returnerats innan PolyBase-frågan upptäcker att tröskelvärdet för avvisande har överskridits.
REJECTED_ROW_LOCATION = katalogplats
Anger den katalog i den externa datakällan som de avvisade raderna och motsvarande felfil ska skrivas.
Om den angivna sökvägen inte finns skapas den. En underordnad katalog skapas med namnet _rejectedrows. Tecknet _ säkerställer att katalogen är undantagen för annan databehandling om den inte uttryckligen namnges i platsparametern.
- I serverlösa SQL-pooler är sökvägen
YearMonthDay_HourMinuteSecond_StatementID. Du kan användastatementIDför att korrelera mappen med frågan som genererade den. - I dedikerade SQL-pooler baseras sökvägen som skapats på tiden för inläsningen i formatet
YearMonthDay -HourMinuteSecond, till exempel20180330-173205.
I den här mappen skrivs två typer av filer, den _reason filen och datafilen.
Mer information finns i CREATE EXTERNAL DATA SOURCE.
Orsaksfilerna och datafilerna har båda queryID associerat med CTAS-instruktionen. Eftersom data och orsaken finns i separata filer har motsvarande filer ett matchande suffix.
I serverlösa SQL-pooler innehåller error.json-filen en JSON-matris med påträffade fel relaterade till avvisade rader. Varje element som representerar fel innehåller följande attribut:
| Attribut | Beskrivning |
|---|---|
| Fel | Orsak till varför raden avvisas. |
| Rad | Avvisade radordningsnummer i filen. |
| Spalt | Avvisad kolumnordningsnummer. |
| Värde | Avvisat kolumnvärde. Om värdet är större än 100 tecken visas endast de första 100 tecknen. |
| Fil | Sökväg till filen som raden tillhör. |
Behörigheter
Kräver följande användarbehörigheter:
- CREATE TABLE
- ÄNDRA SCHEMA
- ÄNDRA ALLA EXTERNA DATAKÄLLOR
- ÄNDRA ALLA EXTERNA FILFORMAT
Not
BEHÖRIGHETER FÖR KONTROLLDATABAS krävs för att endast skapa HUVUDNYCKELN, DATABASOMFATTNINGSAUTENTISERINGSUPPGIFTER OCH EXTERN DATAKÄLLA
Observera att inloggningen som skapar den externa datakällan måste ha behörighet att läsa och skriva till den externa datakällan i Hadoop eller Azure Blob Storage.
Viktig
Behörigheten ALTER ANY EXTERNAL DATA SOURCE ger alla huvudnamn möjlighet att skapa och ändra alla externa datakällans objekt, och därför ger det också möjlighet att komma åt alla databasomfattningsautentiseringsuppgifter i databasen. Den här behörigheten måste betraktas som högprivilegierad och måste därför endast beviljas betrodda huvudnamn i systemet.
Felhantering
När du kör CREATE EXTERNAL TABLE-instruktionen försöker PolyBase ansluta till den externa datakällan. Om anslutningsförsöket misslyckas misslyckas -instruktionen och den externa tabellen skapas inte. Det kan ta en minut eller mer innan kommandot misslyckas eftersom PolyBase försöker ansluta igen innan frågan slutligen misslyckas.
Anmärkningar
I ad hoc-frågescenarier, till exempel SELECT FROM EXTERNAL TABLE, lagrar PolyBase de rader som hämtas från den externa datakällan i en tillfällig tabell. När frågan är klar tar PolyBase bort och tar bort den tillfälliga tabellen. Inga permanenta data lagras i SQL-tabeller.
I importscenariot, till exempel SELECT INTO FROM EXTERNAL TABLE, lagrar PolyBase däremot de rader som hämtas från den externa datakällan som permanenta data i SQL-tabellen. Den nya tabellen skapas under frågekörningen när PolyBase hämtar externa data.
PolyBase kan skicka en del av frågeberäkningen till Hadoop för att förbättra frågeprestandan. Den här åtgärden kallas predikat-pushdown. Om du vill aktivera det anger du alternativet Hadoop resource manager location i CREATE EXTERNAL DATA SOURCE.
Du kan skapa många externa tabeller som refererar till samma eller olika externa datakällor.
