Tabell- och radstorlek i minnesoptimerade tabeller
gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Före SQL Server 2016 (13.x) kunde datastorleken på rad för en minnesoptimerad tabell inte vara längre än 8 060 byte. Men från och med SQL Server 2016 (13.x) och i Azure SQL Database kan du skapa en minnesoptimerad tabell med flera stora kolumner (till exempel flera varbinary(8000) kolumner) och LOB-kolumner (d.v.s. varbinary(max), varchar(max), och nvarchar(max)) och utföra åtgärder på dem med hjälp av internt kompilerade Transact-SQL (T-SQL) moduler och tabelltyper.
Kolumner som inte får plats i radstorleksgränsen på 8 060 byte placeras utanför rad i en separat intern tabell. Varje kolumn utanför rad har en motsvarande intern tabell, som i sin tur har ett enda icke-grupperat index. Mer information om dessa interna tabeller som används för kolumner utanför rad finns i sys.memory_optimized_tables_internal_attributes.
Det finns vissa scenarier där det är användbart att beräkna storleken på raden och tabellen:
Hur mycket minne en tabell använder.
Mängden minne som används av tabellen kan inte beräknas exakt. Många faktorer påverkar mängden minne som används. Faktorer som sidbaserad minnesallokering, lokalitet, cachelagring och utfyllnad. Dessutom finns det flera versioner av rader som antingen har associerade aktiva transaktioner eller som väntar på skräpinsamling.
Den minsta storlek som krävs för data och index i tabellen anges av beräkningen för
<table size>, som beskrivs senare i den här artikeln.Att beräkna minnesanvändningen är i bästa fallet en uppskattning och du rekommenderas att inkludera kapacitetsplanering i dina distributionsplaner.
Datastorleken för en rad och passar den i storleksbegränsningen på 8 060 byte? Om du vill besvara dessa frågor använder du beräkningen för
<row body size>, som beskrivs senare i den här artikeln.
En minnesoptimerad tabell består av en samling rader och index som innehåller pekare till rader. Följande bild illustrerar en tabell med index och rader, som i sin tur har radrubriker och kroppar:

Beräkna tabellstorlek
Minnesintern storlek för en tabell, i byte, beräknas enligt följande:
<table size> = <size of index 1> + ... + <size of index n> + (<row size> * <row count>)
Storleken på ett hash-index korrigeras vid tidpunkten för att skapa tabellen och beror på det faktiska antalet bucketar. Den bucket_count som anges med indexdefinitionen avrundas upp till närmaste tvåpotens för att få det faktiska bucket-antalet. Om den angivna bucket_count till exempel är 100000 är det faktiska bucketantalet för indexet 131072.
<hash index size> = 8 * <actual bucket count>
Storleken på ett icke-grupperat index är i storleksordningen <row count> * <index key size>.
Radstorleken beräknas genom att sidhuvudet och brödtexten läggs till:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indexes>
Beräkna radkroppens storlek
Raderna i en minnesoptimerad tabell har följande komponenter:
Radrubriken innehåller den tidsstämpel som krävs för att implementera radversionshantering. Radrubriken innehåller också indexpekaren för att implementera radlänkningen i hash-bucketarna (beskrivs tidigare).
Radtexten innehåller faktiska kolumndata, som innehåller viss extra information som null-matrisen för null-kolumner och förskjutningsmatrisen för datatyper med variabel längd.
Följande bild illustrerar radstrukturen för en tabell som har två index:

Tidsstämplarna för start och slut anger den period då en viss radversion är giltig. Transaktioner som startar i det här intervallet kan se den här radversionen. Mer information finns i Transaktioner med Memory-Optimized-tabeller.
Indexpekarna pekar på nästa rad i kedjan som tillhör hash-hinken. Följande bild illustrerar strukturen i en tabell med två kolumner (namn, stad) och med två index, en på kolumnnamnet och en i kolumnstaden.
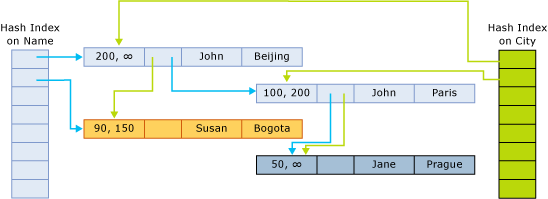
I den här bilden hashas namnen John och Jane till den första bucketen.
Susan har hashats till den andra hinken. Städerna Beijing och Bogota hashas till den första bucketen.
Paris och Prague hashas till den andra bucketen.
