Skapa, exportera och poängsätta Spark-maskininlärningsmodeller på SQL Server Big Data Clusters
Viktig
Tillägget Stordatakluster i Microsoft SQL Server 2019 dras tillbaka. Stödet för SQL Server 2019 Big Data Clusters upphör den 28 februari 2025. Alla befintliga användare av SQL Server 2019 med Software Assurance stöds fullt ut på plattformen och programvaran fortsätter att underhållas via kumulativa SQL Server-uppdateringar fram till dess. Mer information finns i bloggannonsen och big data-alternativ på Microsoft SQL Server-plattformen.
Följande exempel visar hur du skapar en modell med Spark ML-, exporterar modellen till MLeapoch poängsätt modellen i SQL Server med dess Java Language Extension. Detta görs i kontexten för ett SQL Server-stordatakluster.
Följande diagram illustrerar det arbete som utförts i det här exemplet:
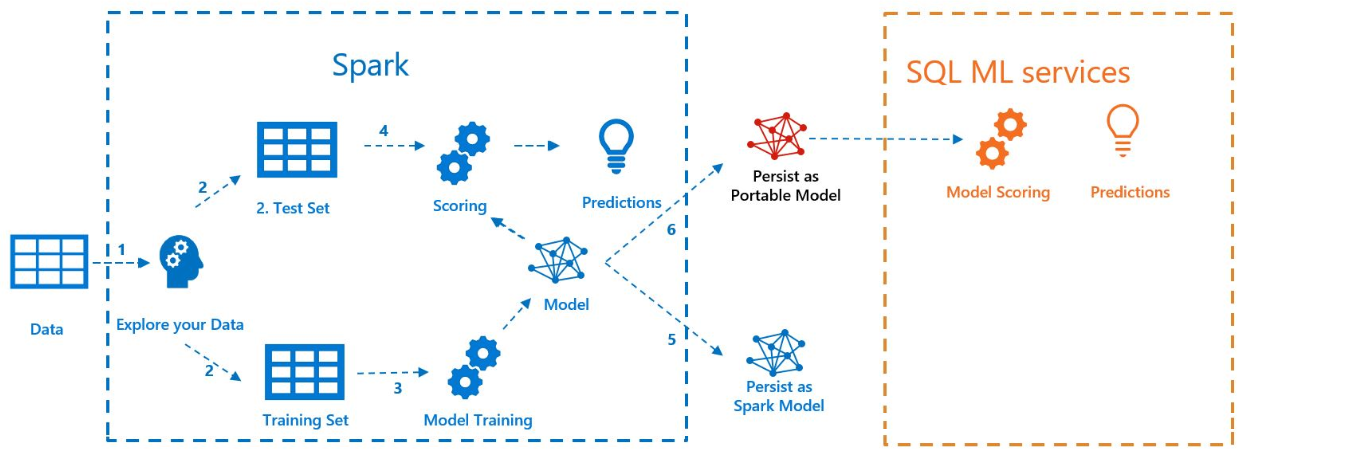
Förutsättningar
Alla filer för det här exemplet finns på https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
Om du vill köra exemplet måste du också ha följande förutsättningar:
-
- kubectl
- curl
- Azure Data Studio
Modellträning med Spark ML
I det här exemplet används censusdata (AdultCensusIncome.csv) för att skapa en Spark ML-pipelinemodell.
Använd filen mleap_sql_test/setup.sh för att ladda ned datauppsättningen från Internet och placera den på HDFS i sql Server-stordataklustret. På så sätt kan den nås av Spark.
Ladda sedan ner exempelnotebooken train_score_export_ml_models_with_spark.ipynb. Från en PowerShell- eller bash-kommandorad kör du följande kommando för att ladda ned anteckningsboken:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"Den här notebook-filen innehåller celler med de kommandon som krävs för det här avsnittet i exemplet.
Öppna notebook-filen i Azure Data Studio och kör varje kodblock. Mer information om hur du arbetar med notebook-filer finns i Använda notebook-filer med SQL Server.
Data läss först in i Spark och delas upp i datauppsättningar för träning och testning. Sedan tränar koden en pipelinemodell med träningsdata. Slutligen exporteras modellen till ett MLeap-paket.
Tips
Du kan också granska eller köra Python-koden som är associerad med de här stegen utanför notebook-filen i filen mleap_sql_test/mleap_pyspark.py.
Modellbedömning med SQL Server
Nu när Spark ML-pipelinemodellen är i en gemensam serialisering MLeap-paket format kan du poängsätta modellen i Java utan att Det finns Spark.
Det här exemplet använder Java Language Extension i SQL Server. För att kunna poängsätta modellen i SQL Server måste du först skapa ett Java-program som kan läsa in modellen i Java och poängsätta den. Du hittar exempelkoden för det här Java-programmet i mappen mssql-mleap-app.
När du har skapat exemplet kan du använda Transact-SQL för att anropa Java-programmet och poängsätta modellen med en databastabell. Detta visas i källfilen mleap_sql_test/mleap_sql_tests.py.
Nästa steg
Mer information om stordatakluster finns i Så här distribuerar du SQL Server-stordatakluster på Kubernetes