Var uppmärksam på källdata med utf-8-sortering. För källdata som använder UTF-8-sortering måste du manuellt ange en icke-UTF-8-sortering för varje UTF-8-kolumn i CREATE EXTERNAL TABLE-instruktionen. Det beror på att UTF-8-stöd inte utökas till externa tabeller. När du försöker skapa en extern tabell med en UTF-8-sortering får du ett Unsupported collation felmeddelande. Om den externa tabellens databassortering är en UTF-8-sortering misslyckas skapande av externa tabeller om du inte anger en explicit kolumnsortering som inte är UTF-8, till exempel [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,.
Serverlösa och dedikerade SQL-pooler i Azure Synapse Analytics använder olika kodbaser för datavirtualisering. Serverlösa SQL-pooler stöder en inbyggd datavirtualiseringsteknik. Dedikerade SQL-pooler stöder både intern datavirtualisering och PolyBase-datavirtualisering. PolyBase-datavirtualisering används när DEN EXTERNA DATAKÄLLAN skapas med TYPE=HADOOP.
Begränsningar och begränsningar
Eftersom data för en extern tabell inte kontrolleras direkt av Azure Synapse kan de ändras eller tas bort när som helst av en extern process. Därför är frågeresultaten mot en extern tabell inte garanterade att de är deterministiska. Samma fråga kan returnera olika resultat varje gång den körs mot en extern tabell. På samma sätt kan en fråga misslyckas om externa data flyttas eller tas bort.
Du kan skapa flera externa tabeller som varje referens till olika externa datakällor.
Endast dessa DDL-instruktioner (Data Definition Language) tillåts i externa tabeller:
- SKAPA TABELL OCH TA BORT TABELL
- SKAPA STATISTIK OCH TA BORT STATISTIK
- SKAPA VY OCH SLÄPP VY
Konstruktioner och åtgärder stöds inte:
- Standardvillkoret för externa tabellkolumner
- DML-åtgärder (Data Manipulation Language) för borttagning, infogning och uppdatering
- dynamisk datamaskering på externa tabellkolumner
Frågebegränsningar
Vi rekommenderar att du inte överskrider fler än 30 000 filer per mapp. När för många filer refereras kan ett JVM-undantag (Java Virtual Machine) uppstå eller försämra prestanda.
Begränsningar för tabellbredd
PolyBase i Azure Data Warehouse har en radbreddsgräns på 1 MB baserat på den maximala storleken på en enda giltig rad per tabelldefinition. Om summan av kolumnschemat är större än 1 MB kan PolyBase inte köra frågor mot data.
Begränsningar för datatyp
Följande datatyper kan inte användas i externa PolyBase-tabeller:
- geografi
- geometri
- hierarchyid
- bild
- text
- ntext
- XML-
- Alla användardefinierade typer
Låsning
Delat lås på OBJEKTET SCHEMARESOLUTION.
Exempel
A. Importera data från ADLS Gen 2 till Azure Synapse Analytics
Exempel för Gen ADLS Gen 1 finns i Skapa extern datakälla.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Importera data från Parquet till Azure Synapse Analytics
I följande exempel skapas en extern tabell. Den returnerar sedan den första raden:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
Nästa steg
Läs mer om externa tabeller och relaterade begrepp i följande artiklar:
* Analys
Plattformssystem (PDW) *
Översikt: Analysplattformssystem
Använd en extern tabell för att:
- Fråga Hadoop- eller Azure Blob Storage-data med Transact-SQL-instruktioner.
- Importera och lagra data från Hadoop eller Azure Blob Storage till Analytics Platform System.
Se även CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
Argument
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Tabellens namn i en till tre delar som ska skapas. För en extern tabell lagrar Analytics Platform System endast tabellmetadata tillsammans med grundläggande statistik om filen eller mappen som refereras till i Hadoop eller Azure Blob Storage. Inga faktiska data flyttas eller lagras i Analytics Platform System.
Viktig
Om drivrutinen för den externa datakällan har stöd för ett namn i tre delar rekommenderar vi starkt att du anger namnet i tre delar.
<column_definition> [ ,...n ]
SKAPA EXTERN TABELL har stöd för möjligheten att konfigurera kolumnnamn, datatyp, nullbarhet och sortering. Du kan inte använda STANDARDVILLKORet för externa tabeller.
Kolumndefinitionerna, inklusive datatyperna och antalet kolumner, måste matcha data i de externa filerna. Om det uppstår ett matchningsfel avvisas filraderna när du frågar efter faktiska data.
LOCATION = 'folder_or_filepath'
Anger mappen eller filsökvägen och filnamnet för faktiska data i Hadoop eller Azure Blob Storage. Platsen börjar från rotmappen. Rotmappen är den dataplats som anges i den externa datakällan.
