DBCC-SHOW_STATISTICS (Transact-SQL)
gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() SQL-analysslutpunkt i Microsoft Fabric
SQL-analysslutpunkt i Microsoft Fabric![]() Warehouse i Microsoft Fabric
Warehouse i Microsoft Fabric
Visar aktuell frågeoptimeringsstatistik för en tabell eller indexerad vy. Frågeoptimeraren använder statistik för att uppskatta kardinaliteten eller antalet rader i frågeresultatet, vilket gör att frågeoptimeraren kan skapa en frågeplan av hög kvalitet. Frågeoptimeraren kan till exempel använda kardinalitetsuppskattningar för att välja operatorn indexsökning i stället för indexgenomsökningsoperatorn i frågeplanen, vilket förbättrar frågeprestandan genom att undvika en resursintensiv indexgenomsökning.
Frågeoptimeraren lagrar statistik för en tabell eller indexerad vy i ett statistikobjekt. För en tabell skapas statistikobjektet i antingen ett index eller en lista med tabellkolumner. Statistikobjektet innehåller en rubrik med metadata om statistiken, ett histogram med fördelningen av värden i den första nyckelkolumnen i statistikobjektet och en densitetsvektor för att mäta korrelation mellan kolumner. Databasmotorn kan beräkna kardinalitetsuppskattningar med någon av data i statistikobjektet. Mer information finns i Statistics and Cardinality Estimation (SQL Server).
DBCC SHOW_STATISTICS visar huvudet, histogrammet och densitetsvektorn baserat på data som lagras i statistikobjektet. Med syntaxen kan du ange en tabell eller indexerad vy tillsammans med ett målindexnamn, statistiknamn eller kolumnnamn.
Viktiga uppdateringar i tidigare versioner av SQL Server:
Från och med SQL Server 2012 (11.x) Service Pack 1 är den sys.dm_db_stats_properties dynamiska hanteringsvyn tillgänglig för programmatiskt hämtning av rubrikinformation som finns i statistikobjektet för icke-inkrementell statistik.
Från och med SQL Server 2014 (12.x) Service Pack 2 och SQL Server 2012 (11.x) Service Pack 1 är den sys.dm_db_incremental_stats_properties dynamiska hanteringsvyn tillgänglig för att programmatiskt hämta rubrikinformation som finns i statistikobjektet för inkrementell statistik.
Från och med SQL Server 2016 (13.x) Service Pack 1 CU 2 är den sys.dm_db_stats_histogram dynamiska hanteringsvyn tillgänglig för att programmatiskt hämta histograminformation som finns i statistikobjektet.
-
Den här syntaxen stöds inte av en serverlös SQL-pool i Azure Synapse Analytics.
Mer information om statistik i Microsoft Fabric finns i Statistics.
![]() Transact-SQL syntaxkonventioner
Transact-SQL syntaxkonventioner
Syntax
Syntax för SQL Server och Azure SQL Database:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Syntax för Azure Synapse Analytics, Analytics Platform System (PDW) och Microsoft Fabric:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
Argument
table_or_indexed_view_name
Namnet på tabellen eller den indexerade vy som statistikinformationen ska visas för.
table_name
Namnet på tabellen som innehåller den statistik som ska visas. Tabellen får inte vara en extern tabell.
mål
Namnet på indexet, statistiken eller kolumnen som statistikinformationen ska visas för. mål omges av hakparenteser, enkla citattecken, dubbla citattecken eller inga citattecken.
- Om mål är ett namn på ett befintligt index eller en befintlig statistik i en tabell eller indexerad vy returneras statistikinformationen om det här målet.
- Om mål är namnet på en befintlig kolumn och det finns ett automatiskt skapat statistikobjekt i den här kolumnen returneras information om den automatiskt skapade statistiken.
Om det inte finns någon statistik som skapas automatiskt för ett kolumnmål returneras felmeddelandet 2767.
I Azure Synapse Analytics and Analytics Platform System (PDW) kan mål inte vara ett kolumnnamn.
I Warehouse i Microsoft Fabric kan mål antingen vara namnet på en histogramstatistik med en kolumn eller en kolumn. Om ett kolumnnamn används för målreturnerar det här kommandot endast distributionsinformation om den automatiskt genererade histogramstatistiken. Om du vill visa information om en histogramstatistik som skapats manuellt anger du statistiknamnet som mål.
NO_INFOMSGS
Undertrycker alla informationsmeddelanden som har allvarlighetsgrad mellan 0 och 10.
