Columnstore-index: Översikt
gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() SQL-databas i Microsoft Fabric
SQL-databas i Microsoft Fabric
Kolumnlagringsindex är standard för att lagra och söka i stora datalagers faktatabeller. Det här indexet använder kolumnbaserad datalagring och frågebearbetning för att uppnå vinster upp till 10 gånger frågeprestandan i ditt informationslager jämfört med traditionell radorienterad lagring. Du kan också uppnå vinster med upp till 10 gånger så hög datakomprimering jämfört med den okomprimerade datastorleken. Från och med SQL Server 2016 (13.x) SP1 möjliggör kolumnlagringsindex operationell analys: möjliggör att köra högpresterande realtidsanalyser på en transaktionell arbetsbelastning.
Lär dig mer om ett relaterat scenario:
Vad är ett columnstore-index?
Ett kolumnlagringsindex är en teknik för att lagra, hämta och hantera data med hjälp av ett kolumndataformat som kallas columnstore.
Viktiga termer och begrepp
Följande viktiga termer och begrepp är associerade med kolumnlagringsindex.
Kolumnarkiv
Ett kolumnlager är data som är logiskt ordnade som en tabell med rader och kolumner och som lagras fysiskt i ett kolumnmässigt dataformat.
Radlagring
Ett radlager är data som är logiskt ordnade som en tabell med rader och kolumner och som lagras fysiskt i ett radvist dataformat. Det här formatet är det traditionella sättet att lagra relationstabelldata. I SQL Server refererar radarkiv till en tabell där det underliggande datalagringsformatet är en heap, ett klustrat index eller en minnesoptimerad tabell.
Not
I diskussioner om kolumnlagringsindex används termerna rowstore och columnstore för att framhäva formatet för datalagringen.
Radgrupp
En radgrupp är en grupp rader som komprimeras till columnstore-format samtidigt. En radgrupp innehåller vanligtvis det maximala antalet rader per radgrupp, vilket är 1 048 576 rader.
För höga prestanda och höga komprimeringshastigheter segmenterar kolumnlagringsindex tabellen i radgrupper och komprimerar sedan varje radgrupp på ett kolumnmässigt sätt. Antalet rader i radgruppen måste vara tillräckligt stort för att förbättra komprimeringshastigheten och tillräckligt liten för att dra nytta av minnesinterna åtgärder.
En radgrupp där all data har tagits bort övergår från KOMPRIMERAD till TOMBSTONE och tas senare bort av en bakgrundsprocess som heter tuple-mover. Mer information om status för radgrupper finns i sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Tips
Om du har för många små radgrupper minskar indexkvaliteten för kolumnlagring. Fram till SQL Server 2017 (14.x) krävs en omorganiseringsåtgärd för att sammanfoga mindre KOMPRIMERADE radgrupper, enligt en intern tröskelprincip som bestämmer hur du tar bort borttagna rader och kombinerar komprimerade radgrupper.
Från och med SQL Server 2019 (15.x) fungerar en bakgrundssammanslagningsaktivitet också för att sammanfoga KOMPRIMERADE radgrupper där ett stort antal rader har tagits bort.
När du har sammanfogat mindre radgrupper bör indexkvaliteten förbättras.
Obs
Från och med SQL Server 2019 (15.x), Azure SQL Database, Azure SQL Managed Instance och dedikerade SQL-pooler i Azure Synapse Analytics, får tuppel-mover hjälp av en bakgrundssammanslagningsuppgift som automatiskt komprimerar mindre open delta-radgrupper som har funnits under en viss tid, vilket bestäms av ett internt tröskelvärde, eller sammanfogar komprimerade radgrupper där ett stort antal rader har tagits bort. Detta förbättrar kolumnlagringsindexets kvalitet över tid.
Kolumnsegment
Ett kolumnsegment är en kolumn med data inifrån radgruppen.
- Varje radgrupp innehåller ett kolumnsegment för varje kolumn i tabellen.
- Varje kolumnsegment komprimeras tillsammans och lagras på fysiska medier.
- Det finns metadata med varje segment för att möjliggöra snabb eliminering av segment utan att läsa dem.
