Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Skillnader i maskinvaru-, programvaru- och klusterkonfigurationer samt olika programkrav för drifttid och prestanda kräver specifik konfiguration för tidsgränsvärden för lån, kluster och hälsokontroll. Vissa program och arbetsbelastningar kräver mer aggressiv övervakning för att begränsa stilleståndstiden efter hårda fel. Andra kräver mer tolerans för tillfälliga nätverksproblem och väntetider på grund av hög resursanvändning och är villiga att tolerera långsammare systemfelövergångar.
Flera tjänster på varje nod fungerar för att identifiera fel. Klustertjänsten kan identifiera kvorumförlust; resurs-DLL:en kan identifiera ett problem som visas av Always On-hälsoidentifiering; eller så kan manuell övergång initieras direkt på den primära instansen. Klustertjänsten, resursvärden och SQL Server-instansen synkroniseras med varandra via RPC, delat minne och T-SQL. I de flesta scenarier kommunicerar dessa tjänster framgångsrikt, men den här kommunikationen är inte helt tillförlitlig även mellan tjänster på samma dator. Dessutom måste tillgänglighetsgruppen (AG) kunna hantera systemomfattande händelser som nätverks- och diskfel, vilket kan förhindra kommunikation eller störa funktionaliteten. Med många felfall och utan helt tillförlitlig kommunikation mellan tjänster är tillgänglighetsgruppen beroende av olika mekanismer för redundansidentifiering för att identifiera och svara på fel oberoende av varandra så att klustertillståndet alltid är konsekvent för alla noder.
Klusternod och resursidentifiering
Varje nod i klustret kör en enskild klustertjänst som kör redundansklustret och övervakar alla klusterresurser. Resursvärden fungerar som en separat process och är gränssnittet mellan klustertjänsten och klusterresurserna. Resursvärden utför åtgärder på klusterresurser när den tillfrågas av klustertjänsten. Klustermedvetna program som SQL Server tillhandahåller anpassade gränssnitt till resursövervakaren via resurs-DLL:er. Resurs-DLL implementerar online- och offlineåtgärder och hälsoövervakning för anpassade resurser. Värdresursen är en underordnad process i klustertjänsten och stoppas när klustertjänsten avlivas.
För SQL Server avgör tillgänglighetsgruppens resurs-DLL hälsotillståndet för tillgänglighetsgruppen baserat på tillgänglighetsgruppens lånemekanism och AlwaysOn-hälsoidentifiering. AG-resursens DLL exponerar resurshälsan via åtgärden IsAlive. Resursövervakaren kontrollerar IsAlive vid det klustrets pulsslagsintervall, vilket anges av de klustergemensamma värdena CrossSubnetDelay och SameSubnetDelay. På en primär nod initierar klustertjänsten redundans när IsAlive-anropet till resurs-DLL:en returnerar att tillgänglighetsgruppen inte är felfri.
Klustertjänsten skickar pulsslag till andra noder i klustret och bekräftar pulsslag som tas emot från dem. När en nod identifierar ett kommunikationsfel från en serie omärkta pulsslag sänder den ett meddelande som gör att alla nåbara noder kan stämma av sina vyer av klusternodens hälsa. Den här händelsen, som kallas för en omgrupperingshändelse, upprätthåller klustrets tillståndskonsistens mellan noder. Om kvorum går förlorat efter en omgrupperingshändelse tas alla klusterresurser, inklusive AG:er i den här partitionen, offline. Alla noder i den här partitionen övergår till ett lösningstillstånd. Om en partition finns, som innehåller ett kvorum, är tillgänglighetsgruppen tilldelad en nod i partitionen och blir den primära repliken medan alla andra noder blir sekundära repliker.
