Flera GPU:er och datorer
1. Inledning
CNTK stöder för närvarande fyra parallella SGD-algoritmer:
Förutsättningar
Om du vill köra parallell träning kontrollerar du att en implementering av MPI (Message Passing Interface) är installerad:
I Windows installerar du version 7 (7.0.12437.6) av Microsoft MPI (MS-MPI), en Microsoft-implementering av standard för meddelandeöverföringsgränssnittet, från den här nedladdningssidan, markerad helt enkelt som "Version 7" i sidrubriken. Klicka på knappen Ladda ned och välj sedan körningstid (
MSMpiSetup.exe).Installera OpenMPI version 1.10.x i Linux. Följ anvisningarna här för att skapa den själv.
2. Konfigurera parallell träning i CNTK i Python
Om du vill använda dataparallell SGD i Python måste användaren skapa och skicka en distribuerad elev till utbildaren:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
För användardefinierade träningsloopar (i stället för training_session) måste användarna skicka in num_data_partitions och partition_index till MinibatchSource.next_minibatch() metoden så att olika MPI-noder läser data från olika datapartitioner (efter distributed_after att exempel har lästs).
Observera att Communicator.finalize() endast bör anropas om den distribuerade utbildningen har slutförts. Om en distribuerad arbetare misslyckas ska den här metoden inte anropas.
Ett fullt fungerande exempel finns i ConvNet-exemplet.
3. Konfigurera parallell träning i CNTK i BrainScript
Om du vill aktivera parallell träning i CNTK BrainScript måste du först aktivera följande växel i antingen konfigurationsfilen eller på kommandoraden:
parallelTrain = true
För SGD det andra bör blocket i konfigurationsfilen innehålla ett underblock med namnet ParallelTrain med följande argument:
parallelizationMethod: (obligatoriska) legitima värden ärDataParallelSGD,BlockMomentumSGDochModelAveragingSGD.Detta anger vilken parallell algoritm som ska användas.
distributedMBReading: (valfritt) accepterar booleskt värde:trueellerfalse; standardvärdet ärfalseVi rekommenderar att du aktiverar distribuerad minibatchläsning för att minimera I/O-kostnaden för varje arbetare. Om du använder CNTK-textformatläsare, bildläsare eller sammansatt dataläsare ska distribueradMBReading anges till true.
parallelizationStartEpoch: (valfritt) accepterar heltalsvärde. standardvärdet är 1.Detta anger från vilken epok, parallella träningsalgoritmer används; innan det alla arbetstagare som gör samma utbildning, men bara en arbetare får spara modellen. Det här alternativet kan vara användbart om parallell träning kräver någon "varmstart"-fas.
syncPerfStats: (valfritt) accepterar heltalsvärde. standardvärdet är 0.Detta anger hur ofta prestandastatistiken skrivs ut. Den här statistiken innehåller den tid som ägnas åt kommunikation och/eller beräkning under en synkroniseringsperiod, vilket kan vara användbart för att förstå flaskhalsen med parallella träningsalgoritmer.
0 innebär att ingen statistik skrivs ut. Andra värden anger hur ofta statistiken skrivs ut. Till exempel
syncPerfStats=5innebär det att statistik skrivs ut efter var femte synkronisering.Ett underblock som anger information om varje parallell träningsalgoritm. Namnet på underblocket ska vara lika med
parallelizationMethod. (obligatoriskt)
Python ger mer flexibilitet och användning visas nedan för olika parallelliseringsmetoder.
4. Köra parallell träning med CNTK
Parallellisering i CNTK implementeras med MPI.
4.1 Köra parallell träning med BrainScript
Med tanke på någon av brainscript-konfigurationerna för parallell träning ovan kan följande kommandon användas för att starta ett parallellt MPI-jobb:
Parallell träning på samma dator med Linux:
mpiexec --npernode $num_workers $cntk configFile=$configParallell träning på samma dator med Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Parallell träning över flera beräkningsnoder med Linux:
Steg 1: Skapa en värdfil $hostfile med din favoritredigerare
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Där name_of_node(n) helt enkelt är ett DNS-namn eller en IP-adress för arbetsnoden.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Parallell träning över flera beräkningsnoder med Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
där $cntk ska referera till sökvägen för den körbara CNTK-filen ($x är Linux-gränssnittets sätt att ersätta miljövariabler, motsvarande %x% i Windows-gränssnittet).