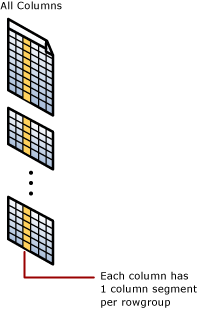
Grupperat kolumnlagringsindex
Ett grupperat columnstore-index är den fysiska lagringen för hela tabellen.
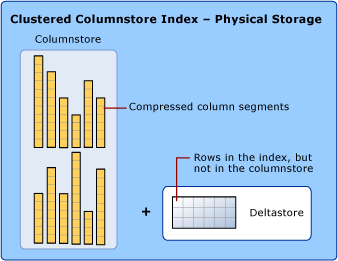
För att minska fragmenteringen av kolumnsegmenten och förbättra prestandan kan kolumnlagringsindexet tillfälligt lagra vissa data i ett grupperat index som kallas deltastore- och en B-trädlista med ID:n för borttagna rader. Deltastore-åtgärderna hanteras i bakgrunden. För att returnera rätt frågeresultat kombinerar det klustrade kolumnlagringsindexet frågeresultat från både kolumnarkivet och deltaarkivet.
Not
I dokumentationen används termen B-träd vanligtvis som referens till index. I radlagringsindex implementerar databasmotorn ett B+-träd. Detta gäller inte för kolumnlagringsindex eller index i minnesoptimerade tabeller. Mer information finns i arkitekturen och designguiden för SQL Server och Azure SQL-index.
Delta radgrupp
En deltaradgrupp är ett grupperat B-trädindex som endast används med kolumnlagringsindex. Det förbättrar kolumnlagringskomprimering och prestanda genom att lagra rader tills antalet rader når ett tröskelvärde (1 048 576 rader) och sedan flyttas till kolumnarkivet.
När en deltaradgrupp når det maximala antalet rader övergår den från tillståndet ÖPPNA till STÄNGD. En bakgrundsprocess med namnet tuple-mover söker efter stängda radgrupper. Om processen hittar en stängd radgrupp komprimerar den deltaradgruppen och lagrar den i kolumnarkivet som en KOMPRIMERAD radgrupp.
När en deltaradgrupp har komprimerats övergår den befintliga deltaradgruppen till TOMBSTONE-status för att senare tas bort av tuple-movern när det inte finns någon referens till den.
Mer information om status för radgrupper finns i sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Not
Från och med SQL Server 2019 (15.x) får tuppel-mover hjälp av en bakgrundssammanslagningsaktivitet som automatiskt komprimerar mindre OPEN delta-radgrupper som har funnits under en tid enligt ett internt tröskelvärde, eller sammanfogar KOMPRIMERADE radgrupper där ett stort antal rader har tagits bort. Detta förbättrar kolumnlagringsindexets kvalitet över tid.
Deltastore
Ett kolumnlagringsindex kan ha mer än en deltaradgrupp. Alla deltaradgrupper kallas tillsammans deltaarkivet.
Under en stor bulk-inläsning går de flesta raderna direkt till kolumnarkivet utan att gå igenom deltaarkivet. Vissa rader i slutet av datamassinläsningen kan vara för få till antalet för att uppfylla den minsta storleken på en radgrupp, vilket är 102 400 rader. Därför går de sista raderna till deltalagret i stället för kolumnlagret. För små bulkbelastningar med färre än 102 400 rader går alla rader direkt till deltalagret.
Icke-grupperat columnstore-index
Ett icke-grupperat columnstore-index och ett grupperat columnstore-index fungerar på samma sätt. Skillnaden är att ett icke-grupperat index är ett sekundärt index som skapas i en radlagringstabell, men ett grupperat kolumnlagringsindex är den primära lagringen för hela tabellen.
Det icke-klustrerade indexet innehåller en kopia av en del av eller alla raderna och kolumnerna i den underliggande tabellen. Indexet definieras som en eller flera kolumner i tabellen och har ett valfritt villkor som filtrerar raderna.
Ett icke-grupperat columnstore-index möjliggör driftanalys i realtid där OLTP-arbetsbelastningen använder det underliggande klustrade indexet medan analys körs samtidigt på kolumnlagringsindexet. För mer information, se Kom igång med columnstore för driftanalys i realtid.