I Analytics Platform System skapar CREATE EXTERNAL TABLE AS SELECT-instruktionen sökvägen och mappen om den inte finns.
CREATE EXTERNAL TABLE skapar inte sökvägen och mappen.
Om du anger PLATS som en mapp hämtar en PolyBase-fråga som väljer från den externa tabellen filer från mappen och alla dess undermappar. Precis som Hadoop returnerar PolyBase inte dolda mappar. Det returnerar inte heller filer som filnamnet börjar med en understrykning (_) eller en punkt (.).
I följande bildexempel returnerar en PolyBase-fråga rader från LOCATION='/webdata/' och mydata.txtom mydata2.txt. Den returnerar inte mydata3.txt eftersom den finns i en undermapp i en dold mapp. Och den returnerar inte _hidden.txt eftersom det är en dold fil.
Om du vill ändra standardvärdet och bara läsa från rotmappen anger du attributet <polybase.recursive.traversal> till "false" i core-site.xml konfigurationsfilen. Den här filen finns under <SqlBinRoot>\PolyBase\Hadoop\Conf\ under bin-roten för SQL Server. Till exempel C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Anger namnet på den externa datakälla som innehåller platsen för externa data. Den här platsen är antingen en Hadoop eller Azure Blob Storage. Om du vill skapa en extern datakälla använder du CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Anger namnet på det externa filformatobjektet som lagrar filtypen och komprimeringsmetoden för externa data. Om du vill skapa ett externt filformat använder du CREATE EXTERNAL FILE FORMAT.
Avvisa alternativ
Det här alternativet kan endast användas med externa datakällor där TYPE = HADOOP.
Du kan ange avvisa parametrar som avgör hur PolyBase ska hantera smutsiga poster som den hämtar från den externa datakällan. En datapost anses vara "smutsig" om den faktiska datatypen eller antalet kolumner inte matchar kolumndefinitionerna för den externa tabellen.
När du inte anger eller ändrar avvisande värden använder PolyBase standardvärden. Den här informationen om parametrarna för avvisande lagras som ytterligare metadata när du skapar en extern tabell med INSTRUKTIONEN SKAPA EXTERN TABELL. När en framtida SELECT-instruktion eller SELECT INTO SELECT-instruktion väljer data från den externa tabellen använder PolyBase alternativen för att avvisa för att fastställa antalet eller procentandelen rader som kan avvisas innan den faktiska frågan misslyckas. Frågan returnerar (partiella) resultat tills tröskelvärdet för avvisande överskrids. Det misslyckas sedan med lämpligt felmeddelande.
REJECT_TYPE = värde | procent
Klargör om alternativet REJECT_VALUE anges som ett literalvärde eller en procentandel.
värde
REJECT_VALUE är ett literalvärde, inte en procentandel. PolyBase-frågan misslyckas när antalet avvisade rader överskrider reject_value.
Om till exempel REJECT_VALUE = 5 och REJECT_TYPE = värde misslyckas PolyBase SELECT-frågan efter att fem rader har avvisats.
procentsats
REJECT_VALUE är en procentandel, inte ett literalvärde. En PolyBase-fråga misslyckas när procent av misslyckade rader överskrider reject_value. Procentandelen misslyckade rader beräknas med intervall.
REJECT_VALUE = reject_value
Anger värdet eller procentandelen rader som kan avvisas innan frågan misslyckas.
För REJECT_TYPE = värde måste reject_value vara ett heltal mellan 0 och 2 147 483 647.
För REJECT_TYPE = procent måste reject_value vara en flyttal mellan 0 och 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Det här attributet krävs när du anger REJECT_TYPE = procent. Den avgör hur många rader som ska hämtas innan PolyBase beräknar om procentandelen avvisade rader.
Parametern reject_sample_value måste vara ett heltal mellan 0 och 2 147 483 647.
Om till exempel REJECT_SAMPLE_VALUE = 1 000 beräknar PolyBase procentandelen misslyckade rader när den har försökt importera 1 000 rader från den externa datafilen. Om procentandelen misslyckade rader är mindre än reject_valueförsöker PolyBase hämta ytterligare 1 000 rader. Den fortsätter att beräkna om procentandelen misslyckade rader när den försöker importera ytterligare 1 000 rader.
Not
Eftersom PolyBase beräknar procentandelen misslyckade rader med intervall kan den faktiska procentandelen misslyckade rader överskrida reject_value.