4.2 Köra parallell träning med Python
Exempel på distribuerad träning för CNTK v2 med Python finns här:
Med ett CNTK v2 Python-skript training.py kan följande kommandon användas för att starta ett parallellt MPI-jobb:
Parallell träning på samma dator med Linux:
mpiexec --npernode $num_workers python training.pyParallell träning på samma dator med Windows:
mpiexec -n %num_workers% python training.pyParallell träning över flera beräkningsnoder med Linux:
Steg 1: Skapa en värdfil $hostfile med din favoritredigerare
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Där name_of_node(n) helt enkelt är ett DNS-namn eller en IP-adress för arbetsnoden.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Parallell träning över flera beräkningsnoder med Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel träning med 1-bitars SGD
CNTK implementerar 1-bitars SGD-tekniken [1]. Den här tekniken gör det möjligt att distribuera varje minibatch över K arbetare. De resulterande partiella toningarna byts sedan ut och aggregeras efter varje minibatch. "1 bit" avser en teknik som utvecklats hos Microsoft för att minska mängden data som utbyts för varje toningsvärde till en enda bit.
5.1 Algoritmen "1-bitars SGD"
Direkt utbyte av partiella toningar efter varje minibatch kräver oöverkomlig kommunikationsbandbredd. För att åtgärda detta kvantifierar 1-bitars SGD aggressivt varje toningsvärde... till en enda bit (!) per värde. Praktiskt taget innebär detta att stora toningsvärden klipps ut, medan små värden är artificiellt uppblåsta. Otroligt nog skadar detta inte konvergensen om, och bara om, ett trick används.
Tricket är att för varje minibatch jämför algoritmen kvantiserade toningar (som utbyts mellan arbetare) med de ursprungliga toningsvärdena (som skulle bytas ut). Skillnaden mellan de två ( kvantiseringsfelet) beräknas och sparas som residual. Den här residualen läggs sedan till i nästa minibatch.
Trots den aggressiva kvantiseringen utbyts därför varje toningsvärde så småningom med full noggrannhet. bara vid en fördröjning. Experiment visar att så länge den här modellen kombineras med en varm start (en seed-modell som tränats på en liten delmängd av träningsdata utan parallellisering), har den här tekniken visat sig leda till ingen eller mycket liten förlust av noggrannhet, samtidigt som en hastighet inte är för långt från linjär (den begränsande faktorn är att GPU:er blir ineffektiva vid beräkning på för små delpartier).
För maximal effektivitet bör tekniken kombineras med automatisk minibatchskalning, där tränaren då och då försöker öka minibatchstorleken. Vid utvärdering av en liten delmängd av den kommande dataepoken väljer tränaren den största minibatchstorleken som inte skadar konvergensen. Här är det praktiskt att CNTK anger inlärningshastigheten och momentum-hyperparametrar på ett agnostiskt sätt i minibatchstorlek.
5.2 Använda 1-bitars SGD i BrainScript
1-bitars SGD har ingen annan parameter än att aktivera den och efter vilken epok den ska påbörjas. Dessutom ska automatisk minibatchskalning aktiveras. Dessa konfigureras genom att lägga till följande parametrar i SGD-blocket:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Observera att Data-Parallel SGD också kan användas utan 1-bitars kvantisering. Men i typiska scenarier, särskilt scenarier där varje modellparameter endast tillämpas en gång som för en feed-forward DNN, kommer detta inte att vara effektivt på grund av behov av hög kommunikationsbandbredd.
Avsnitt 2.2.3 nedan visar resultatet av 1-bitars SGD för en talaktivitet, jämfört med metoden Block-Momentum SGD som beskrivs härnäst. Båda metoderna har ingen eller nästan ingen förlust av noggrannhet vid nästan linjär hastighet.