Kedjorna för hashindexet för namn är därför följande:
- Första hinken:
(John, Beijing);(John, Paris);(Jane, Prague) - Andra bucketen:
(Susan, Bogota)
Kedjorna för indexet på orten är följande:
- Första bucketen:
(John, Beijing),(Susan, Bogota) - Andra bucketen:
(John, Paris),(Jane, Prague)
En sluttidsstämpel ∞ (oändlighet) anger att detta är den aktuella giltiga versionen av raden. Raden har inte uppdaterats eller tagits bort sedan den här radversionen skrevs.
Under en tid som är större än 200innehåller tabellen följande rader:
| Namn | Stad |
|---|---|
| John | Peking |
| Jane | Prag |
Emellertid, alla aktiva transaktioner med starttid 100, se följande version av tabellen.
| Namn | Stad |
|---|---|
| John | Paris |
| Jane | Prag |
| Susan | Bogota |
Beräkningen av <row body size> beskrivs i följande tabell.
Det finns två olika beräkningar för radkroppsstorlek: beräknad storlek och den faktiska storleken:
Den beräknade storleken, som anges med beräknad radkroppsstorlek, används för att avgöra om radstorleksbegränsningen på 8 060 byte överskrids.
Den faktiska storleken, som anges med radkroppens storlek, är den faktiska lagringsstorleken för radkroppen i minnet och i kontrollpunktsfilerna.
Både beräknad radkroppsstorlek och faktiska radkroppsstorleken beräknas på samma sätt. Den enda skillnaden är beräkningen av storleken på (n)varchar(i) och varbinary(i) kolumner, vilket återspeglas längst ned i följande tabell. Den beräknade radkroppsstorleken använder den deklarerade storleken i som kolumnstorlek, medan den faktiska radkroppsstorleken använder den faktiska storleken på data.
I följande tabell beskrivs beräkningen av radkroppsstorleken, som anges som <actual row body size> = SUM(<size of shallow types>) + 2 + 2 * <number of deep type columns>.
| Sektion | Storlek | Kommentarer |
|---|---|---|
| Kolumn av grunt typ |
SUM(<size of shallow types>). Storleken i byte av de enskilda typerna är följande:bit: 1tinyint: 1smallint: 2int: 4verkliga: 4smalldatetime: 4smallmoney: 4bigint: 8datetime: 8datetime2: 8float: 8pengar: 8numeriska (precision <= 18): 8tid: 8numeriska(precision > 18): 16uniktid: 16 |
|
| Grund kolumnutfyllnad | Möjliga värden är:1 om det finns kolumner med djup typ och den totala datastorleken för kolumner av grund typ är ett udda tal.0 annars |
Djupa typer är typerna (var)binära och (n)(var)char. |
| Förskjutningsmatris för djuptypkolumner | Möjliga värden är:0 om det inte finns några kolumner av djuptyp2 + 2 * <number of deep type columns> annars |
Djupa typer är typerna (var)binära och (n)(var)char. |
| Null-matris |
<number of nullable columns> / 8 avrundat till hela byte. |
Matrisen har 1 bit per nullbar kolumn. Detta avrundas till fullständiga bytes. |
| Null-matrisutfyllnad | Möjliga värden är:1 om det finns kolumner av djuptyp och storleken på den NULL matrisen är ett udda antal byte.0 annars |
Djupa typer är typerna (var)binära och (n)(var)char. |
| Utfyllnad | Om det inte finns några kolumner av djuptyp: 0Om det finns djuptypskolumner läggs 0–7 byte utfyllnad till, baserat på den största justering som krävs av en ytlig kolumn. Varje ytlig kolumn kräver justering som är lika med dess storlek som tidigare dokumenterats, förutom att GUID-kolumner behöver justering på 1 byte (inte 16) och numeriska kolumner alltid behöver justeras på 8 byte (aldrig 16). Det största justeringskravet bland alla grunda kolumner används. 0–7 bytes utfyllnad läggs till på ett sådant sätt att den totala storleken hittills (utan kolumner av djuptyp) är en multipel av den nödvändiga justeringen. |
Djupa typer är typerna (var)binära och (n)(var)char. |
| Kolumner av djup typ med fast längd | SUM(<size of fixed length deep type columns>)Storleken på varje kolumn är följande: i för char(i) och binary(i).2 * i för nchar(i) |
Kolumner av djuptyp med fast längd är kolumner av typen char(i), nchar(i), eller binary(i). |
| kolumner av djuptyp med variabel längd beräknad storlek | SUM(<computed size of variable length deep type columns>)Den beräknade storleken på varje kolumn är följande: i för varchar(i) och varbinary(i)2 * i för nvarchar(i) |
Den här raden tillämpas bara på beräknad radkroppsstorlek. Djuptypskolumner med variabel längd är kolumner av typen varchar(i), nvarchar(i), eller varbinary(i). Den beräknade storleken bestäms av den maximala längden ( i) i kolumnen. |
| Kolumner av djuptyp med variabel längd faktisk storlek | SUM(<actual size of variable length deep type columns>)Den faktiska storleken på varje kolumn är följande: n, där n är antalet tecken som lagras i kolumnen för varchar(i).2 * n, där n är antalet tecken som lagras i kolumnen för nvarchar(i).n, där n är antalet byte som lagras i kolumnen för varbinary(i). |
Den här raden gäller bara för faktiska radens storlek. Den faktiska storleken bestäms av de data som lagras i kolumnerna på raden. |
Exempel: Beräkning av tabell- och radstorlek
För hash-index avrundas det faktiska antalet buckets uppåt till närmaste potens av 2. Om den angivna bucket_count till exempel är 100000 är det faktiska bucketantalet för indexet 131072.