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
Om du anger ett eller flera av dessa alternativ begränsas de resultatuppsättningar som returneras av -instruktionen till det angivna alternativet eller alternativen. Om inga alternativ anges returneras all statistikinformation.
STATS_STREAM identifieras endast i informationssyfte. Stöds inte. Framtida kompatibilitet garanteras inte.
Resultatuppsättning
I följande tabell beskrivs de kolumner som returneras i resultatuppsättningen när STAT_HEADER anges.
| Kolumnnamn | Beskrivning |
|---|---|
| Namn | Namnet på statistikobjektet. |
| Uppdaterad | Datum och tid då statistiken senast uppdaterades. Funktionen STATS_DATE är ett alternativt sätt att hämta den här informationen. Mer information finns i avsnittet Kommentarer på den här sidan. |
| Rader | Totalt antal rader i tabellen eller indexerad vy när statistiken senast uppdaterades. Om statistiken filtreras eller motsvarar ett filtrerat index kan antalet rader vara mindre än antalet rader i tabellen. Mer information finns i Statistics. |
| Samplade rader | Totalt antal rader som samplas för statistikberäkningar. Om rader som samplas < rader är det visade histogrammet och densitetsresultatet uppskattningar baserat på de samplade raderna. |
| Trappsteg | Antal steg i histogrammet. Varje steg sträcker sig över ett intervall med kolumnvärden följt av ett kolumnvärde med övre gräns. Histogramstegen definieras i den första nyckelkolumnen i statistiken. Det maximala antalet steg är 200. |
| Täthet | Beräknas som 1/distinkta värden för alla värden i den första nyckelkolumnen i statistikobjektet, exklusive histogramets gränsvärden. Det här densitetsvärdet används inte av frågeoptimeraren och visas för bakåtkompatibilitet med versioner före SQL Server 2008 (10.0.x). |
| Genomsnittlig nyckellängd | Genomsnittligt antal byte per värde för alla nyckelkolumner i statistikobjektet. |
| Strängindex | Ja anger att statistikobjektet innehåller strängsammanfattningsstatistik för att förbättra kardinalitetsuppskattningarna för frågepredikat som använder LIKE-operatorn. till exempel WHERE ProductName LIKE '%Bike'. Sammanfattningsstatistik för strängar lagras separat från histogrammet och skapas i den första nyckelkolumnen i statistikobjektet när det är av typen tecken, varchar, nchar, nvarchar, varchar(max), nvarchar(max), texteller ntext.. |
| Filteruttryck | Predikat för delmängden av tabellrader som ingår i statistikobjektet.
NULL = icke-filtrerad statistik. Mer information om filtrerade predikat finns i Skapa filtrerade index. Mer information om filtrerad statistik finns i Statistics. |
| Ofiltrerade rader | Totalt antal rader i tabellen innan filteruttrycket tillämpas. Om filteruttrycket är NULLär Unfiltered Rows lika med Rows. |
| Beständiga exempelprocent | Sparad exempelprocent som används för statistikuppdateringar som inte uttryckligen anger en samplingsprocent. Om värdet är noll anges ingen bevarad exempelprocentsats för den här statistiken. gäller för: SQL Server 2016 (13.x) Service Pack 1 CU 4 |
I följande tabell beskrivs de kolumner som returneras i resultatuppsättningen när DENSITY_VECTOR anges.
| Kolumnnamn | Beskrivning |
|---|---|
| All densitet | Densiteten är 1/distinkta värden. Resultat visar densitet för varje prefix för kolumner i statistikobjektet, en rad per densitet. Ett distinkt värde är en distinkt lista över kolumnvärdena per rad och per kolumnprefix. Om statistikobjektet till exempel innehåller nyckelkolumner (A, B, C), rapporterar resultaten densiteten för de distinkta listorna med värden i var och en av dessa kolumnprefix: (A), (A,B) och (A, B, C). Med prefixet (A, B, C) är var och en av dessa listor en distinkt värdelista: (3, 5, 6), (4, 4, 6), (4, 5, 6), (4, 5, 7). Med prefixet (A, B) har samma kolumnvärden dessa distinkta värdelistor: (3, 5), (4, 4) och (4, 5) |
| Genomsnittlig längd | Genomsnittlig längd, i byte, för att lagra en lista över kolumnvärdena för kolumnprefixet. Om till exempel värdena i listan (3, 5, 6) var och en kräver 4 byte är längden 12 byte. |
| Kolumner | Namn på kolumner i prefixet som All densitet och Genomsnittlig längd visas för. |
I följande tabell beskrivs de kolumner som returneras i resultatuppsättningen när histogramalternativet har angetts.