5.3 Använda 1-bitars SGD i Python
Om du vill använda dataparallell SGD i Python, om du vill med 1-bitars SGD, måste användaren skapa och skicka en distribuerad elev till utbildaren:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Om du ändrar num_quantization_bits till 32 när distributed_learner skapas används icke-kvantiserad Data-Parallel SGD. Det finns inget behov av varm start i det här fallet.
6 Block-Momentum SGD
Block-Momentum SGD är implementeringen av "blockwise model update and filtering" eller BMUF, algoritm, short Block Momentum [2].
6.1 Block-Momentum SGD-algoritmen
Följande bild sammanfattar proceduren i Block-Momentum-algoritmen.

6.2 Konfigurera Block-Momentum SGD i BrainScript
Om du vill använda Block-Momentum SGD måste du ha ett underblock med namnet BlockMomentumSGD i SGD blocket med följande alternativ:
syncPeriod. Detta liknarsyncPeriodiModelAveragingSGD, som anger hur ofta en modellsynkronisering utförs. Standardvärdet förBlockMomentumSGDär 120 000.resetSGDMomentum. Det innebär att efter varje synkroniseringspunkt anges den utjämnade toning som används i lokal SGD som 0. Standardvärdet för den här variabeln är sant.useNesterovMomentum. Det innebär att momentumuppdateringen i Nesterov-stil tillämpas på blocknivå. Mer information finns i [2]. Standardvärdet för den här variabeln är sant.
Blockdynamiken och blockinlärningshastigheten anges vanligtvis automatiskt enligt det antal arbetstagare som används, dvs.
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
Vår erfarenhet visar att dessa inställningar ofta ger liknande konvergens som standard-SGD-algoritmen upp till 64 GPU:er, vilket är det största experimentet vi utförde. Du kan också ange dessa parametrar manuellt med hjälp av följande alternativ:
blockMomentumAsTimeConstantanger tidskonstanten för lågpassfiltret i modelluppdatering på blocknivå. Den beräknas som:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRateanger blockinlärningshastigheten.
Följande är ett exempel på Block-Momentum SGD-konfigurationsavsnitt:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Använda Block-Momentum SGD i BrainScript
1. Justera om inlärningsparametrar
För att uppnå liknande dataflöde per arbetare är det nödvändigt att öka antalet prover i en minibatch som är proportionell mot antalet arbetare. Detta kan uppnås genom att
minibatchSizejustera ellernbruttsineachrecurrentiter, beroende på om slumpmässighet i ramläge används.Det finns inget behov av att justera inlärningsfrekvensen (till skillnad från Model-Averaging SGD, se nedan).
Vi rekommenderar att du använder Block-Momentum SGD med en varmstartad modell. När det gäller våra taligenkänningsuppgifter uppnås rimlig konvergens när du börjar från frömodeller som tränats på 24 timmar (8,6 miljoner prover) till 120 timmar (43,2 miljoner prover) data med standard-SGD.
2. ASR-experiment
Vi använde Block-Momentum SGD och Data-Parallel(1-bitars) SGD-algoritmer för att träna DNN:er och LSTM:er på en 2600-timmars taligenkänningsaktivitet och jämförde precisionen för ordigenkänning jämfört med hastighetsfaktorer. Följande tabeller och siffror visar resultatet (*).