Hälsodetektering med alltid på
Resurs-DLL:et AlwaysOn övervakar statusen för interna SQL Server-komponenter.
sp_server_diagnostics rapporterar hälsotillståndet för dessa komponenter SQL Server på ett intervall som styrs av HealthCheckTimeout.
sp_server_diagnostics rapporterar hälsostatus för fem instansnivåkomponenter: system, resurs, frågebearbetning, io-undersystem och händelser. Den rapporterar också hälsotillståndet för varje arbetsgrupp. Vid varje uppdatering uppdaterar resurs-DLL:et hälsostatusen för tillgänglighetsgruppens resurs baserat på felnivån för tillgänglighetsgruppen. När data returneras av sp_server_diagnosticsvisas varje komponent som antingen i ett rent, varnings-, fel- eller okänt tillstånd med vissa XML-data som beskriver komponentens tillstånd. För hälsoidentifiering vidtar resurs-DLL endast åtgärder om en komponent är i feltillstånd.
Om hälsoövervakningen inte rapporterar en uppdatering av resurs-DLL:n under flera intervall fastställs tillgänglighetsgruppen som ohälsosam och kommer att rapportera fel vid IsAlive-anrop.
Lånemekanism
Till skillnad från andra redundansmekanismer spelar SQL Server-instansen en aktiv roll i lånemekanismen. Lånemekanismen används som en Looks-Alive validering mellan klusterresursvärden och SQL Server-processen. Mekanismen används för att säkerställa att de två sidorna (klustertjänsten och SQL Server-tjänsten) är i frekvent kontakt, kontrollerar varandras tillstånd och slutligen förhindrar ett scenario med delad hjärna. När tillgänglighetsgruppen aktiveras som den primära repliken startar SQL Server-instansen en dedikerad leasingtråd för tillgänglighetsgruppen. Hyrestagaren delar en liten del av minnet med resursservern som innehåller händelser för hyresförlängning och hyresavslut. Lånearbetaren och resursvärden arbetar på ett cirkulärt sätt, signalerar sin respektive förnyelsehändelse för lån och sover sedan, väntar på att den andra parten ska signalera sin egen förnyelsehändelse eller stoppa händelsen. Både resursvärden och SQL Server-leasetråden upprätthåller ett livslängdsvärde som uppdateras varje gång tråden väcks efter att ha blivit signalerad av den andra tråden. Om livslängden uppnås medan man väntar på signalen, upphör kontraktet att gälla och repliken övergår sedan till lösningstillståndet för den specifika tillgänglighetsgruppen. Om lånestoppshändelsen signaleras övergår repliken till en matchande roll.
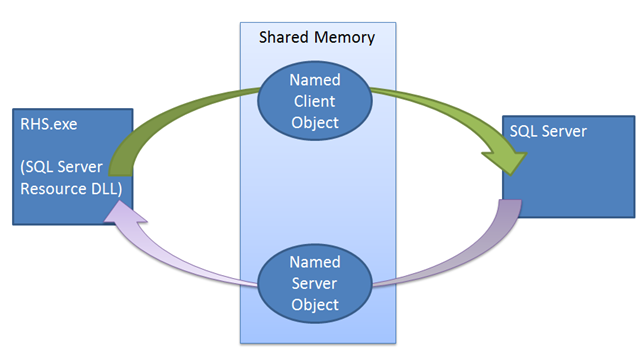
Lånemekanismen tillämpar synkronisering mellan SQL Server och Windows Server-redundanskluster. När ett redundanskommando utfärdas gör klustertjänsten Offline anrop till resurs-DLL:en för den aktuella primära repliken. Resurs-DLL:en försöker först ta AG (tillgänglighetsgruppen) offline med hjälp av en lagrad procedur. Om den här lagrade proceduren misslyckas eller överskrider tidsgränsen rapporteras felet tillbaka till klustertjänsten, som sedan utfärdar ett avsluta-kommando. Återigen försöker termineringsprocessen köra samma lagrade procedur, men den här gången väntar inte klustret på att resurs-DLL:n ska rapportera lyckat eller misslyckat resultat innan tillgänglighetsgruppen tas online på en ny replik. Om det andra proceduranropet misslyckas måste resursvärden förlita sig på lånemekanismen för att ta instansen offline. När resurs-DLL:en anropas för att ta tillgänglighetsgruppen offline, signalerar resurs-DLL:en lånestoppshändelsen och väcker SQL Server-lånearbetstråden för att ta tillgänglighetsgruppen offline. Även om den här stopphändelsen inte signaleras, upphör lånet att gälla och repliken övergår till lösningstillståndet.