| Kolumnnamn | Beskrivning |
|---|---|
| RANGE_HI_KEY | Kolumnvärde med övre gräns för ett histogramsteg. Kolumnvärdet kallas även för ett nyckelvärde. |
| RANGE_ROWS | Uppskattat antal rader vars kolumnvärde faller inom ett histogramsteg, exklusive den övre gränsen. |
| EQ_ROWS | Uppskattat antal rader vars kolumnvärde är lika med histogramstegets övre gräns. |
| DISTINCT_RANGE_ROWS | Uppskattat antal rader med ett distinkt kolumnvärde i ett histogramsteg, exklusive den övre gränsen. |
| AVG_RANGE_ROWS | Genomsnittligt antal rader med duplicerade kolumnvärden i ett histogramsteg, exklusive den övre gränsen. När DISTINCT_RANGE_ROWS är större än 0 beräknas AVG_RANGE_ROWS genom att RANGE_ROWS divideras med DISTINCT_RANGE_ROWS. När DISTINCT_RANGE_ROWS är 0 returnerar AVG_RANGE_ROWS 1 för histogramsteget. |
Anmärkningar
Uppdateringsdatumet för statistik lagras i -statistikblobobjektet tillsammans med histogrammet och densitetsvektor, inte i metadata. När inga data läss för att generera statistikdata skapas inte statistikbloben, datumet är inte tillgängligt och uppdaterade kolumnen är NULL. Detta gäller för filtrerad statistik som predikatet inte returnerar några rader för, eller för nya tomma tabeller.
Histogram
Ett histogram mäter förekomstens frekvens för varje distinkt värde i en datauppsättning. Frågeoptimeraren beräknar ett histogram på kolumnvärdena i den första nyckelkolumnen i statistikobjektet, väljer kolumnvärdena genom att statistiskt sampela raderna eller genom att utföra en fullständig genomsökning av alla rader i tabellen eller vyn. Om histogrammet skapas från en samplad uppsättning rader är de lagrade summorna för antalet rader och antalet distinkta värden uppskattningar och behöver inte vara heltal.
För att skapa histogrammet sorterar frågeoptimeraren kolumnvärdena, beräknar antalet värden som matchar varje distinkt kolumnvärde och aggregerar sedan kolumnvärdena i högst 200 sammanhängande histogramsteg. Varje steg innehåller ett intervall med kolumnvärden följt av ett kolumnvärde med övre gräns. Intervallet innehåller alla möjliga kolumnvärden mellan gränsvärdena, exklusive själva gränsvärdena. Det lägsta av de sorterade kolumnvärdena är det övre gränsvärdet för det första histogramsteget.
Följande diagram visar ett histogram med sex steg. Området till vänster om det första övre gränsvärdet är det första steget.

För varje histogramsteg:
- Fet linje representerar det övre gränsvärdet (RANGE_HI_KEY) och antalet gånger det inträffar (EQ_ROWS)
- Heldragen yta till vänster om RANGE_HI_KEY representerar kolumnvärdenas intervall och det genomsnittliga antalet gånger varje kolumnvärde inträffar (AVG_RANGE_ROWS). Det AVG_RANGE_ROWS för det första histogramsteget är alltid 0.
- Streckade linjer representerar de samplade värden som används för att uppskatta det totala antalet distinkta värden i intervallet (DISTINCT_RANGE_ROWS) och det totala antalet värden i intervallet (RANGE_ROWS). Frågeoptimeraren använder RANGE_ROWS och DISTINCT_RANGE_ROWS för att beräkna AVG_RANGE_ROWS och lagrar inte de samplade värdena.
Frågeoptimeraren definierar histogramstegen enligt deras statistiska signifikans. Den använder en algoritm för maximal skillnad för att minimera antalet steg i histogrammet samtidigt som skillnaden mellan gränsvärdena maximeras. Det maximala antalet steg är 200. Antalet histogramsteg kan vara färre än antalet distinkta värden, även för kolumner med färre än 200 gränspunkter. En kolumn med 100 distinkta värden kan till exempel ha ett histogram med färre än 100 gränspunkter.
Densitetsvektor
Frågeoptimeraren använder tätheter för att förbättra kardinalitetsuppskattningar för frågor som returnerar flera kolumner från samma tabell eller indexerade vy. Densitetsvektorn innehåller en densitet för varje prefix för kolumner i statistikobjektet. Om ett statistikobjekt till exempel har nyckelkolumnerna CustomerId, ItemId och Priceberäknas densiteten på vart och ett av följande kolumnprefix.
| Kolumnprefix | Densitet beräknad på |
|---|---|
(CustomerId) |
Rader med matchande värden för CustomerId |
(CustomerId, ItemId) |
Rader med matchande värden för CustomerId och ItemId |
(CustomerId, ItemId, Price) |
Rader med matchande värden för CustomerId, ItemIdoch Price |
Begränsningar
DBCC SHOW_STATISTICS tillhandahåller inte statistik för rumsliga index eller minnesoptimerade kolumnlagringsindex.
Behörigheter för SQL Server och SQL Database
För att kunna visa statistikobjektet måste användaren ha behörigheten SELECT i tabellen.
Följande krav finns för att SELECT-behörigheter ska vara tillräckliga för att köra kommandot:
- Användare måste ha behörighet för alla kolumner i statistikobjektet
- Användare måste ha behörighet för alla kolumner i ett filtervillkor (om det finns någon)
- Tabellen kan inte ha en säkerhetsprincip på radnivå.
- Om någon av kolumnerna i ett statistikobjekt maskeras med regler för dynamisk datamaskering måste användaren, förutom behörigheten
SELECT, ha behörighetenUNMASKeller vara medlem i den db_ddladmin rollen.
I versioner före SQL Server 2012 (11.x) Service Pack 1 måste användaren äga tabellen eller vara medlem i sysadmin fast serverroll, db_owner fast databasroll eller db_ddladmin fast databasroll.
Not
Använd Spårningsflagga 9485 om du vill ändra beteendet tillbaka till före SQL Server 2012 (11.x) Service Pack 1-beteendet.
Behörigheter för Azure Synapse Analytics and Analytics Platform System (PDW)
DBCC SHOW_STATISTICS kräver SELECT behörighet i tabellen eller medlemskapet i sysadmin fast serverroll, db_owner fast databasroll eller db_ddladmin fast databasroll.
Begränsningar och begränsningar för Azure Synapse Analytics and Analytics Platform System (PDW)
DBCC SHOW_STATISTICS visar statistik som lagras i Shell-databasen på nodnivå för kontroll. Den visar inte statistik som skapas automatiskt av SQL Server på beräkningsnoderna.
DBCC SHOW_STATISTICS stöds inte i externa tabeller.
I Microsoft Fabric visar DBCC SHOW_STATISTICS bara resultat för histogramstatistik, inte ACE-* statistik.
Exempel: SQL Server och Azure SQL Database
A. Returnera all statistikinformation
I följande exempel visas all statistikinformation för AK_Address_rowguid index för tabellen Person.Address i databasen AdventureWorks2022.
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. Ange alternativet HISTOGRAM
Detta begränsar den statistikinformation som visas för Customer_LastName till HISTOGRAM-data.
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
Exempel: Azure Synapse Analytics and Analytics Platform System (PDW)
C. Visa innehållet i ett statistikobjekt
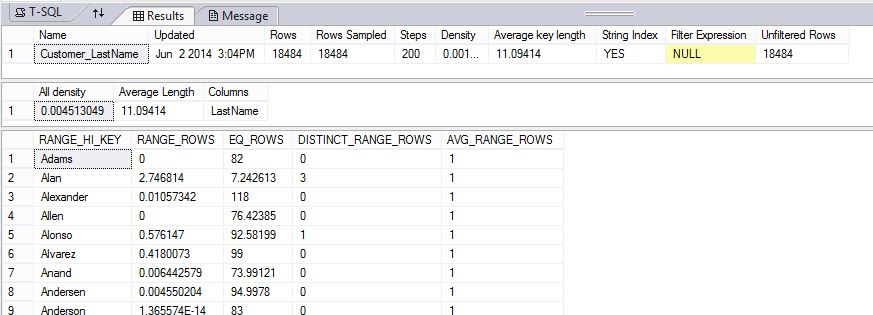
Följande exempel skapar ett statistikobjekt och visar sedan innehållet i Customer_LastName-statistiken i tabellen DimCustomer i AdventureWorksPDW2022 exempeldatabas.
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
Resultaten visar rubriken, densitetsvektorn och en del av histogrammet.
Se även
- Statistik
- Statistik i Microsoft Fabric
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)