Körning av batchläge
Körning av batchläge är en frågebearbetningsmetod som används för att bearbeta flera rader tillsammans. Körning av batchläge är nära integrerat med och optimerat runt kolumnlagringsformatet. Körning av batchläge kallas ibland vektorbaserad eller vektoriserad körning. Frågor på columnstore-index använder körning av batchläge, vilket förbättrar frågeprestandan vanligtvis med två till fyra gånger. Mer information finns i arkitekturguiden Frågebearbetning.
Varför ska jag använda ett columnstore-index?
Ett kolumnlagringsindex kan ge en mycket hög nivå av datakomprimering, vanligtvis med 10 gånger, för att avsevärt minska lagringskostnaden för ditt informationslager. För analys erbjuder ett columnstore-index mer än tio gånger bättre prestanda jämfört med ett B-trädindex. Kolumnlagringsindex är det föredragna datalagringsformatet för datavaruhantering och analysarbetsuppgifter. Från och med SQL Server 2016 (13.x) kan du använda columnstore-index för realtidsanalys av din driftarbetsbelastning.
Orsaker till att kolumnlagringsindex är så snabba:
Kolumner lagrar värden från samma domän och har ofta liknande värden, vilket resulterar i höga komprimeringshastigheter. I/O-flaskhalsar i ditt system minimeras eller elimineras, och minnesanvändningen minskar avsevärt.
Hög kompressionsgrad förbättrar frågeprestanda genom att använda ett mindre minnesavtryck. Frågeprestanda kan i sin tur förbättras eftersom SQL Server kan utföra fler fråge- och dataåtgärder i minnet.
Batchkörning förbättrar frågeprestanda, vanligtvis med två till fyra gånger, genom att bearbeta flera rader tillsammans.
Frågor väljer ofta bara några kolumner från en tabell, vilket minskar det totala antalet I/O från det fysiska mediet.
När ska jag använda ett columnstore-index?
Rekommenderade användningsfall:
Använd ett grupperat kolumnlagringsindex för att lagra faktatabeller och stora dimensionstabeller för datalagerarbetsbelastningar. Den här metoden förbättrar frågeprestanda och datakomprimering med upp till 10 gånger. Mer information finns i Columnstore-indexer för datalager.
Använd ett icke-grupperat columnstore-index för att utföra analys i realtid på en OLTP-arbetsbelastning. För mer information, se Kom igång med columnstore för driftanalys i realtid.
Fler användningsscenarier för columnstore-index finns i Välj det bästa kolumnlagringsindexet för dina behov.
Hur väljer jag mellan ett radlagringsindex och ett kolumnlagringsindex?
Radlagringsindex presterar bäst på frågor som söker efter data, när du söker efter ett visst värde eller för frågor om ett litet värdeintervall. Använd radlagringsindex med transaktionsbelastningar eftersom de oftast kräver tabellsökningar i stället för tabellgenomsökningar.
Kolumnlagringsindex ger höga prestandavinster för analysfrågor som söker igenom stora mängder data, särskilt på stora tabeller. Använd columnstore-index för datalager- och analysarbetsbelastningar, särskilt i faktatabeller, eftersom de tenderar att kräva fullständiga tabellgenomsökningar i stället för tabellsökningar.
Ordnade grupperade kolumnlagringsindex förbättrar prestandan för frågor baserat på ordnade kolumnpredikat. Ordnade kolumnlagringsindex kan förbättra radgruppseliminering, vilket kan ge prestandaförbättringar genom att hoppa över radgrupper helt och hållet. Mer information finns i Prestandaoptimering med sorterade columnstore-index. Information om tillgänglighet för ordnat columnstore-index finns i Ordnad kolumnindextillgänglighet.
Kan jag kombinera radarkiv och kolumnarkiv i samma tabell?
Ja. Från och med SQL Server 2016 (13.x) kan du skapa ett uppdaterbart ickeklustrat kolumnstore-index på en radlagringstabell. Kolumnlagringsindexet lagrar en kopia av de valda kolumnerna, så du behöver extra utrymme för dessa data, men de valda data komprimeras i genomsnitt 10 gånger. Du kan köra analys på kolumnlagringsindexet och transaktionerna på radlagringsindexet samtidigt. Kolumnlagringen uppdateras när data ändras i radlagringstabellen, så båda indexen fungerar mot samma data.