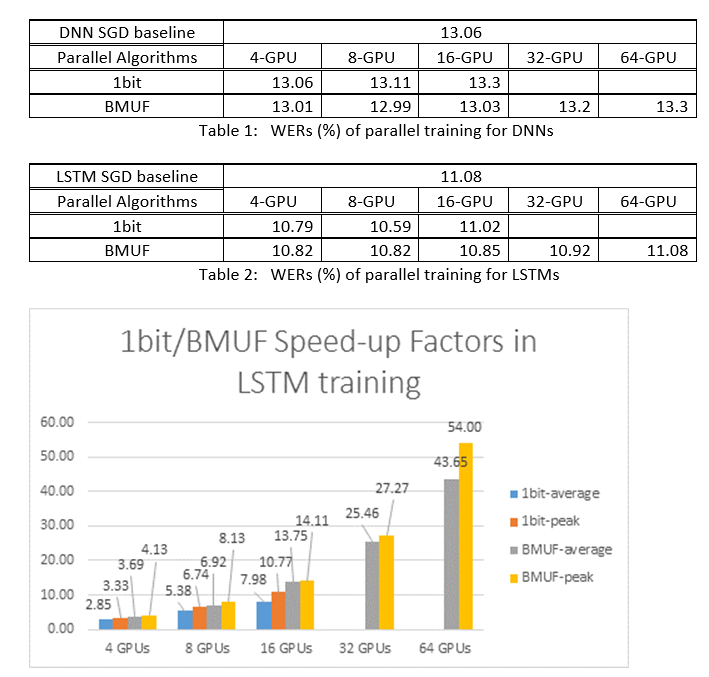
(*): Högsta hastighetsfaktor: för 1-bitars SGD, mätt med den högsta hastighetsfaktorn (jämfört med SGD-baslinjen) som uppnås i en minibatch; För Block Momentum, mätt med den maximala hastighet som uppnås i ett block, Genomsnittlig hastighetsfaktor: den förflutna tiden i SGD-baslinjen dividerat med den observerade förflutna tiden. Dessa två mått introduceras på grund av svarstiden i I/O kan i hög grad påverka den genomsnittliga snabbhetsfaktormätningen, särskilt när synkroniseringen utförs på mini-batchnivå. Samtidigt är den högsta hastighetsfaktorn relativt robust.
3. Varningar
Vi rekommenderar att du anger
resetSGDMomentumsant, annars leder det ofta till skillnader i träningskriteriet. Återställning av SGD-momentum till 0 efter varje modellsynkronisering skär i princip av bidraget från de senaste minibatchesna. Därför rekommenderar vi att du inte använder ett stort SGD-momentum. För ensyncPeriodpå 120 000 observerar vi till exempel en betydande noggrannhetsförlust om det momentum som används för SGD är 0,99. Att minska SGD-momentum till 0,9, 0,5 eller till och med inaktivera det helt och hållet ger liknande noggrannhet som den som kan uppnås av standard-SGD-algoritmen.Block-Momentum SGD fördröjer och distribuerar modelluppdateringar från ett block över efterföljande block. Därför är det nödvändigt att se till att modellsynkroniseringar utförs tillräckligt ofta i träningen. En snabbkontroll är att använda
blockMomentumAsTimeConstant. Vi rekommenderar att antalet unika träningsexempel,N, uppfyller följande ekvation:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
Uppskattningen härrör från följande fakta: (1) Block Momentum anges ofta som (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Använda Block-Momentum i Python
För att aktivera Block-Momentum i Python, på samma sätt som med 1-bitars SGD, måste användaren skapa och skicka en block momentum distribuerad elev till tränaren:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Ett fullt fungerande exempel finns i ConvNet-exemplet.
7 Model-Averaging SGD
Model-Averaging SGD är en implementering av modellens genomsnittsalgoritm som beskrivs i [3,4] utan att använda naturlig toning. Tanken här är att varje arbetare ska kunna bearbeta en delmängd data, men medelvärdet av modellparametrarna från varje arbetare efter en angiven period.
Model-Averaging SGD konvergerar vanligtvis långsammare och till ett sämre optimalt, jämfört med 1-bitars SGD och Block-Momentum SGD, så det rekommenderas inte längre.
Om du vill använda Model-Averaging SGD måste du ha ett underblock med namnet ModelAveragingSGD i SGD blocket med följande alternativ:
syncPeriodanger antalet exempel som varje arbetare behöver bearbeta innan ett modellgenomsnitt utförs. Standardvärdet är 40 000.