Lånet är främst en synkroniseringsmekanism mellan den primära instansen och klustret, men det kan också skapa felvillkor där det annars inte fanns något behov av redundansväxling. Till exempel kan hög CPU-användning, minnesbrist (lågt virtuellt minne, processintervallering), SQL-process som inte svarar när en minnesdump genereras, systemet svarar inte, kluster (WSFC) som går offline (till exempel på grund av förlust av kvorum) förhindra förnyelse av leasing från SQL-instansen och orsaka omstart eller felövergång.
Riktlinjer för timeout-värden för kluster
Överväg noggrant kompromisserna och förstå konsekvenserna av att använda mindre aggressiv övervakning av ditt SQL Server-kluster. Om du ökar tidsgränsvärdena för kluster ökar toleransen för tillfälliga nätverksproblem men minskar reaktionerna på svåra fel. Om du ökar tidsgränserna för att hantera resurstryck eller stora geografiska svarstider ökar du även tiden för återställning efter svåra eller oåterkalleliga fel. Även om detta är acceptabelt för många program är det inte idealiskt i alla fall.
Standardinställningarna är optimerade för att snabbt reagera på symtom på svåra fel och begränsa stilleståndstid, men de här inställningarna kan också vara alltför aggressiva för vissa arbetsbelastningar och konfigurationer. Vi rekommenderar inte att du sänker något av LeaseTimeout, CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay, SameSubnetThresholdeller HealthCheckTimeout utöver standardvärdena. Rätt inställningar för varje distribution varierar och det tar sannolikt längre tid att finjustera. När du gör ändringar i något av dessa värden gör du dem gradvis och med hänsyn till relationer och beroenden mellan dessa värden.
Relation mellan timeout för kluster och tidsgräns för lån
Den primära funktionen för lånemekanismen är att koppla från SQL Server-resursen om klustertjänsten inte kan kommunicera med instansen när en redundansväxling utförs till en annan nod. När klustret utför offlineåtgärden på AG-klusterresursen gör klustertjänsten ett RPC-anrop till rhs.exe för att ta resursen offline. Resurs-DLL:et använder lagrade procedurer för att instruera SQL Server att ta tillgänglighetsgruppen offline, men den här lagrade proceduren kan misslyckas eller överskrida tidsgränsen. Resurshanteraren stoppar också sin egen förnyelsetråd för lån under offline-samtalet. I värsta fall orsakar SQL Server att leasingavtalet upphör att gälla inom ½ * LeaseTimeout och övergår instansen till ett lösande tillstånd. Övergångar kan initieras av flera olika parter, men det är mycket viktigt att klustrets tillståndsöversikt är konsekvent över klustret och över SQL Server-instanser. Tänk dig till exempel ett scenario där den primära instansen förlorar anslutningen till resten av klustret. Varje nod i klustret avgör ett fel vid liknande tidpunkter på grund av tidsgränsvärdena för klustret, men endast den primära noden kan interagera med den primära SQL Server-instansen för att tvinga den att ge upp den primära rollen.
Från den primära nodens perspektiv förlorade klustertjänsten kvorum och tjänsten börjar avsluta sig själv. Klustertjänsten utfärdar ett RPC-anrop till resursvärden för att avsluta processen. Det här terminate-anropet ansvarar för att ta AG offline på SQL Server-instansen. Det här offlineanropet görs via T-SQL, men kan inte garantera att anslutningen upprättas mellan SQL och resurs-DLL.
Ur resten av klustrets perspektiv finns det för närvarande ingen huvudreplik, så klustret röstar och etablerar en enda ny huvudreplik för de återstående noderna i klustret. Om den lagrade proceduren som anropades av resurs-DLL:en misslyckas eller överskrider tidsgränsen kan klustret vara sårbart för ett scenario med delad hjärna.