Exempel:
Det här exemplet visar hur de tre REJECT-alternativen interagerar med varandra. Om till exempel REJECT_TYPE = procent, REJECT_VALUE = 30 och REJECT_SAMPLE_VALUE = 100 kan följande scenario inträffa:
- PolyBase försöker hämta de första 100 raderna. 25 misslyckas och 75 lyckas.
- Procent av misslyckade rader beräknas som 25%, vilket är mindre än värdet för avvisande av 30%. Därför fortsätter PolyBase att hämta data från den externa datakällan.
- PolyBase försöker läsa in de kommande 100 raderna. den här gången lyckas 25 rader och 75 rader misslyckas.
- Procent av misslyckade rader beräknas om till 50%. Procentandelen misslyckade rader har överskridit värdet 30% avvisa.
- PolyBase-frågan misslyckas med 50% avvisade rader efter försök att returnera de första 200 raderna. Observera att matchande rader har returnerats innan PolyBase-frågan upptäcker att tröskelvärdet för avvisande har överskridits.
Behörigheter
Kräver följande användarbehörigheter:
- CREATE TABLE
- ÄNDRA SCHEMA
- ÄNDRA ALLA EXTERNA DATAKÄLLOR
- ÄNDRA ALLA EXTERNA FILFORMAT
- CONTROL DATABASE
Observera att inloggningen som skapar den externa datakällan måste ha behörighet att läsa och skriva till den externa datakällan i Hadoop eller Azure Blob Storage.
Viktig
Behörigheten ALTER ANY EXTERNAL DATA SOURCE ger alla huvudnamn möjlighet att skapa och ändra alla externa datakällans objekt, och därför ger det också möjlighet att komma åt alla databasomfattningsautentiseringsuppgifter i databasen. Den här behörigheten måste betraktas som högprivilegierad och måste därför endast beviljas betrodda huvudnamn i systemet.
Felhantering
När du kör CREATE EXTERNAL TABLE-instruktionen försöker PolyBase ansluta till den externa datakällan. Om anslutningsförsöket misslyckas misslyckas instruktionen och den externa tabellen skapas inte. Det kan ta en minut eller mer innan kommandot misslyckas eftersom PolyBase försöker ansluta igen innan frågan slutligen misslyckas.
Anmärkningar
I ad hoc-frågescenarier, till exempel SELECT FROM EXTERNAL TABLE, lagrar PolyBase de rader som hämtas från den externa datakällan i en tillfällig tabell. När frågan är klar tar PolyBase bort och tar bort den tillfälliga tabellen. Inga permanenta data lagras i SQL-tabeller.
I importscenariot, till exempel SELECT INTO FROM EXTERNAL TABLE, lagrar PolyBase däremot de rader som hämtas från den externa datakällan som permanenta data i SQL-tabellen. Den nya tabellen skapas under frågekörningen när PolyBase hämtar externa data.
PolyBase kan skicka en del av frågeberäkningen till Hadoop för att förbättra frågeprestandan. Den här åtgärden kallas predikat-pushdown. Om du vill aktivera det anger du alternativet Hadoop resource manager location i CREATE EXTERNAL DATA SOURCE.
Du kan skapa många externa tabeller som refererar till samma eller olika externa datakällor.
Begränsningar och begränsningar
Eftersom data för en extern tabell inte styrs direkt av installationen kan de ändras eller tas bort när som helst av en extern process. Därför är frågeresultaten mot en extern tabell inte garanterade att de är deterministiska. Samma fråga kan returnera olika resultat varje gång den körs mot en extern tabell. På samma sätt kan en fråga misslyckas om externa data flyttas eller tas bort.
Du kan skapa flera externa tabeller som varje referens till olika externa datakällor. Om du samtidigt kör frågor mot olika Hadoop-datakällor måste varje Hadoop-källa använda samma serverkonfigurationsinställning för hadoop-anslutning. Du kan till exempel inte köra en fråga samtidigt mot ett Cloudera Hadoop-kluster och ett Hortonworks Hadoop-kluster eftersom dessa använder olika konfigurationsinställningar. Konfigurationsinställningar och kombinationer som stöds finns i PolyBase-anslutningskonfiguration.