7.1 Använda Model-Averaging SGD i BrainScript
För att göra Model-Averaging SGD maximalt effektivt och effektivt måste användarna justera vissa hyperparametrar:
minibatchSizeellernbruttsineachrecurrentiter. Anta attnarbetare deltar i Model-Averaging SGD-konfigurationen. Den aktuella distribuerade läsimplementeringen läser in1/n-th av minibatchen i varje arbetare. För att säkerställa att varje arbetare producerar samma dataflöde som standard-SGD är det därför nödvändigt att förstora minibatchstorlekenn-fold. För modeller som tränas med randomisering i ramläge kan detta uppnås genom att förstorasminibatchSizemed tiden. För modeller tränasnmed slumpmässighet i sekvensläge, till exempel RNN, måste vissa läsare i stället ökanbruttsineachrecurrentiternmed .learningRatesPerSample. Vår erfarenhet visar att för att få liknande konvergens som standard-SGD, är det nödvändigt att öka gångernalearningRatesPerSamplen. En förklaring finns i [2]. Eftersom inlärningstakten ökar behövs en extra omsorg för att se till att utbildningen inte avviker - och detta är i själva verket den viktigaste förbehållet Model-Averaging SGD. Du kan användaAutoAdjustinställningarna för att läsa in den tidigare bästa modellen igen om ett ökat träningskriterium observeras.varm start. Det konstateras att Model-Averaging SGD vanligtvis konvergerar bättre om den startas från en startmodell som tränas av standard-SGD-algoritmen (utan parallellisering). När det gäller våra taligenkänningsuppgifter uppnås rimlig konvergens när du börjar från frömodeller som tränats på 24 timmar (8,6 miljoner prover) till 120 timmar (43,2 miljoner prover) data med standard-SGD.
Följande är ett exempel på konfigurationsavsnittet ModelAveragingSGD :
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Använda Model-Averaging SGD i Python
Arbetet pågår med detta.
8 Data-Parallel träning med parameterserver
Parameterservern är ett vanligt ramverk inom distribuerad maskininlärning [5][6][7]. Den viktigaste fördelen med den är den asynkrona parallella utbildningen med många arbetare. Den introducerar parameterservern som ett distribuerat modellarkiv. I stället för att direkt utnyttja AllReduce-primitiver för att synkronisera parameteruppdateringar mellan arbetare, ger parameterserverramverket användare gränssnitt som "Lägg till" och "Hämta" för att låta lokala arbetare uppdatera och hämta globala parametrar från parameterservern. På så sätt behöver lokala arbetare inte vänta på varandra under utbildningsprocessen, vilket sparar mycket tid, särskilt när arbetsantalet är stort.
Eftersom parameterservrar är ett distribuerat ramverk som lagrar modellparametrar kan arbetare bara hämta de parametrar de behöver under mini-batch-träningsprocessen, vilket ger mycket god flexibilitet i designen av distribuerad träningsmetod och förbättrar även effektiviteten när de genomför träning med glesa modelluppdateringar. I den här versionen fokuserar vi på den asynkrona parallella träningen först. Senare ger vi mer introduktion till hur du använder parameterserverramverket för effektiv modellträning med glesa uppdateringar.
8.1 Använda Data-Parallel ASGD
- Om du vill använda parameterservrar för Asynkron SGD (abbr. som ASGD) bör du skapa CNTK med Multiverso som stöds, Multiverso är ett allmänt parameterserverramverk för distribuerad maskininlärningsuppgift som utvecklats av Microsoft Research Asia-teamet.
Clone Code: Klona koden under rotmappen för CNTK med hjälp av:
git submodule update --init Source/Multiverso
Linux: Skapa med--asgd=yesi konfigurationsprocessen.Windows: Lägg tillCNTK_ENABLE_ASGDi systemmiljön och ange värdet tilltrue
- varm start. I vissa fall är det bättre att ha den asynkrona modellträningen igång från en seed-modell (som tränas av standard-SGD-algoritmen). I någon mening ger Asynkron SGD mer brus för utbildningen på grund av fördröjda uppdateringar från asynkronitet bland arbetare. Vissa modeller är mycket känsliga för sådant brus i början, vilket kan leda till skillnader i modellträning. Under sådana omständigheter behövs en varm start .