Från och med SQL Server 2016 (13.x) kan du ha ett eller flera icke-klustrade radlagringsindex på ett kolumnlagringsindex och utföra effektiva tabellsökningar på den underliggande kolumnlagringen. Andra alternativ blir också tillgängliga. Du kan till exempel framtvinga en primärnyckelbegränsning med hjälp av en UNIK begränsning i radlagringstabellen. Eftersom ett icke-substantivt värde inte kan infogas i radlagringstabellen kan SQL Server inte infoga värdet i kolumnarkivet.
Ordnade kolumnlagringsindex
Genom att aktivera effektiv segmenteliminering ger ordnade kolumnlagringsindex snabbare prestanda genom att hoppa över stora mängder sorterade data som inte matchar frågepredikatet. Det kan ta längre tid att läsa in data i ett ordnat columnstore-index än i ett icke-ordnat index på grund av datasorteringsåtgärden, men med ordnade columnstore-index kan frågor köras snabbare efteråt.
- Mer information om prestandajustering av datalagerarbetsbelastningar i SQL Database Engine med ordnade kolumnlagringsindex finns i Prestandajustering med ordnade kolumnlagringsindex.
- Mer information om när du ska använda vilken typ av kolumnlagringsindex finns i Välj det bästa kolumnlagringsindexet för dina behov.
Ordnad tillgänglighet för columnstore-index
Först introducerad med ![]() SQL Server 2022 (16.x) finns ordnade kolumnlagringsindex tillgängliga på följande plattformar:
SQL Server 2022 (16.x) finns ordnade kolumnlagringsindex tillgängliga på följande plattformar:
| Plattform | Ordnade grupperade kolumnlagringsindex | Ordnade icke-klustrade kolumnlagringsindex |
|---|---|---|
| Azure SQL Database | Ja | Ja |
| Azure SQL Managed InstanceAUTD | Ja | Ja |
| Azure SQL Managed Instance2022 | Ja | Nej |
| SQL-databas i Microsoft Fabric | Ja1 | Ja |
| SQL Server 2022 (16.x) | Ja | Nej |
| Dedikerad SQL-pool i Azure Synapse Analytics | Ja | Nej |
AUTD gäller för Azure SQL Managed Instance som konfigurerats med Always-up-to-date uppdateringsprincipen.
2022 gäller för Azure SQL Managed Instance som konfigurerats med uppdateringsprincipen SQL Server 2022.
1I Fabric SQL-databasen speglas inte tabeller med grupperade kolumnlagringsindex till Fabric OneLake-.
Metadata
Alla kolumner i ett kolumnlagringsindex lagras i metadata som inkluderade kolumner. Kolumnlagringsindexet har inga nyckelkolumner.
Relaterade uppgifter
Alla relationstabeller, såvida du inte anger dem som ett grupperat kolumnlagringsindex, använder radlagring som underliggande dataformat.
CREATE TABLE skapar en radlagringstabell om du inte anger alternativet WITH CLUSTERED COLUMNSTORE INDEX.
När du skapar en tabell med instruktionen CREATE TABLE kan du skapa tabellen som ett kolumnarkiv genom att ange alternativet WITH CLUSTERED COLUMNSTORE INDEX. Om du redan har en radlagringstabell och vill konvertera den till ett kolumnarkiv kan du använda instruktionen CREATE COLUMNSTORE INDEX.