Överväg en ordertabell med följande definition:
CREATE TABLE dbo.Orders (
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
CustomerID INT NOT NULL INDEX IX_CustomerID HASH WITH (BUCKET_COUNT = 10000),
OrderDate DATETIME NOT NULL,
OrderDescription NVARCHAR(1000)
)
WITH (MEMORY_OPTIMIZED = ON);
GO
Den här tabellen har ett hash-index och ett icke-grupperat index (primärnyckeln). Den har också tre kolumner med fast längd och en kolumn med variabel längd, där en av kolumnerna är NULLkapabel (OrderDescription). Anta att tabellen Orders har 8 379 rader och att den genomsnittliga längden på värdena i kolumnen OrderDescription är 78 tecken.
Bestäm tabellstorleken genom att först bestämma storleken på indexen.
bucket_count för båda indexen anges som 10000. Detta avrundas upp till närmaste tvåpotens: 16384. Därför är den totala storleken på indexen för den Orders tabellen:
8 * 16384 = 131072 bytes
Det som återstår är tabellens datastorlek, vilket är:
<row size> * <row count> = <row size> * 8379
(Exempeltabellen har 8 379 rader.) Nu har vi:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indices> = 24 + 8 * 1 = 32 bytes
Nu ska vi beräkna <actual row body size>:
Kolumner av ytlig typ:
SUM(<size of shallow types>) = 4 <int> + 4 <int> + 8 <datetime> = 16Utfyllnad av grunda kolumner är 0, eftersom den totala grunda kolumnstorleken är jämn.
Förskjutningsmatris för djupa typkolumner:
2 + 2 * <number of deep type columns> = 2 + 2 * 1 = 4NULLarray = 1NULLmatrisutfyllnad = 1, eftersomNULLmatrisstorlek är udda och det finns en kolumn av djuptyp.Vaddering
- 8 är det största justeringskravet
- Storleken hittills är 16 + 0 + 4 + 1 + 1 = 22
- Närmaste multipel av 8 är 24
- Total utfyllnad är 24–22 = 2 byte
Det finns inga djuptypskolumner med fast längd (djuptypskolumner med fast längd: 0.).
Den faktiska storleken på kolumnen för djuptyp är 2 * 78 = 156. Kolumnen med den enskilda djuptypen
OrderDescriptionhar typennvarchar.
<actual row body size> = 24 + 156 = 180 bytes
Så här slutför du beräkningen:
<row size> = 32 + 180 = 212 bytes
<table size> = 8 * 16384 + 212 * 8379 = 131072 + 1776348 = 1907420
Den totala tabellstorleken i minnet är alltså cirka 2 megabyte. Detta tar inte hänsyn till eventuella kostnader som uppstår vid minnesallokering och eventuella radversioner som krävs för transaktionerna som kommer åt den här tabellen.
Det faktiska minne som allokeras för och används av den här tabellen och dess index kan hämtas via följande fråga:
SELECT * FROM sys.dm_db_xtp_table_memory_stats
WHERE object_id = object_id('dbo.Orders');
Begränsningar för kolumner utanför raden
Vissa begränsningar och förbehåll för att använda kolumner utanför rad i en minnesoptimerad tabell visas på följande sätt:
- Om det finns ett kolumnlagringsindex i en minnesoptimerad tabell måste alla kolumner få plats på rad.
- Alla indexnyckelkolumner måste lagras på rad. Om en indexnyckelkolumn inte får plats på rad misslyckas det att lägga till indexet.
- Varningar om att ändra en minnesoptimerad tabell med kolumner utanför rad.
- För LOB:er speglar storleksbegränsningen diskbaserade tabeller (2 GB-gräns för LOB-värden).
- För optimala prestanda rekommenderar vi att de flesta kolumner får plats inom 8 060 byte.
- Data utanför rad kan orsaka överdriven minnes- och/eller diskanvändning.