Endast dessa DDL-instruktioner (Data Definition Language) tillåts i externa tabeller:
- SKAPA TABELL OCH TA BORT TABELL
- SKAPA STATISTIK OCH TA BORT STATISTIK
- SKAPA VY OCH SLÄPP VY
Konstruktioner och åtgärder stöds inte:
- Standardvillkoret för externa tabellkolumner
- DML-åtgärder (Data Manipulation Language) för borttagning, infogning och uppdatering
- dynamisk datamaskering på externa tabellkolumner
Frågebegränsningar
PolyBase kan använda högst 33 000 filer per mapp när 32 samtidiga PolyBase-frågor körs. Det här maximala antalet inkluderar både filer och undermappar i varje HDFS-mapp. Om graden av samtidighet är mindre än 32 kan en användare köra PolyBase-frågor mot mappar i HDFS som innehåller mer än 33 000 filer. Vi rekommenderar att du håller externa filsökvägar korta och inte använder fler än 30 000 filer per HDFS-mapp. När för många filer refereras kan ett JVM-undantag (Java Virtual Machine) uppstå.
Begränsningar för tabellbredd
PolyBase i SQL Server 2016 har en radbreddsgräns på 32 KB baserat på den maximala storleken på en enda giltig rad per tabelldefinition. Om summan av kolumnschemat är större än 32 KB kan PolyBase inte köra frågor mot data.
I Azure Synapse Analytics har den här begränsningen höjts till 1 MB.
Begränsningar för datatyp
Följande datatyper kan inte användas i externa PolyBase-tabeller:
- geografi
- geometri
- hierarchyid
- bild
- text
- ntext
- XML-
- Alla användardefinierade typer
Låsning
Delat lås på OBJEKTET SCHEMARESOLUTION.
Säkerhet
Datafilerna för en extern tabell lagras i Hadoop eller Azure Blob Storage. Dessa datafiler skapas och hanteras av dina egna processer. Det är ditt ansvar att hantera säkerheten för externa data.
Exempel
A. Ansluta HDFS-data till Analytics Platform System-data
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Importera raddata från HDFS till en systemtabell för distribuerad analysplattform
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. Importera raddata från HDFS till en replikerad analysplattformssystemtabell
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
Nästa steg
Läs mer om externa tabeller i Analytics Platform System i följande artiklar:
* Azure SQL Managed Instance *
Översikt: Azure SQL Managed Instance
Skapar en extern datatabell i Azure SQL Managed Instance. Fullständig information finns i Datavirtualisering med Azure SQL Managed Instance.
Datavirtualisering i Azure SQL Managed Instance ger åtkomst till externa data i olika filformat i Azure Data Lake Storage Gen2 eller Azure Blob Storage, och för att köra frågor mot dem med T-SQL-instruktioner kombinerar du även data med lokalt lagrade relationsdata med hjälp av kopplingar.
Se även CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Syntax
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argument
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Tabellens namn i en till tre delar som ska skapas. För en extern tabell är det bara tabellmetadata tillsammans med grundläggande statistik om filen eller mappen som refereras till i Azure Data Lake eller Azure Blob Storage. Inga faktiska data flyttas eller lagras när externa tabeller skapas.
Viktig
Om drivrutinen för den externa datakällan har stöd för ett namn i tre delar rekommenderar vi starkt att du anger namnet i tre delar.
<column_definition> [ ,...n ]
SKAPA EXTERN TABELL har stöd för möjligheten att konfigurera kolumnnamn, datatyp, nullbarhet och sortering. Du kan inte använda STANDARDVILLKORet för externa tabeller.
Kolumndefinitionerna, inklusive datatyperna och antalet kolumner, måste matcha data i de externa filerna. Om det uppstår ett matchningsfel avvisas filraderna när du frågar efter faktiska data.
LOCATION = 'folder_or_filepath'
Anger mappen eller filsökvägen och filnamnet för faktiska data i Azure Data Lake eller Azure Blob Storage. Platsen börjar från rotmappen. Rotmappen är den dataplats som anges i den externa datakällan.
CREATE EXTERNAL TABLE skapar inte sökvägen och mappen.
Om du anger PLATS som en mapp hämtar frågan från Azure SQL Managed Instance som väljer från den externa tabellen filer från mappen men inte alla dess undermappar.
Azure SQL Managed Instance kan inte hitta filer i undermappar eller dolda mappar. Det returnerar inte heller filer som filnamnet börjar med en understrykning (_) eller en punkt (.).
I följande bildexempel returnerar en fråga rader från LOCATION='/webdata/'om mydata.txt. Den returnerar inte mydata2.txt eftersom den finns i en undermapp, den returnerar inte mydata3.txt eftersom den finns i en dold mapp och den inte returnerar _hidden.txt eftersom det är en dold fil.