Tidsgränsen för leasetiden förhindrar split-brain-scenarier vid kommunikationsfel. Även om all kommunikation misslyckas kommer resurs-DLL-processen att avslutas och inte kunna uppdatera leasen. När leasingavtalet upphör att gälla, tar det tillgänglighetsgrupp offline på egen hand. Sql Server-instansen måste vara medveten om att den inte längre är värd för den primära repliken innan klustret etablerar en ny. Eftersom resten av klustret, som ansvarar för att välja en ny primär replik, inte har något sätt att samordna med den aktuella primära repliken, säkerställer tidsgränsvärdena att en ny primär replik inte upprättas innan den aktuella primära repliken tar sig offline.
När klustret växlar över måste instansen av SQL Server som är värd för den föregående primära replikan övergå till ett lösningstillstånd innan den nya primära replikan är online. SQL Server-lånetråden har vid varje tillfälle en återstående livstid på ½ * LeaseTimeout, eftersom när lånet förnyas uppdateras livstid till LeaseInterval eller ½ * LeaseTimeout. Om klustertjänsten eller resursvärdtjänsten stannar eller avslutas utan att signalera lånestopphändelsen deklarerar klustret den primära noden död efter SameSubnetThreshold\ SameSubnetDelay millisekunder. Under denna tid måste leasingavtalet upphöra så att huvudenheten kommer att vara offline garanterat. Eftersom den maximala tidsgränsen för lånet är 0,5 * LeaseTimeout, måste 0,5 * LeaseTimeout vara mindre än SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold \<= CrossSubnetThreshold och SameSubnetDelay \<= CrossSubnetDelay ska gälla för alla SQL Server-kluster.
Tidsgränsåtgärd för hälsokontroll
Tidsgränsen för hälsokontroll är mer flexibel eftersom ingen annan redundansmekanism är direkt beroende av den. Standardvärdet på 30 sekunder anger sp_server_diagnostics intervall till 10 sekunder, med ett minsta värde på 15 sekunder för timeout och ett intervall på 5 sekunder. Mer allmänt är sp_server_diagnostics uppdateringsintervallet alltid 1/3 * HealthCheckTimeout. När resurs-DLL:n inte tar emot en ny uppsättning hälsodata vid ett visst intervall fortsätter den att använda hälsodata från föregående intervall för att bedöma den aktuella tillgänglighetsgruppen och instanshälsan. Genom att öka tidsgränsen för hälsokontrollen blir primären mer tolerant mot CPU-belastning, vilket kan hindra sp_server_diagnostics från att tillhandahålla nya data vid varje intervall; dock förlitar den sig längre på hälsokontroller med inaktuell data. Oavsett timeout-värdet returneras nästa IsAlive-anrop när data tas emot som anger att repliken inte är felfri och klustertjänsten initierar en redundansväxling.
Feltillståndsnivån för AG ändrar felvillkoren för hälsokontrollen. Om AG-elementet rapporteras som ohälsosamt av sp_server_diagnostics, misslyckas hälsokontrollen på vilken felnivå som helst. Varje nivå ärver alla felvillkor från nivåerna under den.
| Nivå | Villkor under vilket instansen anses vara död |
|---|---|
| 1: OnServerDown | Hälsokontrollen vidtar ingen åtgärd om några resurser misslyckas förutom tillgänglighetsgruppen. Om AG-data inte tas emot inom 5 intervall eller 5/3 * HealthCheckTimeout |
| 2: OnServerUnresponsive | Om inga data tas emot från sp_server_diagnostics för HealthCheckTimeout |
| 3: OnCriticalServerError | (Standard) Om systemkomponenten rapporterar ett fel |
| 4: OnModerateServerError | Om resurskomponenten rapporterar ett fel |
| 5: VidEventuellaKvalificeradeFelVillkor | Om frågebearbetningskomponenten rapporterar ett fel |
Uppdatera kluster- och AlwaysOn-timeoutvärden
Klustervärden
Det finns fyra värden i WSFC-konfigurationen som ansvarar för att fastställa tidsgränsvärden för kluster:
- SameSubnetDelay
- SammaSubnätGräns
- Fördröjning över delnät
- CrossSubnetThreshold
Fördröjningsvärdena avgör väntetiden mellan pulsslag från klustertjänsten och tröskelvärdena anger antalet pulsslag som inte kan ta emot någon bekräftelse från målnoden eller resursen innan objektet förklaras dött av klustret. Om det inte finns något framgångsrikt hjärtslag mellan noder i samma undernät under mer än SameSubnetDelay \* SameSubnetThreshold millisekunder, fastställs noden som död. Detsamma gäller kommunikation mellan undernät med hjälp av värdena för korsundernät.