| Uppgift | Referensartiklar | Anteckningar |
|---|---|---|
| Skapa en tabell som en kolumnlagring. | CREATE TABLE (Transact-SQL) | Från och med SQL Server 2016 (13.x) kan du skapa tabellen som ett grupperat kolumnlagringsindex. Du behöver inte först skapa en radlagringstabell och sedan konvertera den till columnstore. |
| Skapa en minnesoptimerad tabell med ett kolumnlagringsindex. | CREATE TABLE (Transact-SQL) | Från och med SQL Server 2016 (13.x) kan du skapa en minnesoptimerad tabell med ett kolumnlagringsindex. Kolumnlagringsindexet kan också läggas till när tabellen har skapats med hjälp av syntaxen ALTER TABLE ADD INDEX. |
| Konvertera en radlagringstabell till kolumnlagring. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Konvertera en befintlig heap eller ett B-träd till ett kolumnstore. Exempel visar hur du hanterar befintliga index och även namnet på indexet när du utför den här konverteringen. |
| Konvertera en columnstore-tabell till ett radarkiv. | CREATE CLUSTERED INDEX (Transact-SQL) eller Konvertera en kolumnlagringstabell tillbaka till en radlagringshög | Vanligtvis är den här konverteringen inte nödvändig, men det kan finnas tillfällen då du behöver konvertera. Exempel visar hur du konverterar ett kolumnarkiv till ett heap- eller klustrat index. |
| Skapa ett kolumnlagringsindex i en radlagringstabell. | CREATE COLUMNSTORE INDEX (Transact-SQL) | En radlagringstabell kan ha ett kolumnlagringsindex. Från och med SQL Server 2016 (13.x) kan kolumnlagringsindexet ha ett filtrerat villkor. Exempel visar den grundläggande syntaxen. |
| Skapa högpresterande index för driftanalys. | Kom igång med columnstore för driftanalys i realtid | Beskriver hur du skapar kompletterande kolumnlagrings- och B-trädindex, så att OLTP-frågor använder B-trädindex och analysfrågor använder kolumnlagringsindex. |
| Skapa högpresterande kolumnlagringsindex för datalagerhantering. | Kolumnlagringsindex för datalager | Beskriver hur du använder B-trädindex i kolumnlagringstabeller för att skapa högpresterande datalagerfrågor. |
| Använd ett B-trädindex för att framtvinga en primärnyckelbegränsning för ett kolumnlagringsindex. | Kolumnlagringsindex för datalager | Visar hur du kombinerar B-träd- och kolumnlagringsindex för att framtvinga primärnyckelbegränsningar för kolumnlagringsindexet. |
| Ta bort ett kolumnlagringsindex. | DROP INDEX (Transact-SQL) | Genom att ta bort ett kolumnlagringsindex används standardsyntaxen DROP INDEX som B-trädindex använder. Om du tar bort ett grupperat columnstore-index konverteras columnstore-tabellen till en heap. |
| Ta bort en rad från ett columnstore-index. | TA BORT (Transact-SQL) | Använd DELETE (Transact-SQL) för att ta bort en rad. kolumnlagringsrad: SQL Server markerar raden som logiskt borttagen, men återtar inte den fysiska lagringen för raden förrän indexet återskapas. deltastore-rad: SQL Server tar bort raden logiskt och fysiskt. |
| Uppdatera en rad i columnstore-indexet. | UPDATE (Transact-SQL) | Använd UPDATE (Transact-SQL) för att uppdatera en rad. columnstore-rad: SQL Server markerar raden som logiskt borttagen och infogar sedan den uppdaterade raden i deltastore. deltastore-rad: SQL Server uppdaterar raden i deltastore. |
| Läs in data i ett columnstore-index. | Columnstore indexerar datainläsning | |
| Tvinga alla rader i deltalagret att flyttas till kolumnlagret. |
ALTER INDEX (Transact-SQL) ... REBUILDOptimera indexunderhåll för att förbättra frågeprestanda och minska resursförbrukningen |
ALTER INDEX med optionen REBUILD tvingar alla rader att placeras i kolumnlagret. |
| Defragmentera ett kolumnlagringsindex. | ALTER INDEX (Transact-SQL) |
ALTER INDEX ... REORGANIZE defragmenterar kolumnlagringsindex online. |
| Sammanfoga tabeller med columnstore-index. | MERGE (Transact-SQL) |
Relaterat innehåll
- Nyheter i kolumnlagringsindex
- Columnstore-index – Vägledning för datainläsning
- Columnstore-indexer – Frågeprestanda
- Kom igång med Columnstore för driftanalys i realtid
- Kolumnlagringsindex i datavaruhus
- Columnstore-indexer defragmentering
- arkitektur och designguide för SQL Server och Azure SQL-index
- Columnstore-indexarkitektur
- CREATE COLUMNSTORE INDEX (Transact-SQL)