DATA_SOURCE = external_data_source_name
Anger namnet på den externa datakälla som innehåller platsen för externa data. Den här platsen finns i Azure Data Lake. Om du vill skapa en extern datakälla använder du CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Anger namnet på det externa filformatobjektet som lagrar filtypen och komprimeringsmetoden för externa data. Om du vill skapa ett externt filformat använder du CREATE EXTERNAL FILE FORMAT.
Behörigheter
Kräver följande användarbehörigheter:
- CREATE TABLE
- ÄNDRA SCHEMA
- ÄNDRA ALLA EXTERNA DATAKÄLLOR
- ÄNDRA ALLA EXTERNA FILFORMAT
Not
BEHÖRIGHETER FÖR KONTROLLDATABAS krävs för att endast skapa HUVUDNYCKELN, DATABASOMFATTNINGSAUTENTISERINGSUPPGIFTER OCH EXTERN DATAKÄLLA
Observera att inloggningen som skapar den externa datakällan måste ha behörighet att läsa och skriva till den externa datakällan i Hadoop eller Azure Blob Storage.
Viktig
Behörigheten ALTER ANY EXTERNAL DATA SOURCE ger alla huvudnamn möjlighet att skapa och ändra alla externa datakällans objekt, och därför ger det också möjlighet att komma åt alla databasomfattningsautentiseringsuppgifter i databasen. Den här behörigheten måste betraktas som högprivilegierad och måste därför endast beviljas betrodda huvudnamn i systemet.
Anmärkningar
I ad hoc-frågescenarier, till exempel SELECT FROM EXTERNAL TABLE, lagras raderna som hämtas från den externa datakällan i en tillfällig tabell. När frågan har slutförts tas raderna bort och den tillfälliga tabellen tas bort. Inga permanenta data lagras i SQL-tabeller.
I importscenariot, till exempel SELECT INTO FROM EXTERNAL TABLE, lagras däremot de rader som hämtas från den externa datakällan som permanenta data i SQL-tabellen. Den nya tabellen skapas under frågekörningen när externa data hämtas.
För närvarande är datavirtualisering med Azure SQL Managed Instance skrivskyddad.
Du kan skapa många externa tabeller som refererar till samma eller olika externa datakällor.
Begränsningar och begränsningar
Eftersom data för en extern tabell inte kontrolleras direkt av Azure SQL Managed Instance kan de ändras eller tas bort när som helst av en extern process. Därför är frågeresultaten mot en extern tabell inte garanterade att de är deterministiska. Samma fråga kan returnera olika resultat varje gång den körs mot en extern tabell. På samma sätt kan en fråga misslyckas om externa data flyttas eller tas bort.
Du kan skapa flera externa tabeller som varje referens till olika externa datakällor.
Endast dessa DDL-instruktioner (Data Definition Language) tillåts i externa tabeller:
- SKAPA TABELL OCH TA BORT TABELL
- SKAPA STATISTIK OCH TA BORT STATISTIK
- SKAPA VY OCH SLÄPP VY
Konstruktioner och åtgärder stöds inte:
- Standardvillkoret för externa tabellkolumner
- DML-åtgärder (Data Manipulation Language) för borttagning, infogning och uppdatering
Begränsningar för tabellbredd
Radbreddsgränsen på 1 MB baseras på den maximala storleken på en enda giltig rad per tabelldefinition. Om summan av kolumnschemat är större än 1 MB misslyckas datavirtualiseringsfrågor.
Begränsningar för datatyp
Följande datatyper kan inte användas i externa tabeller i Azure SQL Managed Instance:
- geografi
- geometri
- hierarchyid
- bild
- text
- ntext
- XML-
- json
- Alla användardefinierade typer
Låsning
Delat lås på OBJEKTET SCHEMARESOLUTION.
Exempel
A. Fråga externa data från Azure SQL Managed Instance med en extern tabell
Fler exempel finns i Skapa extern datakälla eller se Datavirtualisering med Azure SQL Managed Instance.
Skapa databasens huvudnyckel om den inte finns.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOSkapa databasens begränsade autentiseringsuppgifter med hjälp av en SAS-token. Du kan också använda en hanterad identitet.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GOSkapa den externa datakällan med hjälp av autentiseringsuppgifterna.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOSkapa ett EXTERNT FILFORMAT och en EXTERN TABELL för att fråga data som om det vore en lokal tabell.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
Nästa steg
Läs mer om externa tabeller och relaterade begrepp i följande artiklar: