Serialisering av datamodellen till och från olika butiker (förhandsversion)
För att datamodellen ska kunna lagras i en databas måste den konverteras till ett format som databasen kan förstå. Olika databaser kräver olika lagringsscheman och format. Vissa har ett strikt schema som måste följas, medan andra tillåter att schemat definieras av användaren.
Mappningsalternativ
Anslutningarna för vektorlagret som tillhandahålls av Semantisk Kernel erbjuder flera sätt att uppnå den här mappningen.
Inbyggda mappare
Vektorlagringsanslutningarna som tillhandahålls av semantisk kernel har inbyggda mappningar som mappar datamodellen till och från databasschemana. Mer information om hur de inbyggda mapparna mappar data för varje databas finns på -sidan för varje kontakt.
Anpassade mappare
Vektorlagringsanslutningarna som tillhandahålls av Semantic Kernel stöder möjligheten att tillhandahålla anpassade mappare i kombination med en VectorStoreRecordDefinition. I det här fallet kan VectorStoreRecordDefinition skilja sig från den angivna datamodellen.
Elementet VectorStoreRecordDefinition används för att definiera databasschemat, medan datamodellen används av utvecklaren för att interagera med vektorlagringen.
En anpassad mappare krävs i det här fallet för att mappa från datamodellen till det anpassade databasschemat som definieras av VectorStoreRecordDefinition.
Tips
Se Hur man bygger en anpassad mappare för en Vector Store-anslutning för ett exempel på hur du skapar en egen anpassad mappare.
För att datamodellen ska definieras antingen som en klass eller en definition som ska lagras i en databas måste den serialiseras till ett format som databasen kan förstå.
Det finns två sätt att göra, antingen genom att använda den inbyggda serialiseringen som tillhandahålls av semantisk kernel eller genom att tillhandahålla din egen serialiseringslogik.
Följande två diagram visar att flödena visas för både serialisering och deserialisering av datamodeller till och från en lagringsmodell.
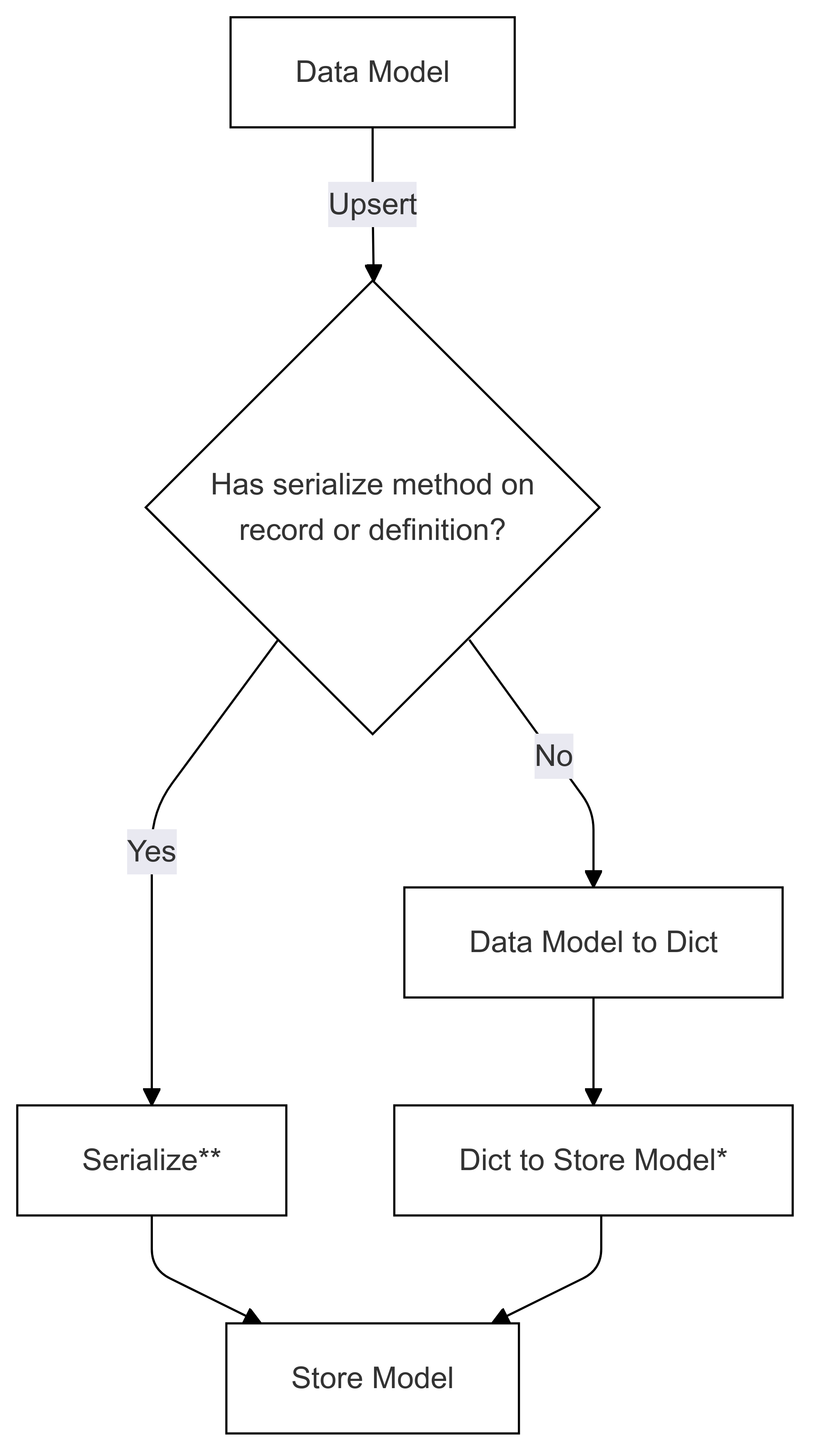
Serialiseringsflöde (används i Upsert)
Deserialiseringsflöde (används i Hämta och sök)
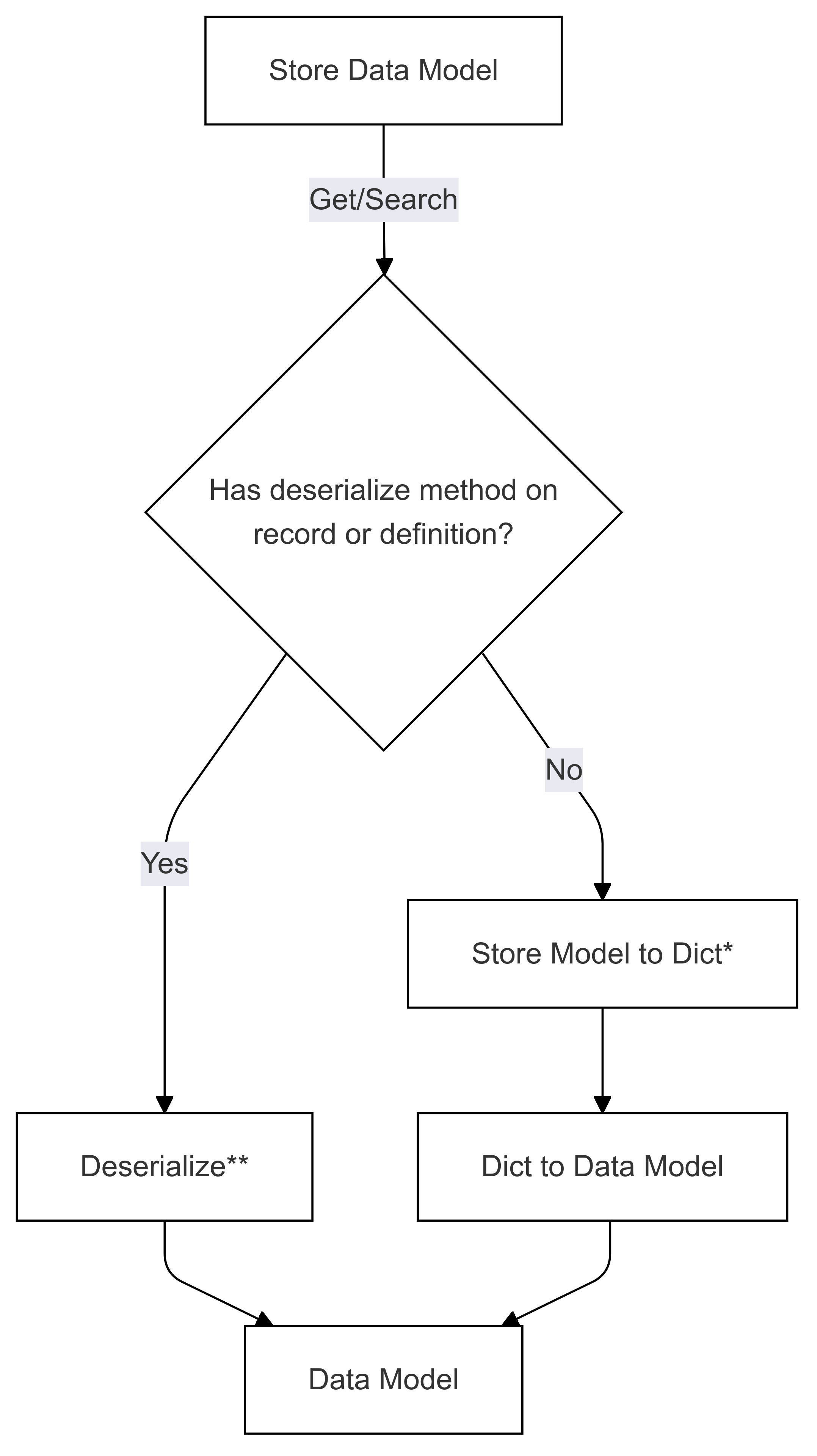
Stegen som markeras med * (i båda diagrammen) implementeras av utvecklaren av ett specifikt kopplingsprogram och är olika för varje butik. Stegen som är markerade med ** (i båda diagrammen) anges antingen som en metod för en post eller som en del av postdefinitionen. Detta tillhandahålls alltid av användaren, se Direct Serialization för mer information.
(De)Serialiseringsmetoder
Direkt serialisering (datamodell till lagringsmodell)
Direkt serialiseringen är det bästa sättet att säkerställa fullständig kontroll över hur dina modeller serialiseras och optimera prestanda. Nackdelen är att det är specifikt för ett datalager, och därför är det inte lika enkelt att växla mellan olika lager med samma datamodell när du använder detta.
Du kan använda detta genom att implementera en metod som följer SerializeMethodProtocol-protokollet i din datamodell eller genom att lägga till funktioner som följer SerializeFunctionProtocol i din postdefinition; båda kan hittas i semantic_kernel/data/vector_store_model_protocols.py.
När en av dessa funktioner finns används den för att direkt serialisera datamodellen till lagringsmodellen.
Du kan till och med välja att bara implementera en av de två och använda den inbyggda (de)serialiseringen för den andra riktningen. Detta kan till exempel vara användbart när du hanterar en samling som har skapats utanför din kontroll och du måste anpassa hur den deserialiseras (och du kan inte göra en upsert ändå).
Inbyggd (de)serialisering (datamodell till diktering och diktering till lagringsmodell och vice versa)
Den inbyggda serialiseringen görs genom att först konvertera datamodellen till en ordlista och sedan serialisera den till den modell som lagringen förstår, för varje lager som är olika och definierat som en del av den inbyggda anslutningsappen. Deserialisering görs i omvänd ordning.
Serialisering steg 1: Datamodell till diktering
Beroende på vilken typ av datamodell du har utförs stegen på olika sätt. Det finns fyra sätt att försöka serialisera datamodellen till en ordlista:
-
to_dict-metoden för definitionen (justeras till datamodellens to_dict attribut enligtToDictFunctionProtocol) - kontrollera om det är en
ToDictMethodProtocol-post och användto_dict-metoden - kontrollera om posten är en pydantisk modell och använd modellens
model_dump. Mer information finns i anteckningen nedan. - loopa igenom fälten i definitionen och skapa ordlistan
Serialisering steg 2: Diktera för att lagra modell
En metod måste anges av anslutningsappen för att konvertera ordlistan till butiksmodellen. ** Detta görs av utvecklaren av anslutningen och skiljer sig åt för varje butik.
Deserialisering Steg 1: Lagra modell till diktering
En metod måste tillhandahållas av anslutningen för att konvertera lagermodellen till en ordbok. Detta görs av utvecklaren av anslutningen och skiljer sig från varje butik.
Deserialisering steg 2: Diktering till datamodell
Deserialiseringen görs i omvänd ordning. Dessa alternativ provas:
-
from_dict-metoden för definitionen (justeras till datamodellens from_dict attribut enligtFromDictFunctionProtocol) - kontrollera om posten är
FromDictMethodProtocoloch användfrom_dict-metoden - kontrollera om posten är en pydantisk modell och använd modellens
model_validate. Mer information finns i anteckningen nedan. - loopa igenom fälten i definitionen och ange värdena, sedan skickas denna diktering till konstruktorn för datamodellen som namngivna argument (såvida inte datamodellen är en diktamen själv, i så fall returneras den som den är)
Notera
Använda Pydantic med inbyggd serialisering
När du definierar din modell med hjälp av en Pydantic BaseModel använder den metoderna och model_dump för att serialisera och deserialisera datamodellen till och från en diktamenmodel_validate. Detta görs med hjälp av metoden model_dump utan några parametrar, om du vill kontrollera det bör du överväga att implementera ToDictMethodProtocol på datamodellen, eftersom det provas först.
Serialisering av vektorer
När du har en vektor i datamodellen måste den antingen vara en lista över flyttal eller en lista över ints, eftersom det är vad de flesta butiker behöver, om du vill att din klass ska lagra vektorn i ett annat format kan du använda serialize_function och deserialize_function definieras i anteckningen VectorStoreRecordVectorField . För en numpy-matris kan du till exempel använda följande kommentar:
import numpy as np
vector: Annotated[
np.ndarray | None,
VectorStoreRecordVectorField(
dimensions=1536,
serialize_function=np.ndarray.tolist,
deserialize_function=np.array,
),
] = None
Om du använder ett vektorlager som kan hantera interna numpy-matriser och du inte vill att de ska konverteras fram och tillbaka bör du konfigurera direkt serialisering och deserialisering metoder för modellen och det arkivet.
Not
Detta används endast när du använder den inbyggda serialiseringen, när du använder den direkta serialiseringen kan du hantera vektorn på valfritt sätt.
Kommer snart
Mer information kommer snart.