Om du vill visa en lista över alla aktuella klustervärden öppnar du en upphöjd PowerShell-terminal på valfri nod i målklustret. Kör följande kommando:
Get-Cluster | fl *
Om du vill uppdatera något av dessa värden kör du följande kommando i en upphöjd PowerShell-terminal:
(Get-Cluster).<ValueName> = <NewValue>
När du ökar produkten Delay * Threshold (Fördröjning * Tröskelvärde) för att göra tidsgränsen för klustret mer tolerant, är det mer effektivt att först öka fördröjningsvärdet innan du ökar tröskelvärdet. Genom att öka fördröjningen ökar tiden mellan varje pulsslag. Mer tid mellan pulsslag ger mer tid för tillfälliga nätverksproblem att lösa sig själva och minska nätverksbelastningen i förhållande till att skicka fler pulsslag under samma period.
Tidsgräns för leasing
Mekanismen för leasing styrs av ett enda värde som är specifikt för varje AG i ett WSFC-kluster. En tidsgräns för lån kan resultera i följande fel:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
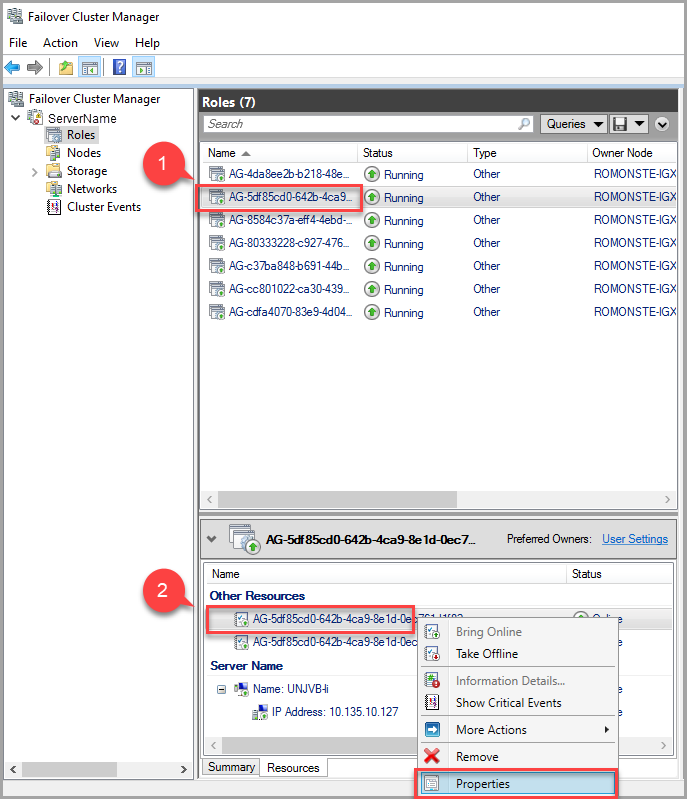
Om du vill ändra tidsgränsvärdet för leasing använder du Felövervakningsklusterhanteraren och följer dessa steg:
På fliken Roller letar du reda på målrollen för AG. Välj målrollen AG.
Högerklicka på resursen för tillgänglighetsgruppen längst ned i fönstret och välj Egenskaper.
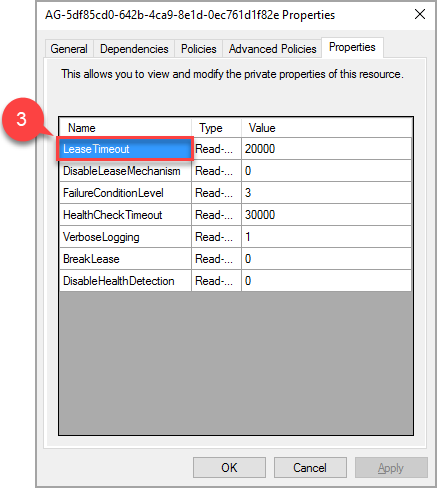
I popup-fönstret går du till egenskapsfliken för att visa en lista med värden som är specifika för den här tillgänglighetsgruppen. Välj värdet LeaseTimeout för att ändra det.
Beroende på tillgänglighetsgruppens konfiguration kan det finnas ytterligare resurser för lyssnare, delade diskar, filresurser osv. dessa resurser kräver ingen ytterligare konfiguration.
Not
Det nya värdet för egenskapen "LeaseTimeout" börjar gälla efter att resursen har tagits offline och sedan tas online igen.
Hälsokontrollvärden
Två värden styr hälsokontrollen AlwaysOn: FailureConditionLevel och HealthCheckTimeout. FailureConditionLevel anger toleransnivån för specifika feltillstånd som rapporterats av sp_server_diagnostics och HealthCheckTimeout konfigurerar den tid som resurs-DLL:en kan gå utan att ta emot en uppdatering från sp_server_diagnostics. Uppdateringsintervallet för sp_server_diagnostics är alltid HealthCheckTimeout/3.
Om du vill konfigurera villkorsnivån för redundans använder du alternativet FAILURE_CONDITION_LEVEL = <n> för instruktionen CREATE eller ALTERAVAILABILITY GROUP, där <n> är ett heltal mellan 1 och 5. Följande kommando anger felvillkorsnivån till 1 för tillgänglighetsgruppen AG1:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
För att konfigurera tidsgränsen för hälsokontroll, använd alternativet HEALTH_CHECK_TIMEOUT i CREATE- eller ALTERAVAILABILITY GROUP-satserna. Följande kommando anger tidsgränsen för hälsokontroll till 60 000 millisekunder för AG AG1:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Sammanfattning av riktlinjer för tidsgräns
Att sänka eventuella timeout-värden under standardvärdena rekommenderas inte.
Låneintervallet (1/2 * LeaseTimeout) måste vara kortare än SameSubnetThreshold * SameSubnetDelay
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Timeout-inställning | Avsikt | Mellan | Använder | IsAlive & LooksAlive | Orsaker | Utfall |
|---|---|---|---|---|---|---|
| Tidsgräns för leasing Standardvärde: 20000 |
Förhindra delad hjärna | Primärt till kluster (HADR) |
Windows-händelseobjekt | Används i båda | OS svarar inte, lågt virtuellt minne, växling av arbetsuppsättning, genererar dump, fastlåst CPU, WSFC nere (kvorumsförlust) | Tillgänglighetsgruppens resurs offline- online, redundans |
| Tidsgräns för sessioner standard: 10000 |
Informera om ett kommunikationsproblem mellan primärsystem och sekundärsystem | Sekundär till primär (HADR) |
TCP Sockets (meddelanden som skickas via DBM-slutpunkten) | Används i ingen av | Nätverkskommunikation, Problem med sekundär funktion – nere, operativsystemet svarar inte, resurskonflikt |
Sekundär – FRÅNKOPPLAD |
| Tidsgräns för hälsokontroll Standard: 30 000 |
Ange tidsgräns vid försök att fastställa den primära replikens hälsotillstånd | Kluster till primären (FCI & HADR) |
T-SQL sp_server_diagnostics | Används i båda | Felvillkor uppfyllda, operativsystem svarar inte, lågt virtuellt minne, trimning av arbetsuppsättningar, generering av dump, WSFC (förlust av kvorum), schemaläggningsproblem (döda låsta schemaläggare) | AG-resurs offline eller redundans, FCI-omstart/redundans |