8.2 Konfigurera Data-Parallel ASGD i BrainScript
Om du vill använda Data-Parallel ASGD i CNTK måste du ha ett underblock för DataParallelASGD i SGD-blocket med följande alternativ
-
syncPeriodPerWorkers. Den anger antalet exempel som varje arbetare behöver bearbeta innan de kommunicerar med parameterservrarna. Standardvärdet är 256. Det rekommenderas som storlek på minibatch. Det är uppenbart att frekvent synkronisering leder till betydande höga kommunikationskostnader. I vårt test är det inte nödvändigt att ange värdet till 1 i de flesta fall.
-
usePipeline. Den anger om du aktiverar pipelinen för modellhämtning och lokal beräkning. Om du aktiverar pipelinen ökar det totala dataflödet för träning avsevärt eftersom det döljer en del av eller hela kommunikationskostnaden. Ibland kan det dock sakta ned konvergeringshastigheten eftersom mer fördröjning kommer att införas genom att lägga till pipeline. Sammantaget sparas klocktiden i de flesta fall med pipeline.
-
AdjustLearningRateAtBeginning. Enligt den nyligen publicerade artikeln [5] är ASGD för träning mindre stabilt, och det krävdes att man använde mycket mindre inlärningshastighet för att undvika tillfälliga explosioner av träningsförlusten, och därför blir inlärningsprocessen mindre effektiv. Vi har dock upptäckt att det inte krävs någon lägre inlärningsfrekvens för alla uppgifter. Och för de uppgifter som är känsliga i början startar vi utbildningen med liten inlärningstakt och utvidgar den gradvis i början av träningsprocessen tills den når den ursprungliga inlärningshastigheten som används i normal SGD. På så sätt matchar den slutliga noggrannheten SGD medan asgd-hastigheten är. Därför tillhandahåller vi det här alternativet för ASGD-användare att utnyttja det här tricket. Det är ett underblock i DataParallelASGD med två parametrar: adjustCoefficient och adjustNBMiniBatch. Logiken är att inlärningshastigheten utgår från adjustCoefficient för SGD-startinlärningshastigheten och ökar med adjustCoefficient för SGD-startinlärningshastigheten för varje adjustNBMiniBatch-minibatch .
Följande är ett exempel på konfigurationsavsnittet DataParallelASGD :
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Konfigurera Data-Parallel ASGD i Python
Arbetet pågår med detta.
8.4 Experiment
Följande bild visar experimenten för att testa ASGD med CIFAR-10-datamängden. Modellen som används i det här experimentet är ett 20-lagers ResNet. Den asynkrona algoritmen minskar kostnaden för att vänta på alla arbetsnoder. ASGD är i det här fallet klart snabbare än synkrona algoritmer, till exempel MA och SSGD. *I experimenten synkroniserar alla parallella lägen parametrarna varje iteration (mini-batch-uppdatering). Och för SSGD använde vi 32-bitars parameteruppdateringar. Asynkron algoritm får betydande fördelar när det gäller träningsdataflöde mätt med exempelbearbetningshastigheten, särskilt när antalet arbetsnoder går upp till 16.
 Bild 2.4 Hastigheten för olika träningsmetoder
Bild 2.4 Hastigheten för olika träningsmetoder
Referenser
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li och Dong Yu, "1-bitars stochastic gradient descent and its application to data-parallel distributed training of speech DNNs", i Proceedings of Interspeech, 2014.
[2] K. Chen och Q. Huo, "Scalable training of deep learning machines by incremental block training with intra-block parallel optimization and blockwise model-update filtering", in Proceedings of ICASSP, 2016.
[3] M. Zinkevich, M. Weimer, L. Li och A. J. Smola, "Parallelized stochastic gradient descent", in Proceedings of Advances in NIPS, 2010, pp. 2595–2603.
[4] D. Povey, X. Zhang och S. Khudanpur, "Parallel training of DNNs with natural gradient and parameter averaging", in Proceedings of the International Conference on Learning Representations, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Synchronous SGD. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior et al. Storskaliga distribuerade djupa nätverk. I Framsteg i neurala informationsbearbetningssystem, sid. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen och Alexander Smola. "Parameterserver för distribuerad maskininlärning." I Big Learning NIPS Workshop, vol. 6, s. 2. 2013.